 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkill Availability and Presentation Granularity in Large-Language-Model Agents: A Controlled SkillsBench Study
May 29, 2026Skill documents provide procedural knowledge to large-language-model agents at inference time. This article studies whether the presentation granularity of controlled skill knowledge changes downstream task success. The experiment uses a pinned SkillsBench version, a 30-task domain-balanced subset validated by official oracle runs, two reasoning-enabled model configurations, six skill conditions, and five trials per task-condition-model cell. Skill availability is the clearest empirical signal. Relative to no skill, skill conditions increase task-mean pass rate by 26.7 to 36.0 percentage points for GPT-5.5 and by 18.0 to 26.0 percentage points for DeepSeek V4-Flash. The final data contain 1,800 rows, with 900 rows for each model. The task is the inference unit. Five trials are aggregated within each task-condition-model cell before paired contrasts are estimated over 30 tasks. The primary presentation contrasts are smaller and uncertain. Low-abstraction guidance differs from high-abstraction guidance by +0.7 percentage points for GPT-5.5 and -6.7 percentage points for DeepSeek V4-Flash, with both 95% bootstrap confidence intervals crossing zero. Adding one worked example to medium-abstraction guidance differs from the no-example variant by +0.7 and +1.3 percentage points. Mean-reward robustness checks preserve the same substantive conclusion. In this controlled subset, skill availability is associated with higher success than no skill, while the tested presentation-granularity changes yield small, uncertain, and model-dependent effects.
Brain-inspired sparse training enables Transformers and LLMs to perform as fully connected
Jan 31, 2025



This study aims to enlarge our current knowledge on application of brain-inspired network science principles for training artificial neural networks (ANNs) with sparse connectivity. Dynamic sparse training (DST) can reduce the computational demands in ANNs, but faces difficulties to keep peak performance at high sparsity levels. The Cannistraci-Hebb training (CHT) is a brain-inspired method for growing connectivity in DST. CHT leverages a gradient-free, topology-driven link regrowth, which has shown ultra-sparse (1% connectivity or lower) advantage across various tasks compared to fully connected networks. Yet, CHT suffers two main drawbacks: (i) its time complexity is O(Nd^3) - N node network size, d node degree - hence it can apply only to ultra-sparse networks. (ii) it selects top link prediction scores, which is inappropriate for the early training epochs, when the network presents unreliable connections. We propose a GPU-friendly approximation of the CH link predictor, which reduces the computational complexity to O(N^3), enabling a fast implementation of CHT in large-scale models. We introduce the Cannistraci-Hebb training soft rule (CHTs), which adopts a strategy for sampling connections in both link removal and regrowth, balancing the exploration and exploitation of network topology. To improve performance, we integrate CHTs with a sigmoid gradual density decay (CHTss). Empirical results show that, using 1% of connections, CHTs outperforms fully connected networks in MLP on visual classification tasks, compressing some networks to < 30% nodes. Using 5% of the connections, CHTss outperforms fully connected networks in two Transformer-based machine translation tasks. Using 30% of the connections, CHTss achieves superior performance compared to other dynamic sparse training methods in language modeling, and it surpasses the fully connected counterpart in zero-shot evaluations.
