 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRIP sensing matrices construction for sparsifying dictionaries with application to MRI imaging
Jul 30, 2024Practical applications of compressed sensing often restrict the choice of its two main ingredients. They may (i) prescribe using particular redundant dictionaries for certain classes of signals to become sparsely represented, or (ii) dictate specific measurement mechanisms which exploit certain physical principles. On the problem of RIP measurement matrix design in compressed sensing with redundant dictionaries, we give a simple construction to derive sensing matrices whose compositions with a prescribed dictionary have a high probability of the RIP in the $k \log(n/k)$ regime. Our construction thus provides recovery guarantees usually only attainable for sensing matrices from random ensembles with sparsifying orthonormal bases. Moreover, we use the dictionary factorization idea that our construction rests on in the application of magnetic resonance imaging, in which also the sensing matrix is prescribed by quantum mechanical principles. We propose a recovery algorithm based on transforming the acquired measurements such that the compressed sensing theory for RIP embeddings can be utilized to recover wavelet coefficients of the target image, and show its performance on examples from the fastMRI dataset.
Generalization bounds for regression and classification on adaptive covering input domains
Jul 29, 2024

Our main focus is on the generalization bound, which serves as an upper limit for the generalization error. Our analysis delves into regression and classification tasks separately to ensure a thorough examination. We assume the target function is real-valued and Lipschitz continuous for regression tasks. We use the 2-norm and a root-mean-square-error (RMSE) variant to measure the disparities between predictions and actual values. In the case of classification tasks, we treat the target function as a one-hot classifier, representing a piece-wise constant function, and employ 0/1 loss for error measurement. Our analysis underscores the differing sample complexity required to achieve a concentration inequality of generalization bounds, highlighting the variation in learning efficiency for regression and classification tasks. Furthermore, we demonstrate that the generalization bounds for regression and classification functions are inversely proportional to a polynomial of the number of parameters in a network, with the degree depending on the hypothesis class and the network architecture. These findings emphasize the advantages of over-parameterized networks and elucidate the conditions for benign overfitting in such systems.
Representation and decomposition of functions in DAG-DNNs and structural network pruning
Jun 16, 2023The conclusions provided by deep neural networks (DNNs) must be carefully scrutinized to determine whether they are universal or architecture dependent. The term DAG-DNN refers to a graphical representation of a DNN in which the architecture is expressed as a direct-acyclic graph (DAG), on which arcs are associated with functions. The level of a node denotes the maximum number of hops between the input node and the node of interest. In the current study, we demonstrate that DAG-DNNs can be used to derive all functions defined on various sub-architectures of the DNN. We also demonstrate that the functions defined in a DAG-DNN can be derived via a sequence of lower-triangular matrices, each of which provides the transition of functions defined in sub-graphs up to nodes at a specified level. The lifting structure associated