 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashHead: Efficient Drop-In Replacement for the Classification Head in Language Model Inference
Mar 15, 2026Language models are increasingly adopting smaller architectures optimized for consumer devices. In this setting, inference efficiency is the primary constraint. Meanwhile, vocabulary sizes continue to grow rapidly, making the classification head a critical bottleneck that accounts for up to 60\% of model parameters, and 50\% of inference compute. We introduce FlashHead, the first efficient drop-in replacement for the dense classification head that is training-free and hardware-friendly. FlashHead builds on principles from information retrieval, reframing that computation at the output head as a retrieval problem rather than a dense classification over the full vocabulary. FlashHead introduces four key innovations: (1) a balanced clustering scheme that structures vocabulary partitions into compact hardware-efficient tensors, (2) extending multiprobe retrieval to language model heads, enabling thousands of clusters to be scored in parallel, (3) a novel inference-time sampling mechanism that extends retrieval beyond top tokens, enabling probabilistic sampling across the full vocabulary, and (4) selective quantization, enabling effective low-bit computation in the head. Experiments on Llama-3.2, Gemma-3, and Qwen-3 show that FlashHead delivers model-level inference speedups of up to \textbf{1.75x} which maintaining output accuracy compared to the original head. By overcoming the classification head bottleneck, FlashHead establishes a new benchmark for efficient inference and removes a key barrier to developing smaller, capable models for consumer hardware.
DACS: Domain Adaptation via Cross-domain Mixed Sampling
Jul 17, 2020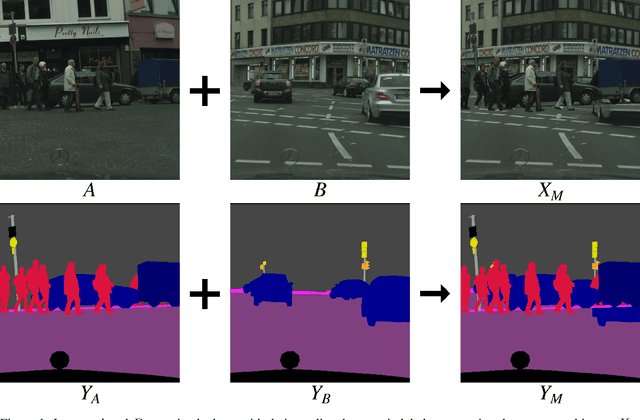
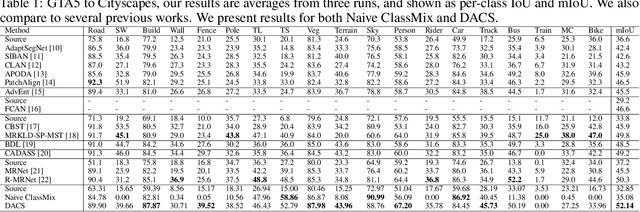
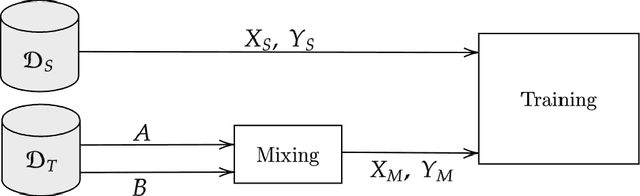
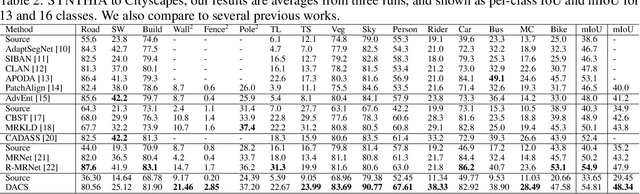
Semantic segmentation models based on convolutional neural networks have recently displayed remarkable performance for a multitude of applications. However, these models typically do not generalize well when applied on new domains, especially when going from synthetic to real data. Unsupervised domain adaptation (UDA) attempts to train on labelled data from one domain (source domain), and simultaneously learn from unlabelled data in the domain of interest (target domain). Existing methods have seen success by training on pseudo-labels for these unlabelled images. Multiple techniques have been proposed to mitigate low-quality pseudo-labels arising from the domain shift, with varying degrees of success. We propose DACS: Domain Adaptation via Cross-domain mixed Sampling, which mixes images from the two domains along with the corresponding labels. These mixed samples are then trained on, in addition to the labelled data itself. We demonstrate the effectiveness of our solution by achieving state-of-the-art results for two common synthetic-to-real semantic segmentation benchmarks for UDA.
