 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Multitask Representation Learning for Pathology Biobank Metadata Prediction
Sep 17, 2019
Metadata are general characteristics of the data in a well-curated and condensed format, and have been proven to be useful for decision making, knowledge discovery, and also heterogeneous data organization of biobank. Among all data types in the biobank, pathology is the key component of the biobank and also serves as the gold standard of diagnosis. To maximize the utility of biobank and allow the rapid progress of biomedical science, it is essential to organize the data with well-populated pathology metadata. However, manual annotation of such information is tedious and time-consuming. In the study, we develop a multimodal multitask learning framework to predict four major slide-level metadata of pathology images. The framework learns generalizable representations across tissue slides, pathology reports, and case-level structured data. We demonstrate improved performance across all four tasks with the proposed method compared to a single modal single task baseline on two test sets, one external test set from a distinct data source (TCGA) and one internal held-out test set (TTH). In the test sets, the performance improvements on the averaged area under receiver operating characteristic curve across the four tasks are 16.48% and 9.05% on TCGA and TTH, respectively. Such pathology metadata prediction system may be adopted to mitigate the effort of expert annotation and ultimately accelerate the data-driven research by better utilization of the pathology biobank.
Multimodal Volume-Aware Detection and Segmentation for Brain Metastases Radiosurgery
Aug 15, 2019
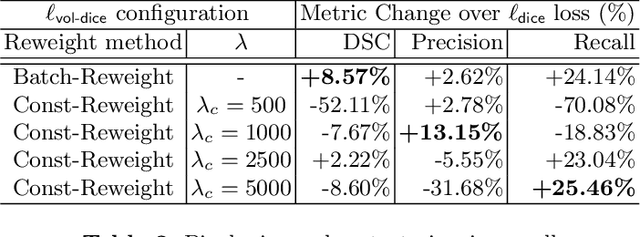
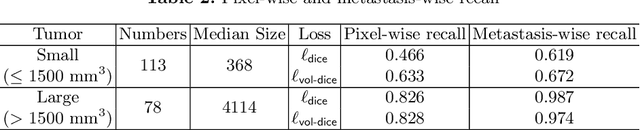
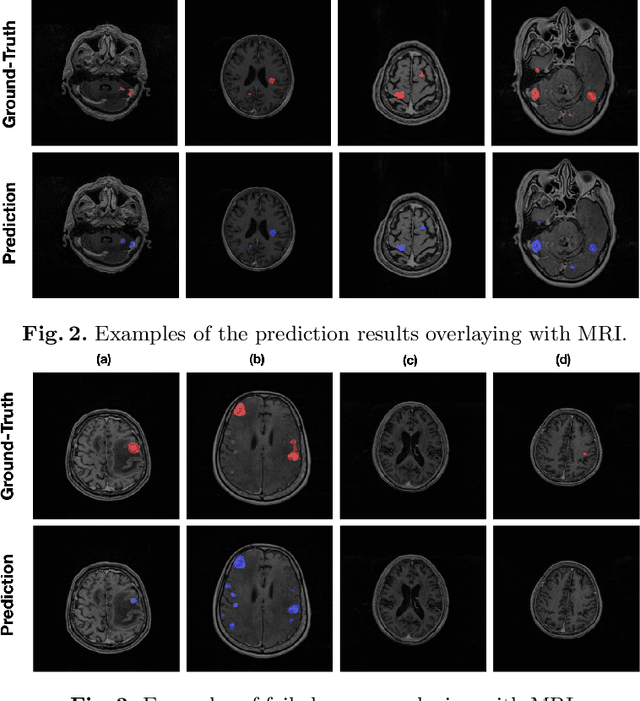
Stereotactic radiosurgery (SRS), which delivers high doses of irradiation in a single or few shots to small targets, has been a standard of care for brain metastases. While very effective, SRS currently requires manually intensive delineation of tumors. In this work, we present a deep learning approach for automated detection and segmentation of brain metastases using multimodal imaging and ensemble neural networks. In order to address small and multiple brain metastases, we further propose a volume-aware Dice loss which optimizes model performance using the information of lesion size. This work surpasses current benchmark levels and demonstrates a reliable AI-assisted system for SRS treatment planning for multiple brain metastases.