with lower-triangular matrices makes it possible to perform the structural pruning of a network in a systematic manner. The fact that decomposition is universally applicable to all DNNs means that network pruning could theoretically be applied to any DNN, regardless of the underlying architecture. We demonstrate that it is possible to obtain the winning ticket (sub-network and initialization) for a weak version of the lottery ticket hypothesis, based on the fact that the sub-network with initialization can achieve training performance on par with that of the original network using the same number of iterations or fewer.
Analysis of function approximation and stability of general DNNs in directed acyclic graphs using un-rectifying analysis
Jun 13, 2022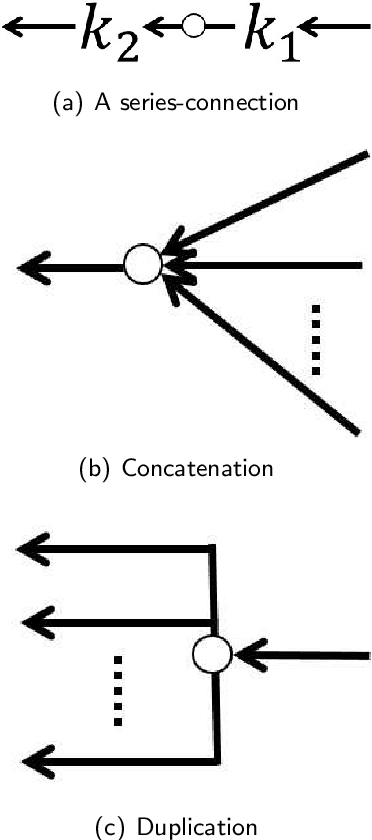
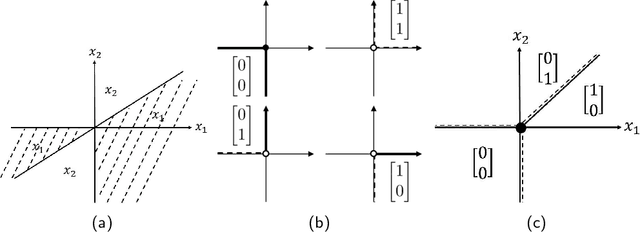
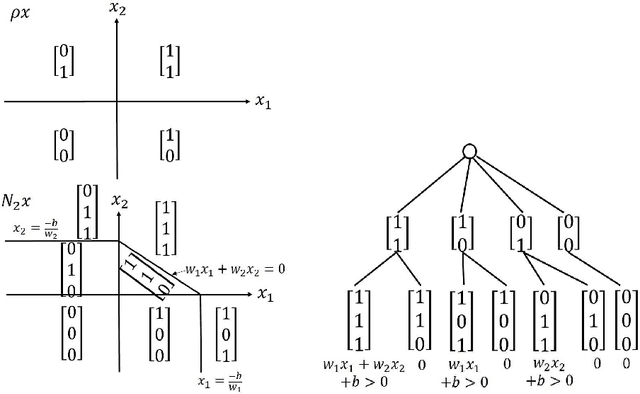
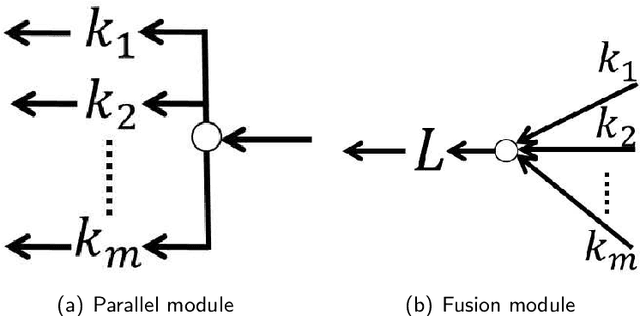
A general lack of understanding pertaining to deep feedforward neural networks (DNNs) can be attributed partly to a lack of tools with which to analyze the composition of non-linear functions, and partly to a lack of mathematical models applicable to the diversity of DNN architectures. In this paper, we made a number of basic assumptions pertaining to activation functions, non-linear transformations, and DNN architectures in order to use the un-rectifying method to analyze DNNs via directed acyclic graphs (DAGs). DNNs that satisfy these assumptions are referred to as general DNNs. Our construction of an analytic graph was based on an axiomatic method in which DAGs are built from the bottom-up through the application of atomic operations to basic elements in accordance with regulatory rules. This approach allows us to derive the properties of general DNNs via mathematical induction. We show that using the proposed approach, some properties hold true for general DNNs can be derived. This analysis advances our understanding of network functions and could promote further theoretical insights if the host of analytical tools for graphs can be leveraged.
Learning DNN networks using un-rectifying ReLU with compressed sensing application
Jan 18, 2021
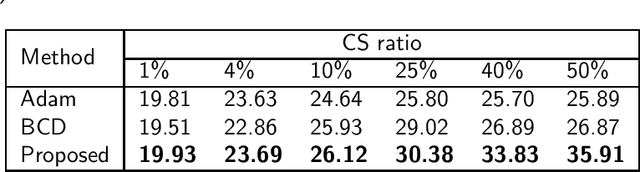
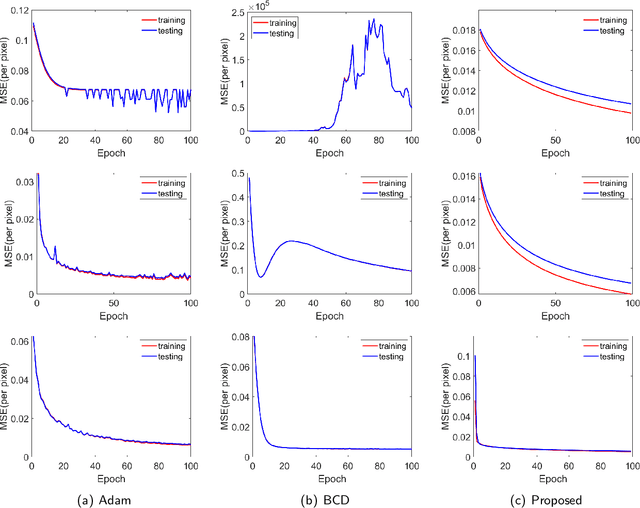
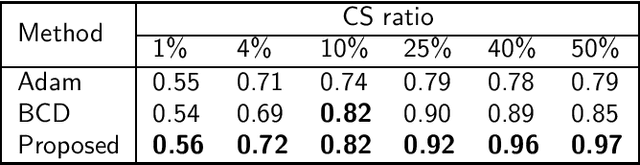
The un-rectifying technique expresses a non-linear point-wise activation function as a data-dependent variable, which means that the activation variable along with its input and output can all be employed in optimization. The ReLU network in this study was un-rectified means that the activation functions could be replaced with data-dependent activation variables in the form of equations and constraints. The discrete nature of activation variables associated with un-rectifying ReLUs allows the reformulation of deep learning problems as problems of combinatorial optimization. However, we demonstrate that the optimal solution to a combinatorial optimization problem can be preserved by relaxing the discrete domains of activation variables to closed intervals. This makes it easier to learn a network using methods developed for real-domain constrained optimization. We also demonstrate that by introducing data-dependent slack variables as constraints, it is possible to optimize a network based on the augmented Lagrangian approach. This means that our method could theoretically achieve global convergence and all limit points are critical points of the learning problem. In experiments, our novel approach to solving the compressed sensing recovery problem achieved state-of-the-art performance when applied to the MNIST database and natural images.
