 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrokeTimer: Robust Representation Learning for Ischemic Stroke Onset-Time Estimation from Non-contrast CT
Jun 03, 2026Ischemic stroke is a major global disease. Treatment decisions are highly time-sensitive, as eligibility for reperfusion therapies relies on the interval between stroke onset and intervention. However, the true onset time is often uncertain in clinical practice, necessitating imaging-based assessment of tissue age as a surrogate marker. Early ischemic changes on routinely acquired non-contrast CT (NCCT) are often subtle, and real-world clinical datasets exhibit pronounced onset-time class imbalance and center-scanner-related heterogeneity. In this work, we propose StrokeTimer, a fully automated framework for onset-time estimation in acute ischemic stroke. StrokeTimer integrates self-supervised disentanglement learning with energy-guided contrastive learning to capture subtle ischemic patterns while addressing long-tailed data distributions under acquisition variability. Onset time is categorized into three clinically relevant windows: <4.5 h, 4.5-6 h, and >6 h. Experimental results on a large multi-center NCCT dataset from two national cohorts, MR CLEAN Registry and MR CLEAN LATE, show that StrokeTimer achieves a macro AUC of 0.69 and a macro F1-score of 0.57, improving the strongest baseline by nearly 50% (p < 0.005). In this realistic, challenging setting, representative baseline approaches exhibit near-chance macro performance. Model explanations further highlight subtle gray-white matter blurring and hypodense regions consistent with established radiological biomarkers. These findings demonstrate the potential of StrokeTimer to support treatment decision-making in acute ischemic stroke. Code is available at https://github.com/BrainVas/StrokeTimer.
ServeNet: A Deep Neural Network for Web Service Classification
Jun 14, 2018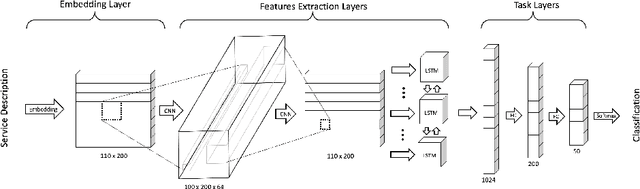
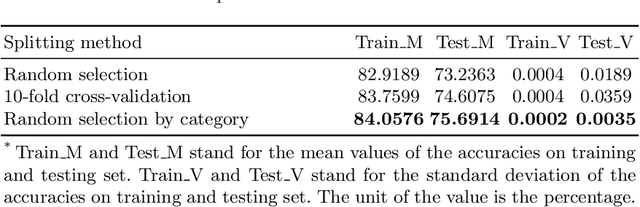
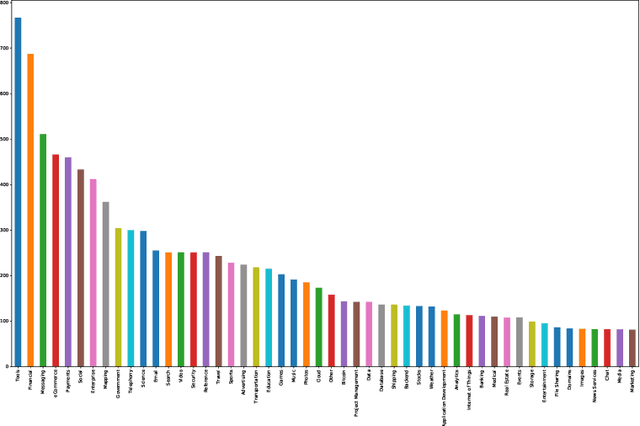
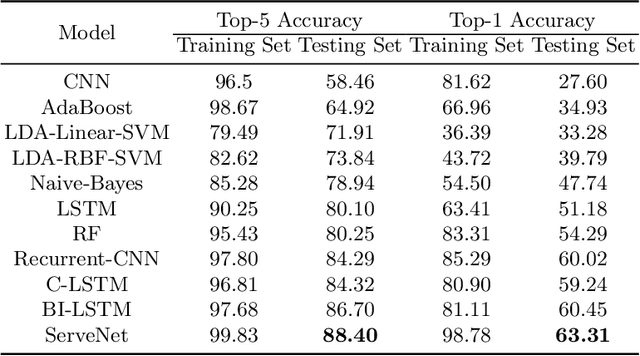
Automated service classification plays a crucial role in service management such as service discovery, selection, and composition. In recent years, machine learning techniques have been used for service classification. However, they can only predict around 10 to 20 service categories due to the quality of feature engineering and the imbalance problem of service dataset. In this paper, we present a deep neural network ServeNet with a novel dataset splitting algorithm to deal with these issues. ServeNet can automatically abstract low-level representation to high-level features, and then predict service classification based on the service datasets produced by the proposed splitting algorithm. To demonstrate the effectiveness of our approach, we conducted a comprehensive experimental study on 10,000 real-world services in 50 categories. The result shows that ServeNet can achieve higher accuracy than other machine learning methods.