Publicly Available Clinical BERT Embeddings
Apr 29, 2019
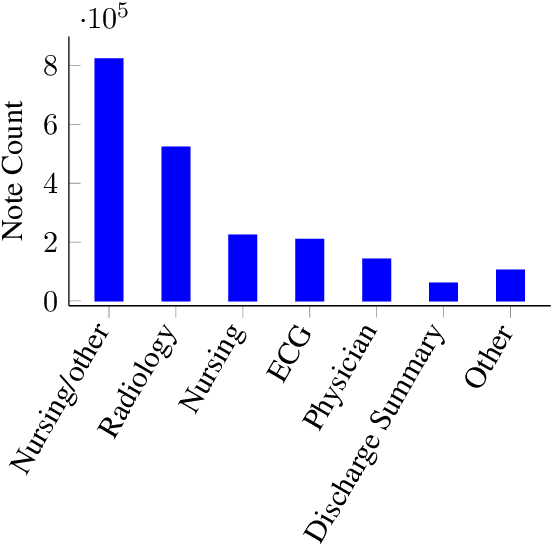
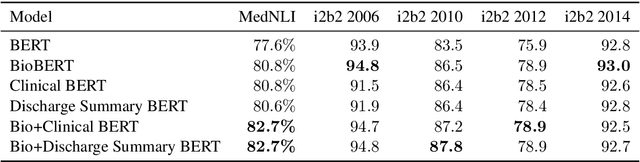
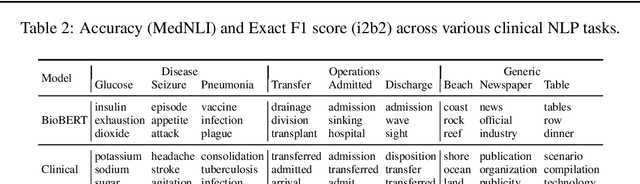
Contextual word embedding models such as ELMo (Peters et al., 2018) and BERT (Devlin et al., 2018) have dramatically improved performance for many natural language processing (NLP) tasks in recent months. However, these models have been minimally explored on specialty corpora, such as clinical text; moreover, in the clinical domain, no publicly-available pre-trained BERT models yet exist. In this work, we address this need by exploring and releasing BERT models for clinical text: one for generic clinical text and another for discharge summaries specifically. We demonstrate that using a domain-specific model yields performance improvements on three common clinical NLP tasks as compared to nonspecific embeddings. These domain-specific models are not as performant on two clinical de-identification tasks, and argue that this is a natural consequence of the differences between de-identified source text and synthetically non de-identified task text.
Clinically Accurate Chest X-Ray Report Generation
Apr 04, 2019
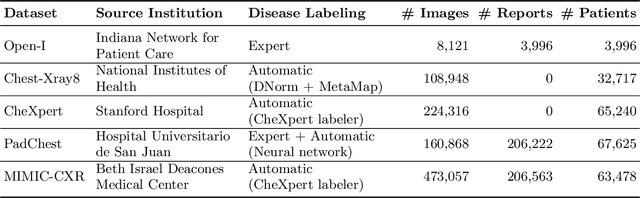
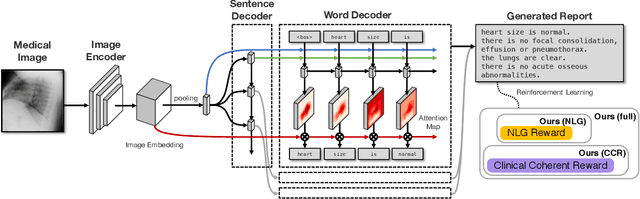
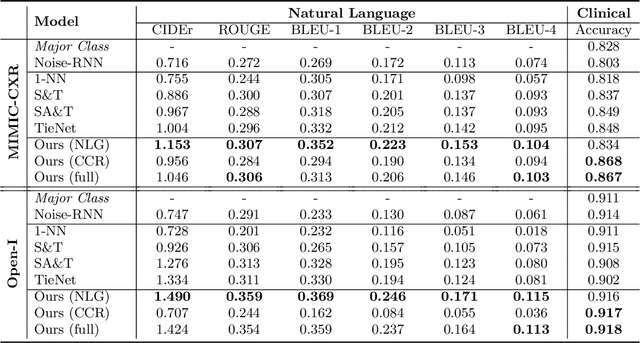
The automatic generation of radiology reports given medical radiographs has significant potential to operationally and clinically improve patient care. A number of prior works have focused on this problem, employing advanced methods from computer vision and natural language generation to produce readable reports. However, these works often fail to account for the particular nuances of the radiology domain, and, in particular, the critical importance of clinical accuracy in the resulting generated reports. In this work, we present a domain-aware automatic chest X-Ray radiology report generation system which first predicts what topics will be discussed in