Deep Representation with ReLU Neural Networks
Mar 29, 2019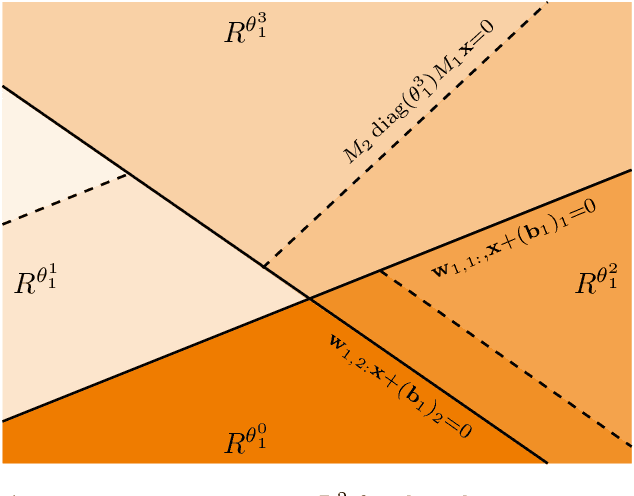
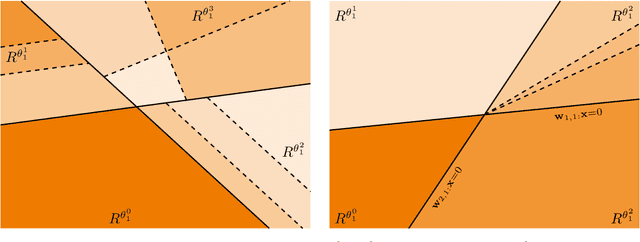
We consider deep feedforward neural networks with rectified linear units from a signal processing perspective. In this view, such representations mark the transition from using a single (data-driven) linear representation to utilizing a large collection of affine linear representations tailored to particular regions of the signal space. This paper provides a precise description of the individual affine linear representations and corresponding domain regions that the (data-driven) neural network associates to each signal of the input space. In particular, we describe atomic decompositions of the representations and, based on estimating their Lipschitz regularity, suggest some conditions that can stabilize learning independent of the network depth. Such an analysis may promote further theoretical insight from both the signal processing and machine learning communities.
Frame-based Sparse Analysis and Synthesis Signal Representations and Parseval K-SVD
Jan 06, 2018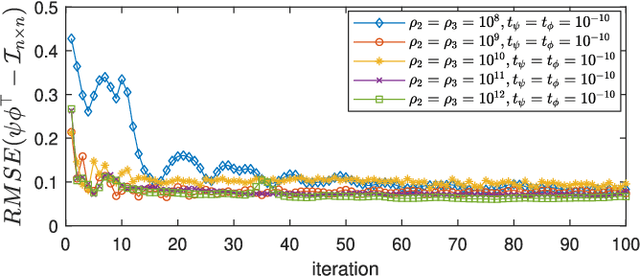

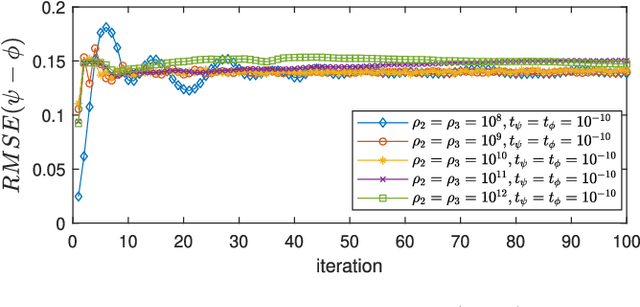
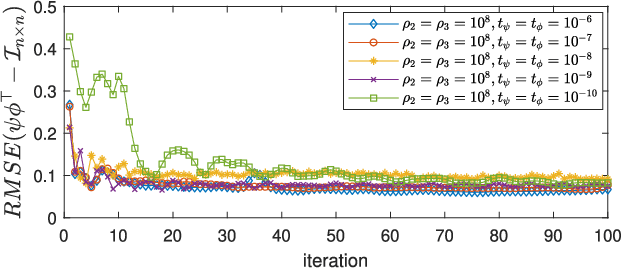
Frames are the foundation of the linear operators used in the decomposition and reconstruction of signals, such as the discrete Fourier transform, Gabor, wavelets, and curvelet transforms. The emergence of sparse representation models has shifted of the emphasis in frame theory toward sparse l1-minimization problems. In this paper, we apply frame theory to the sparse representation of signals in which a synthesis dictionary is used for a frame and an analysis dictionary is used for a dual frame. We sought to formulate a novel dual frame design in which the sparse vector obtained through the decomposition of any signal is also the sparse solution representing signals based on a reconstruction frame. Our findings demonstrate that this type of dual frame cannot be constructed for over-complete frames, thereby precluding the use of any linear analysis operator in driving the sparse synthesis coefficient for signal representation. Nonetheless, the best approximation to the sparse synthesis solution can be derived from the analysis coefficient using the canonical dual frame. In this study, we developed a novel dictionary learning algorithm (called Parseval K-SVD) to learn a tight-frame dictionary. We then leveraged the analysis and synthesis perspectives of signal representation with frames to derive optimization formulations for problems pertaining to image recovery. Our preliminary, results demonstrate that the images recovered using this approach are correlated to the frame bounds of dictionaries, thereby demonstrating the importance of using different dictionaries for different applications.
