 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgecoDrawAgents: A Multi-Agent Dialogue Framework for Compositional Image Generation
Mar 13, 2026Text-to-image generation has advanced rapidly, but existing models still struggle with faithfully composing multiple objects and preserving their attributes in complex scenes. We propose coDrawAgents, an interactive multi-agent dialogue framework with four specialized agents: Interpreter, Planner, Checker, and Painter that collaborate to improve compositional generation. The Interpreter adaptively decides between a direct text-to-image pathway and a layout-aware multi-agent process. In the layout-aware mode, it parses the prompt into attribute-rich object descriptors, ranks them by semantic salience, and groups objects with the same semantic priority level for joint generation. Guided by the Interpreter, the Planner adopts a divide-and-conquer strategy, incrementally proposing layouts for objects with the same semantic priority level while grounding decisions in the evolving visual context of the canvas. The Checker introduces an explicit error-correction mechanism by validating spatial consistency and attribute alignment, and refining layouts before they are rendered. Finally, the Painter synthesizes the image step by step, incorporating newly planned objects into the canvas to provide richer context for subsequent iterations. Together, these agents address three key challenges: reducing layout complexity, grounding planning in visual context, and enabling explicit error correction. Extensive experiments on benchmarks GenEval and DPG-Bench demonstrate that coDrawAgents substantially improves text-image alignment, spatial accuracy, and attribute binding compared to existing methods.
Enhanced Mixtures of Part Model for Human Pose Estimation
Jan 28, 2015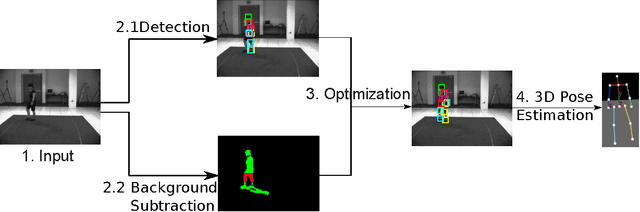
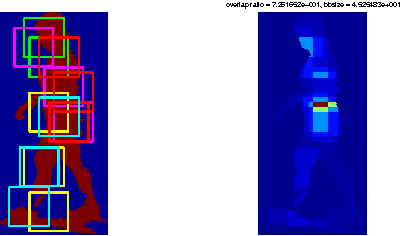
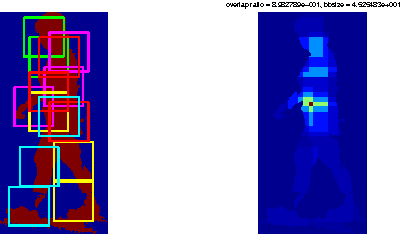

Mixture of parts model has been successfully applied to 2D human pose estimation problem either as explicitly trained body part model or as latent variables for the whole human body model. Mixture of parts model usually utilize tree structure for representing relations between body parts. Tree structures facilitate training and referencing of the model but could not deal with double counting problems, which hinder its applications in 3D pose estimation. While most of work targeted to solve these problems tend to modify the tree models or the optimization target. We incorporate other cues from input features. For example, in surveillance environments, human silhouettes can be extracted relative easily although not flawlessly. In this condition, we can combine extracted human blobs with histogram of gradient feature, which is commonly used in mixture of parts model for training body part templates. The method can be easily extend to other candidate features under our generalized framework. We show 2D body part detection results on a public available dataset: HumanEva dataset. Furthermore, a 2D to 3D pose estimator is trained with Gaussian process regression model and 2D body part detections from the proposed method is fed to the estimator, thus 3D poses are predictable given new 2D body part detections. We also show results of 3D pose estimation on HumanEva dataset.