the report, then conditionally generates sentences corresponding to these topics. The resulting system is fine-tuned using reinforcement learning, considering both readability and clinical accuracy, as assessed by the proposed Clinically Coherent Reward. We verify this system on two datasets, Open-I and MIMIC-CXR, and demonstrate that our model offers marked improvements on both language generation metrics and CheXpert assessed accuracy over a variety of competitive baselines.
Unsupervised Clinical Language Translation
Feb 04, 2019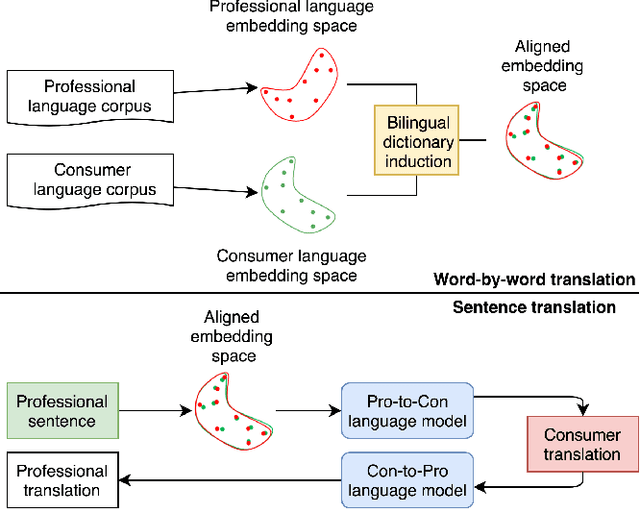
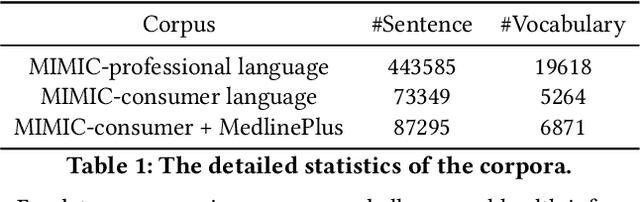

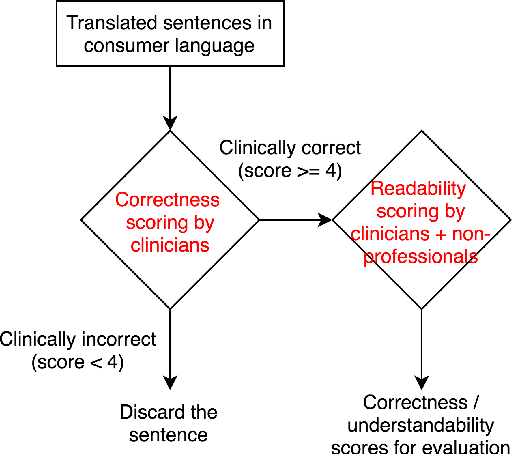
As patients' access to their doctors' clinical notes becomes common, translating professional, clinical jargon to layperson-understandable language is essential to improve patient-clinician communication. Such translation yields better clinical outcomes by enhancing patients' understanding of their own health conditions, and thus improving patients' involvement in their own care. Existing research has used dictionary-based word replacement or definition insertion to approach the need. However, these methods are limited by expert curation, which is hard to scale and has trouble generalizing to unseen datasets that do not share an overlapping vocabulary. In contrast, we approach the clinical word and sentence translation problem in a completely unsupervised manner. We show that a framework using representation learning, bilingual dictionary induction and statistical machine translation yields the best precision at 10 of 0.827 on professional-to-consumer word translation, and mean opinion scores of 4.10 and 4.28 out of 5 for clinical correctness and layperson readability, respectively, on sentence translation. Our fully-unsupervised strategy overcomes the curation problem, and the clinically meaningful evaluation reduces biases from inappropriate evaluators, which are critical in clinical machine learning.