ClassMix: Segmentation-Based Data Augmentation for Semi-Supervised Learning
Jul 15, 2020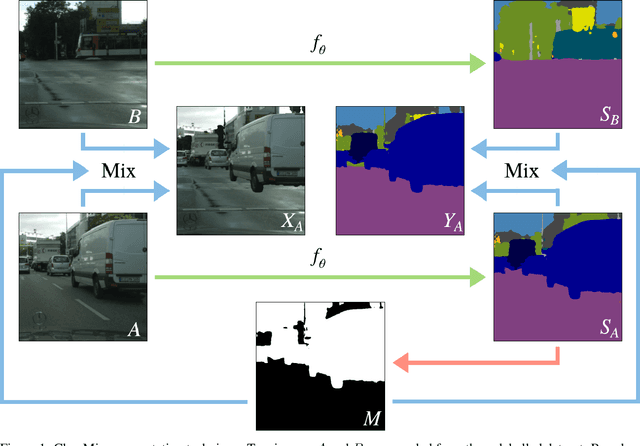
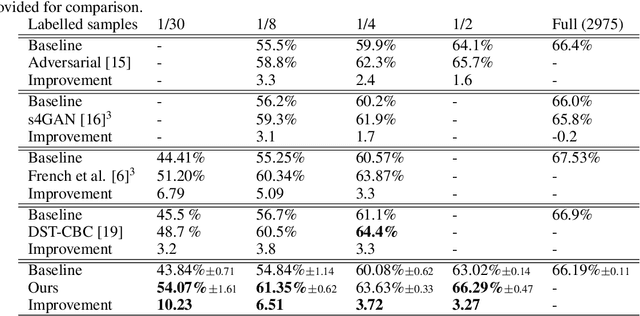

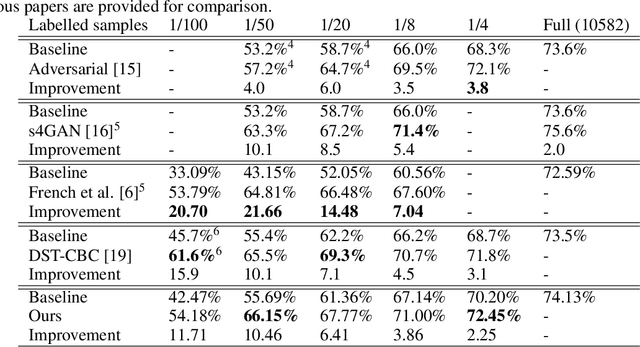
The state of the art in semantic segmentation is steadily increasing in performance, resulting in more precise and reliable segmentations in many different applications. However, progress is limited by the cost of generating labels for training, which sometimes requires hours of manual labor for a single image. Because of this, semi-supervised methods have been applied to this task, with varying degrees of success. A key challenge is that common augmentations used in semi-supervised classification are less effective for semantic segmentation. We propose a novel data augmentation mechanism called ClassMix, which generates augmentations by mixing unlabelled samples, by leveraging on the network's predictions for respecting object boundaries. We evaluate this augmentation technique on two common semi-supervised semantic segmentation benchmarks, showing that it attains state-of-the-art results. Lastly, we also provide extensive ablation studies comparing different design decisions and training regimes.