 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Text Representation Learning via Instruction-Tuning for Zero-Shot Dense Retrieval
Sep 24, 2024Dense retrieval systems are commonly used for information retrieval (IR). They rely on learning text representations through an encoder and usually require supervised modeling via labelled data which can be costly to obtain or simply unavailable. In this study, we introduce a novel unsupervised text representation learning technique via instruction-tuning the pre-trained encoder-decoder large language models (LLM) under the dual-encoder retrieval framework. We demonstrate the corpus representation can be augmented by the representations of relevant synthetic queries generated by the instruct-tuned LLM founded on the Rao-Blackwell theorem. Furthermore, we effectively align the query and corpus text representation with self-instructed-tuning. Specifically, we first prompt an open-box pre-trained LLM to follow defined instructions (i.e. question generation and keyword summarization) to generate synthetic queries. Next, we fine-tune the pre-trained LLM with defined instructions and the generated queries that passed quality check. Finally, we generate synthetic queries with the instruction-tuned LLM for each corpora and represent each corpora by weighted averaging the synthetic queries and original corpora embeddings. We evaluate our proposed method under low-resource settings on three English and one German retrieval datasets measuring NDCG@10, MRR@100, Recall@100. We significantly improve the average zero-shot retrieval performance on all metrics, increasing open-box FLAN-T5 model variations by [3.34%, 3.50%] in absolute and exceeding three competitive dense retrievers (i.e. mDPR, T-Systems, mBART-Large), with model of size at least 38% smaller, by 1.96%, 4.62%, 9.52% absolute on NDCG@10.
Efficient Semi-Supervised Learning for Natural Language Understanding by Optimizing Diversity
Oct 09, 2019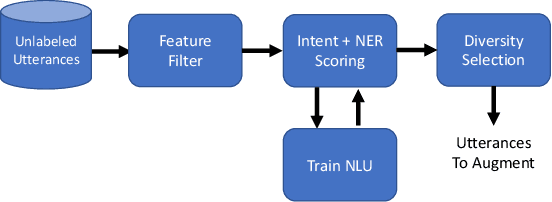
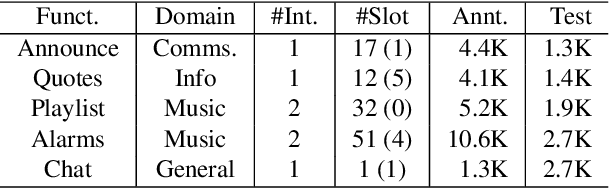
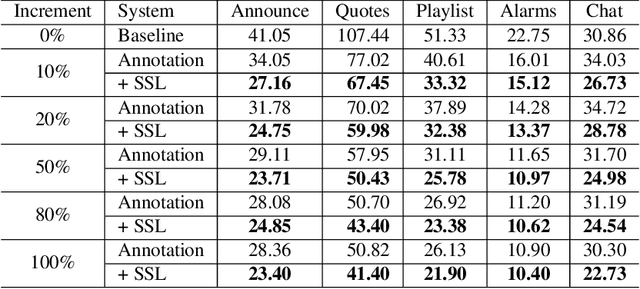
Expanding new functionalities efficiently is an ongoing challenge for single-turn task-oriented dialogue systems. In this work, we explore functionality-specific semi-supervised learning via self-training. We consider methods that augment training data automatically from unlabeled data sets in a functionality-targeted manner. In addition, we examine multiple techniques for efficient selection of augmented utterances to reduce training time and increase diversity. First, we consider paraphrase detection methods that attempt to find utterance variants of labeled training data with good coverage. Second, we explore sub-modular optimization based on n-grams features for utterance selection. Experiments show that functionality-specific self-training is very effective for improving system performance. In addition, methods optimizing diversity can reduce training data in many cases to 50% with little impact on performance.
Consistent Alignment of Word Embedding Models
Feb 24, 2017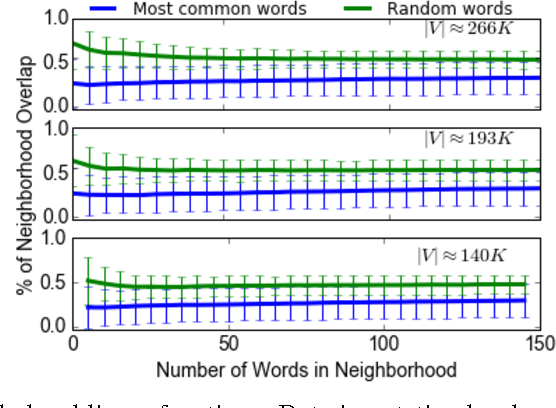
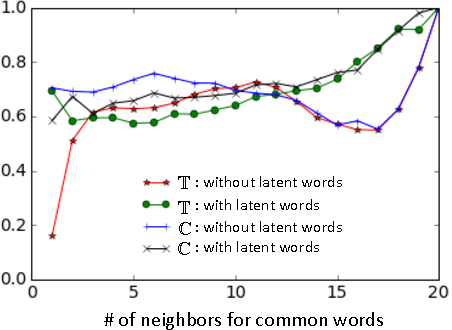
Word embedding models offer continuous vector representations that can capture rich contextual semantics based on their word co-occurrence patterns. While these word vectors can provide very effective features used in many NLP tasks such as clustering similar words and inferring learning relationships, many challenges and open research questions remain. In this paper, we propose a solution that aligns variations of the same model (or different models) in a joint low-dimensional latent space leveraging carefully generated synthetic data points. This generative process is inspired by the observation that a variety of linguistic relationships is captured by simple linear operations in embedded space. We demonstrate that our approach can lead to substantial improvements in recovering embeddings of local neighborhoods.