 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Task Detection and Heterogeneous LLM Speculative Decoding
May 13, 2025Speculative decoding, which combines a draft model with a target model, has emerged as an effective approach to accelerate large language model (LLM) inference. However, existing methods often face a trade-off between the acceptance rate and decoding speed in downstream tasks due to the limited capacity of the draft model, making it difficult to ensure efficiency across diverse tasks. To address this problem, we propose a speculative decoding algorithm tailored for downstream task optimization. It includes an automatic task partitioning and assigning method, which automatically categorizes downstream tasks into different sub-tasks and assigns them to a set of heterogeneous draft models. Each draft model is aligned with the target model using task-specific data, thereby enhancing the consistency of inference results. In addition, our proposed method incorporates an online lightweight prompt classifier to dynamically route prompts to the appropriate draft model. Experimental results demonstrate that the proposed method improves draft accuracy by 6% to 50% over vanilla speculative decoding, while achieving a speedup of 1.10x to 2.64x in LLM inference.
DNNAbacus: Toward Accurate Computational Cost Prediction for Deep Neural Networks
May 24, 2022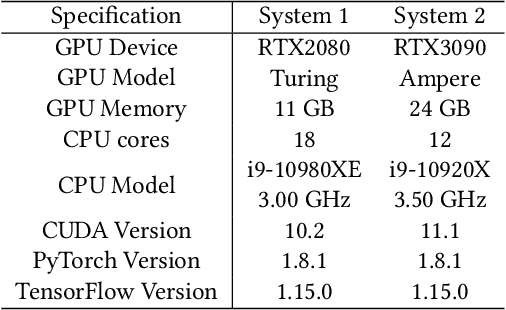
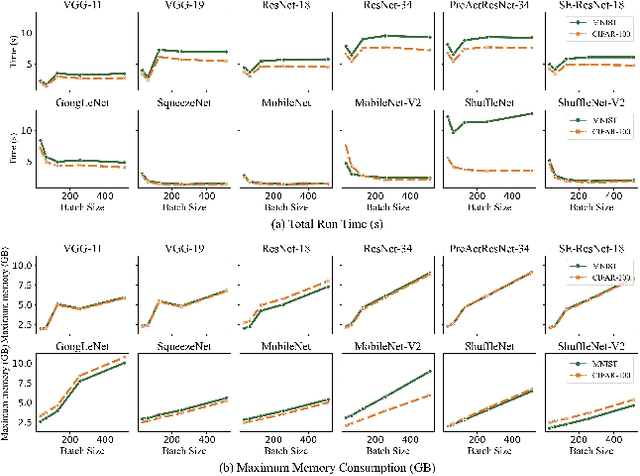
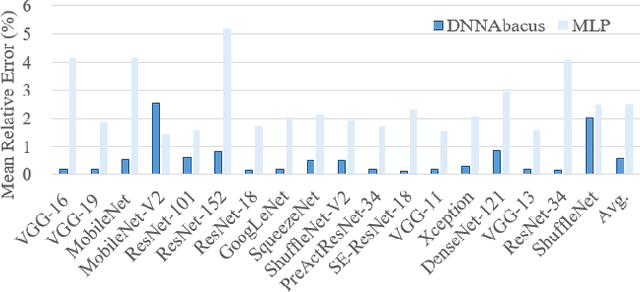
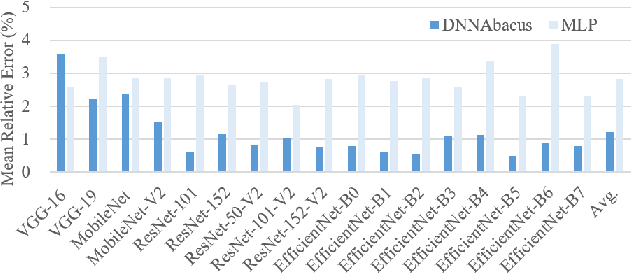
Deep learning is attracting interest across a variety of domains, including natural language processing, speech recognition, and computer vision. However, model training is time-consuming and requires huge computational resources. Existing works on the performance prediction of deep neural networks, which mostly focus on the training time prediction of a few models, rely on analytical models and result in high relative errors. %Optimizing task scheduling and reducing job failures in data centers are essential to improve resource utilization and reduce carbon emissions. This paper investigates the computational resource demands of 29 classical deep neural networks and builds accurate models for predicting computational costs. We first analyze the profiling results of typical networks and demonstrate that the computational resource demands of models with different inputs and hyperparameters are not obvious and intuitive. We then propose a lightweight prediction approach DNNAbacus with a novel network structural matrix for network representation. DNNAbacus can accurately predict both memory and time cost for PyTorch and TensorFlow models, which is also generalized to different hardware architectures and can have zero-shot capability for unseen networks. Our experimental results show that the mean relative error (MRE) is 0.9% with respect to time and 2.8% with respect to memory for 29 classic models, which is much lower than the state-of-the-art works.