Predicting Blood Pressure Response to Fluid Bolus Therapy Using Attention-Based Neural Networks for Clinical Interpretability
Dec 03, 2018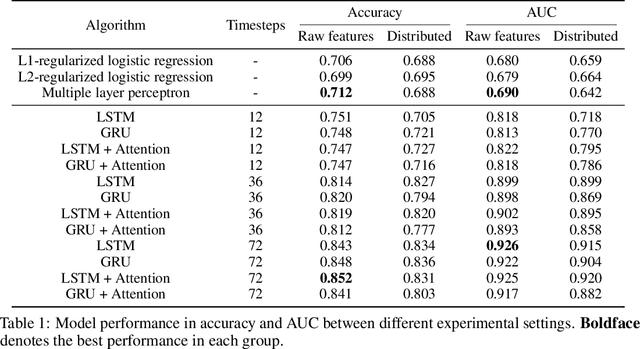
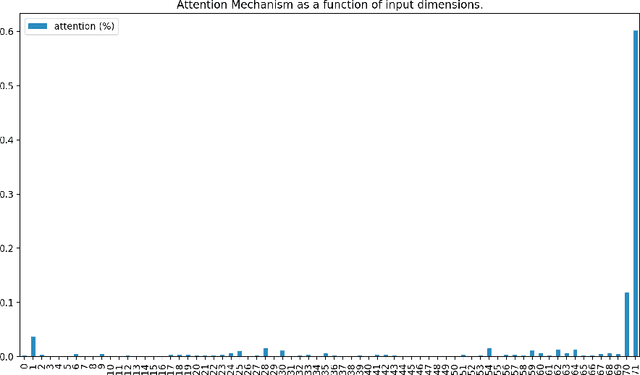
Determining whether hypotensive patients in intensive care units (ICUs) should receive fluid bolus therapy (FBT) has been an extremely challenging task for intensive care physicians as the corresponding increase in blood pressure has been hard to predict. Our study utilized regression models and attention-based recurrent neural network (RNN) algorithms and a multi-clinical information system large-scale database to build models that can predict the successful response to FBT among hypotensive patients in ICUs. We investigated both time-aggregated modeling using logistic regression algorithms with regularization and time-series modeling using the long short term memory network (LSTM) and the gated recurrent units network (GRU) with the attention mechanism for clinical interpretability. Among all modeling strategies, the stacked LSTM with the attention mechanism yielded the most predictable model with the highest accuracy of 0.852 and area under the curve (AUC) value of 0.925. The study results may help identify hypotensive patients in ICUs who will have sufficient blood pressure recovery after FBT.