EllipsoNet: Deep-learning-enabled optical ellipsometry for complex thin films
Oct 11, 2022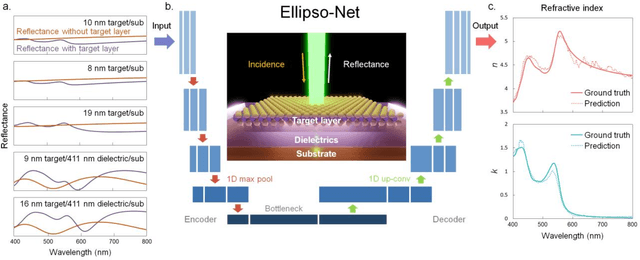
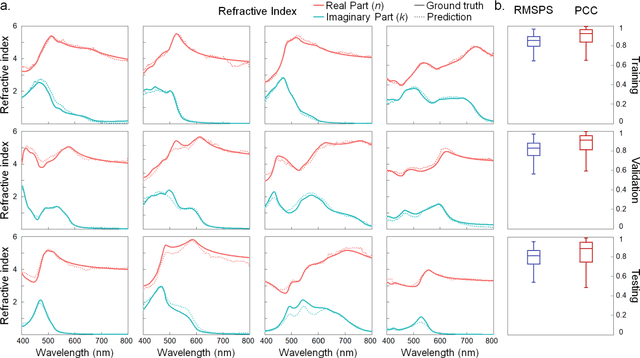
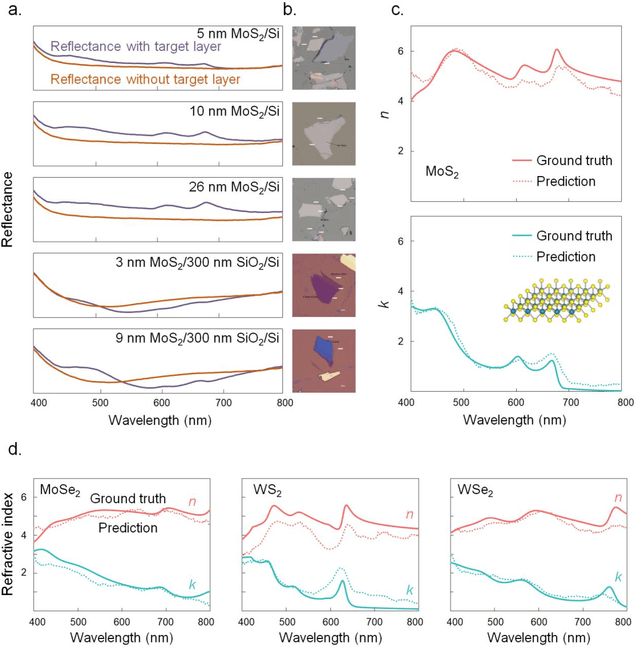
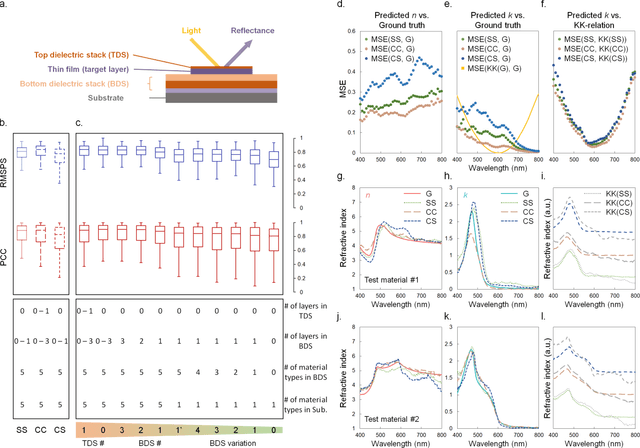
Optical spectroscopy is indispensable for research and development in nanoscience and nanotechnology, microelectronics, energy, and advanced manufacturing. Advanced optical spectroscopy tools often require both specifically designed high-end instrumentation and intricate data analysis techniques. Beyond the common analytical tools, deep learning methods are well suited for interpreting high-dimensional and complicated spectroscopy data. They offer great opportunities to extract subtle and deep information about optical properties of materials with simpler optical setups, which would otherwise require sophisticated instrumentation. In this work, we propose a computational ellipsometry approach based on a conventional tabletop optical microscope and a deep learning model called EllipsoNet. Without any prior knowledge about the multilayer substrates, EllipsoNet can predict the complex refractive indices of thin films on top of these nontrivial substrates from experimentally measured optical reflectance spectra with high accuracies. This task was not feasible previously with traditional reflectometry or ellipsometry methods. Fundamental physical principles, such as the Kramers-Kronig relations, are spontaneously learned by the model without any further training. This approach enables in-operando optical characterization of functional materials within complex photonic structures or optoelectronic devices.
Machine Learning in High Energy Physics Community White Paper
Jul 08, 2018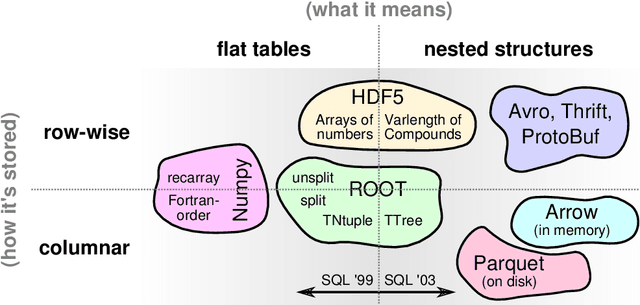
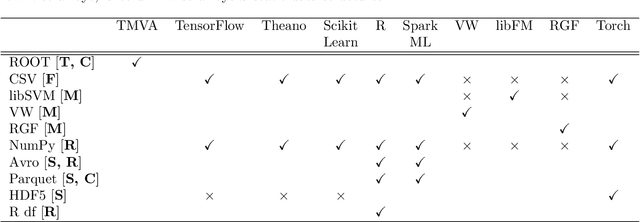

Machine learning is an important research area in particle physics, beginning with applications to high-level physics analysis in the 1990s and 2000s, followed by an explosion of applications in particle and event identification and reconstruction in the 2010s. In this document we discuss promising future research and development areas in machine learning in particle physics with a roadmap for their implementation, software and hardware resource requirements, collaborative initiatives with the data science community, academia and industry, and training the particle physics community in data science. The main objective of the document is to connect and motivate these areas of research and development with the physics drivers of the High-Luminosity Large Hadron Collider and future neutrino experiments and identify the resource needs for their implementation. Additionally we identify areas where collaboration with external communities will be of great benefit.