 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaw of Neural Interaction: Depth-Width Shape, Interaction Efficiency, and Generalization
May 27, 2026The guidance of scaling laws has increased the resource demands of modern large language models (LLMs), yet it remains questionable whether these models utilize resources effectively under a fixed budget. Previous research has proved superposition as a key contributor to loss. By leveraging the Neural Feature Ansatz, we extend superposition from parameter space to gradient space and define it as neural interaction. We find that under a fixed budget, good generalization is usually accompanied by efficient neural interactions, and the model can be placed in an efficient interaction interval by adjusting its depth-width ratio ($R_{D/W}$). In addition, as the budget scales up, the efficient interaction interval of the model remains relatively stable. By comparing existing small scale dense LLMs, we observe that models operating near this interval tend to perform better on the MMLU-Pro benchmark. Our findings reveal that the $R_{D/W}$ influences resource utilization efficiency and thereby affects generalization, providing insights into model shape initialization and the understanding of model generalization mechanisms. Code for Neural Interaction Law is available at: https://anonymous.4open.science/r/Neural_Interaction_Law-D788
Sparsification and Reconstruction from the Perspective of Representation Geometry
May 28, 2025Sparse Autoencoders (SAEs) have emerged as a predominant tool in mechanistic interpretability, aiming to identify interpretable monosemantic features. However, how does sparse encoding organize the representations of activation vector from language models? What is the relationship between this organizational paradigm and feature disentanglement as well as reconstruction performance? To address these questions, we propose the SAEMA, which validates the stratified structure of the representation by observing the variability of the rank of the symmetric semipositive definite (SSPD) matrix corresponding to the modal tensor unfolded along the latent tensor with the level of noise added to the residual stream. To systematically investigate how sparse encoding alters representational structures, we define local and global representations, demonstrating that they amplify inter-feature distinctions by merging similar semantic features and introducing additional dimensionality. Furthermore, we intervene the global representation from an optimization perspective, proving a significant causal relationship between their separability and the reconstruction performance. This study explains the principles of sparsity from the perspective of representational geometry and demonstrates the impact of changes in representational structure on reconstruction performance. Particularly emphasizes the necessity of understanding representations and incorporating representational constraints, providing empirical references for developing new interpretable tools and improving SAEs. The code is available at \hyperlink{https://github.com/wenjie1835/SAERepGeo}{https://github.com/wenjie1835/SAERepGeo}.
A Fast Matrix-Completion-Based Approach for Recommendation Systems
Dec 04, 2019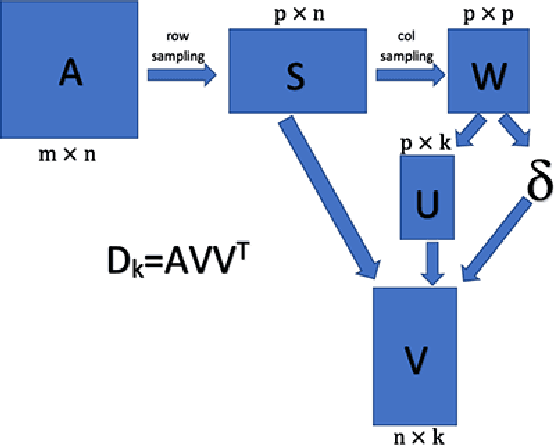
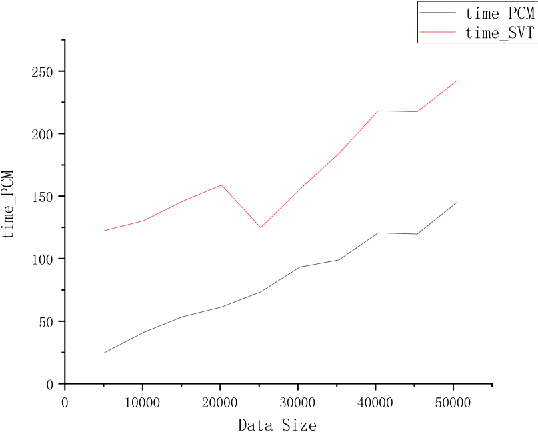
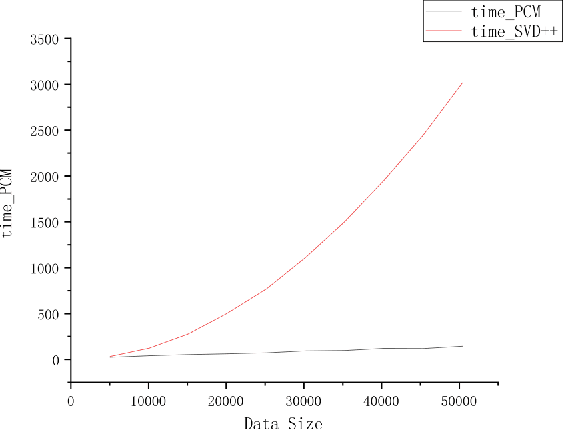
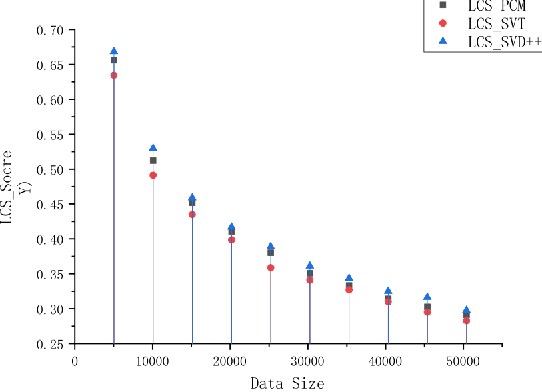
Matrix completion is widely used in machine learning, engineering control, image processing, and recommendation systems. Currently, a popular algorithm for matrix completion is Singular Value Threshold (SVT). In this algorithm, the singular value threshold should be set first. However, in a recommendation system, the dimension of the preference matrix keeps changing. Therefore, it is difficult to directly apply SVT. In addition, what the users of a recommendation system need is a sequence of personalized recommended results rather than the estimation of their scores. According to the above ideas, this paper proposes a novel approach named probability completion model~(PCM). By reducing the data dimension, the transitivity of the similar matrix, and singular value decomposition, this approach quickly obtains a completion matrix with the same probability distribution as the original matrix. The approach greatly reduces the computation time based on the accuracy of the sacrifice part, and can quickly obtain a low-rank similarity matrix with data trend approximation properties. The experimental results show that PCM can quickly generate a complementary matrix with similar data trends as the original matrix. The LCS score and efficiency of PCM are both higher than SVT.