Unsupervised Multimodal Representation Learning across Medical Images and Reports
Nov 21, 2018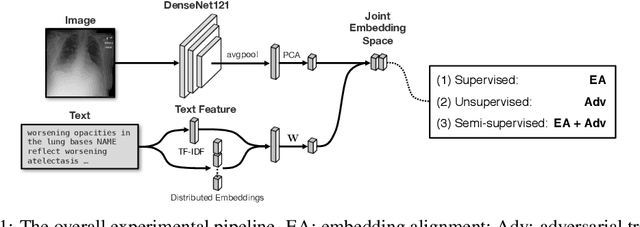
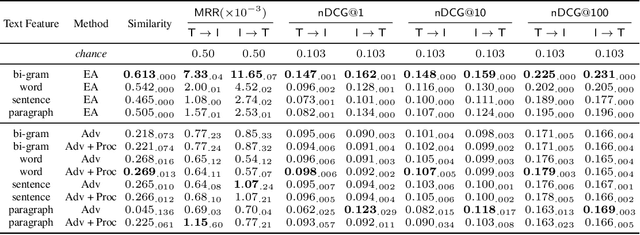
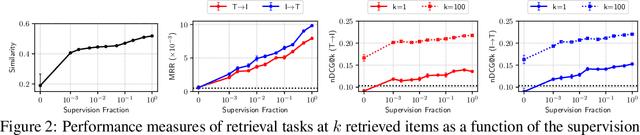
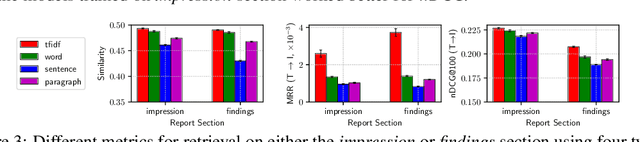
Joint embeddings between medical imaging modalities and associated radiology reports have the potential to offer significant benefits to the clinical community, ranging from cross-domain retrieval to conditional generation of reports to the broader goals of multimodal representation learning. In this work, we establish baseline joint embedding results measured via both local and global retrieval methods on the soon to be released MIMIC-CXR dataset consisting of both chest X-ray images and the associated radiology reports. We examine both supervised and unsupervised methods on this task and show that for document retrieval tasks with the learned representations, only a limited amount of supervision is needed to yield results comparable to those of fully-supervised methods.
Towards Unsupervised Speech-to-Text Translation
Nov 04, 2018
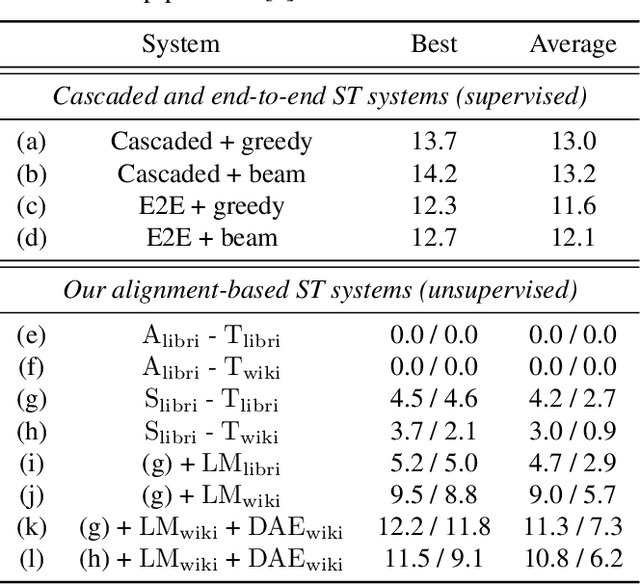
We present a framework for building speech-to-text translation (ST) systems using only monolingual speech and text corpora, in other words, speech utterances from a source language and independent text from a target language. As opposed to traditional cascaded systems and end-to-end architectures, our system does not require any labeled data (i.e., transcribed source audio or parallel source and target text corpora) during training, making it especially applicable to language pairs with very few or even zero bilingual resources. The framework initializes the ST system with a cross-modal bilingual dictionary inferred from the monolingual corpora, that maps every source speech segment corresponding to a spoken word to its target text translation. For unseen source speech utterances, the system first performs word-by-word translation on each speech segment in the utterance. The translation is improved by leveraging a language model and a sequence denoising autoencoder to provide prior knowledge about the target language. Experimental results show that our unsupervised system achieves comparable BLEU scores to supervised end-to-end models despite the lack of supervision. We also provide an ablation analysis to examine the utility of each component in our system.
