 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliable News or Propagandist News? A Neurosymbolic Model Using Genre, Topic, and Persuasion Techniques to Improve Robustness in Classification
Apr 02, 2026Among news disorders, propagandist news are particularly insidious, because they tend to mix oriented messages with factual reports intended to look like reliable news. To detect propaganda, extant approaches based on Language Models such as BERT are promising but often overfit their training datasets, due to biases in data collection. To enhance classification robustness and improve generalization to new sources, we propose a neurosymbolic approach combining non-contextual text embeddings (fastText) with symbolic conceptual features such as genre, topic, and persuasion techniques. Results show improvements over equivalent text-only methods, and ablation studies as well as explainability analyses confirm the benefits of the added features. Keywords: Information disorder, Fake news, Propaganda, Classification, Topic modeling, Hybrid method, Neurosymbolic model, Ablation, Robustness
TEGRA: Text Encoding With Graph and Retrieval Augmentation for Misinformation Detection
Feb 12, 2026Misinformation detection is a critical task that can benefit significantly from the integration of external knowledge, much like manual fact-checking. In this work, we propose a novel method for representing textual documents that facilitates the incorporation of information from a knowledge base. Our approach, Text Encoding with Graph (TEG), processes documents by extracting structured information in the form of a graph and encoding both the text and the graph for classification purposes. Through extensive experiments, we demonstrate that this hybrid representation enhances misinformation detection performance compared to using language models alone. Furthermore, we introduce TEGRA, an extension of our framework that integrates domain-specific knowledge, further enhancing classification accuracy in most cases.
DiffGuard: Text-Based Safety Checker for Diffusion Models
Nov 25, 2024Recent advances in Diffusion Models have enabled the generation of images from text, with powerful closed-source models like DALL-E and Midjourney leading the way. However, open-source alternatives, such as StabilityAI's Stable Diffusion, offer comparable capabilities. These open-source models, hosted on Hugging Face, come equipped with ethical filter protections designed to prevent the generation of explicit images. This paper reveals first their limitations and then presents a novel text-based safety filter that outperforms existing solutions. Our research is driven by the critical need to address the misuse of AI-generated content, especially in the context of information warfare. DiffGuard enhances filtering efficacy, achieving a performance that surpasses the best existing filters by over 14%.
Learning MR-Sort Models from Non-Monotone Data
Jul 20, 2021
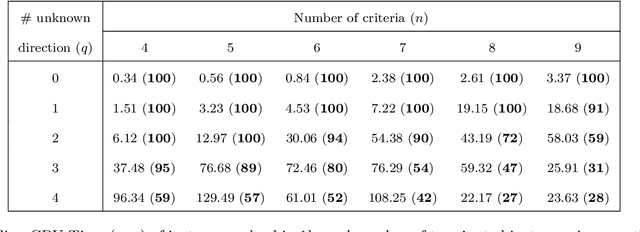
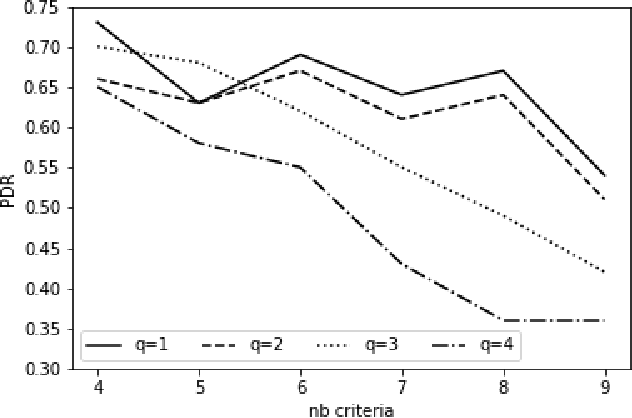

The Majority Rule Sorting (MR-Sort) method assigns alternatives evaluated on multiple criteria to one of the predefined ordered categories. The Inverse MR-Sort problem (Inv-MR-Sort) computes MR-Sort parameters that match a dataset. Existing learning algorithms for Inv-MR-Sort consider monotone preferences on criteria. We extend this problem to the case where the preferences on criteria are not necessarily monotone, but possibly single-peaked (or single-valley). We propose a mixed-integer programming based algorithm that learns the preferences on criteria together with the other MR-Sort parameters from the training data. We investigate the performance of the algorithm using numerical experiments and we illustrate its use on a real-world case study.