Sparse Representation of a Blur Kernel for Blind Image Restoration
Dec 14, 2015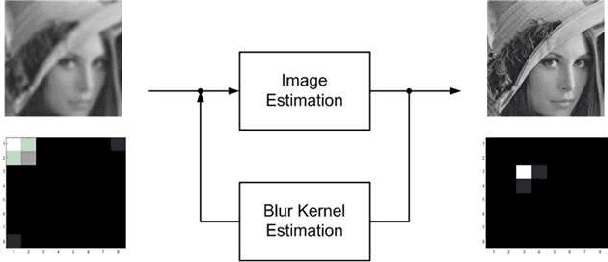
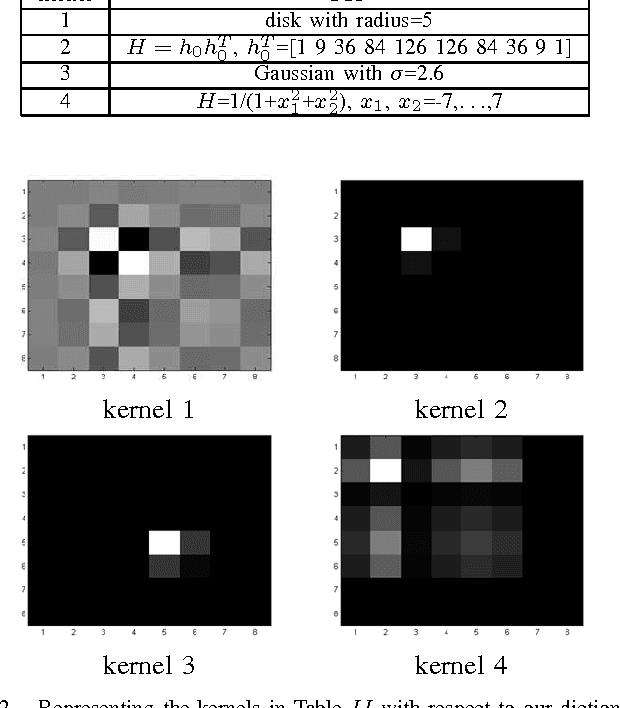

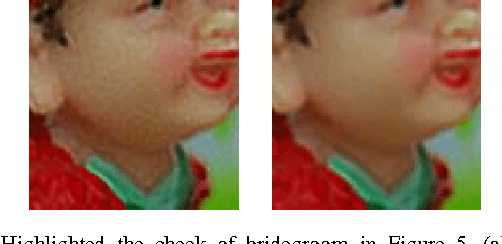
Blind image restoration is a non-convex problem which involves restoration of images from an unknown blur kernel. The factors affecting the performance of this restoration are how much prior information about an image and a blur kernel are provided and what algorithm is used to perform the restoration task. Prior information on images is often employed to restore the sharpness of the edges of an image. By contrast, no consensus is still present regarding what prior information to use in restoring from a blur kernel due to complex image blurring processes. In this paper, we propose modelling of a blur kernel as a sparse linear combinations of basic 2-D patterns. Our approach has a competitive edge over the existing blur kernel modelling methods because our method has the flexibility to customize the dictionary design, which makes it well-adaptive to a variety of applications. As a demonstration, we construct a dictionary formed by basic patterns derived from the Kronecker product of Gaussian sequences. We also compare our results with those derived by other state-of-the-art methods, in terms of peak signal to noise ratio (PSNR).