Unsupervised Cross-Modal Alignment of Speech and Text Embedding Spaces
Sep 20, 2018

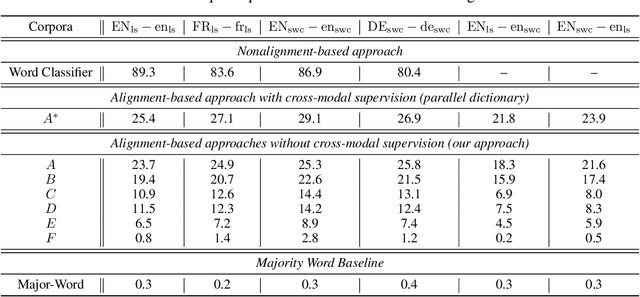

Recent research has shown that word embedding spaces learned from text corpora of different languages can be aligned without any parallel data supervision. Inspired by the success in unsupervised cross-lingual word embeddings, in this paper we target learning a cross-modal alignment between the embedding spaces of speech and text learned from corpora of their respective modalities in an unsupervised fashion. The proposed framework learns the individual speech and text embedding spaces, and attempts to align the two spaces via adversarial training, followed by a refinement procedure. We show how our framework could be used to perform spoken word classification and translation, and the results on these two tasks demonstrate that the performance of our unsupervised alignment approach is comparable to its supervised counterpart. Our framework is especially useful for developing automatic speech recognition (ASR) and speech-to-text translation systems for low- or zero-resource languages, which have little parallel audio-text data for training modern supervised ASR and speech-to-text translation models, but account for the majority of the languages spoken across the world.
Mapping Unparalleled Clinical Professional and Consumer Languages with Embedding Alignment
Jun 25, 2018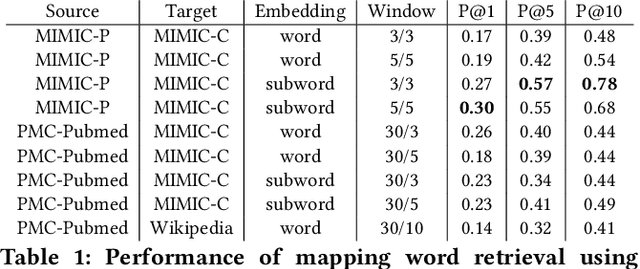
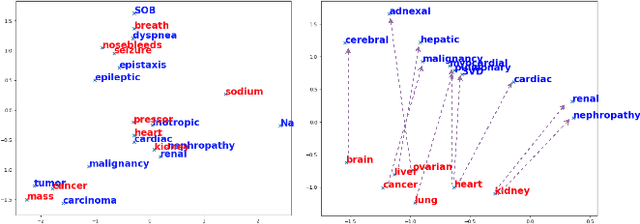
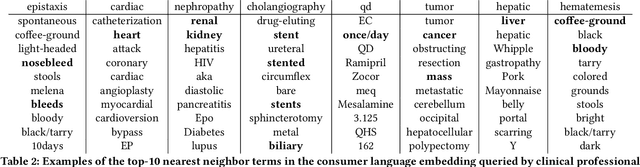
Mapping and translating professional but arcane clinical jargons to consumer language is essential to improve the patient-clinician communication. Researchers have used the existing biomedical ontologies and consumer health vocabulary dictionary to translate between the languages. However, such approaches are limited by expert efforts to manually build the dictionary, which is hard to be generalized and scalable. In this work, we utilized the embeddings alignment method for the word mapping between unparalleled clinical professional and consumer language embeddings. To map semantically similar words in two different word embeddings, we first independently trained word embeddings on both the corpus with abundant clinical professional terms and the other with mainly healthcare consumer terms. Then, we aligned the embeddings by the Procrustes algorithm. We also investigated the approach with the adversarial training with refinement. We evaluated the quality of the alignment through the similar words retrieval both by computing the model precision and as well as judging qualitatively by human. We show that the Procrustes algorithm can be performant for the professional consumer language embeddings alignment, whereas adversarial training with refinement may find some relations between two languages.