 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmyx: Fast and efficient all-atom protein generation
Jun 12, 2026Computational enzyme design requires generating proteins that scaffold catalytic residues and ligands, a task that demands both geometric accuracy and structural diversity from the underlying generative model. Current all-atom generators inherit expensive architectures from structure prediction, leading to high training costs and limited sample diversity. We argue that much of this complexity is unnecessary for generators, which condition on sparse geometric constraints rather than rich co-evolutionary signals. Emyx is a 140M-parameter conditional flow matching model that concentrates capacity within standard transformer blocks, replacing heavy embedding stacks with lightweight conditional representations and sparse connectivity. We additionally derive an exact reparametrisation of the flow matching interpolant into the EDM noise-level framework, bridging flow matching training efficiency with state-of-the-art sampling methods designed for diffusion models without retraining. Despite being the smallest model, Emyx outperforms both Proteína-Complexa and RFdiffusion3 against the AME enzyme design benchmark across success rate under strict evaluation requiring both global fold recovery and catalytic geometry accuracy, structural novelty, scaffold diversity, and geometric validity, while training in just $682$ GPU-hours, roughly $4\times$ less than RFdiffusion3.
Invariant polynomials and machine learning
Apr 26, 2021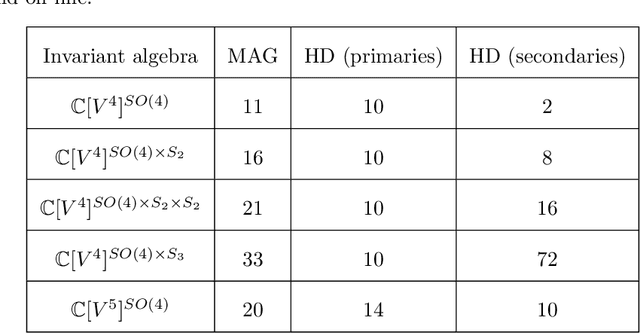
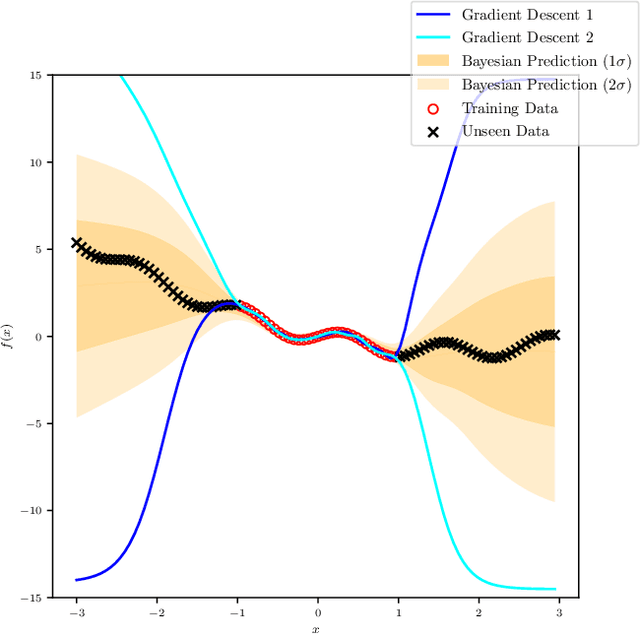
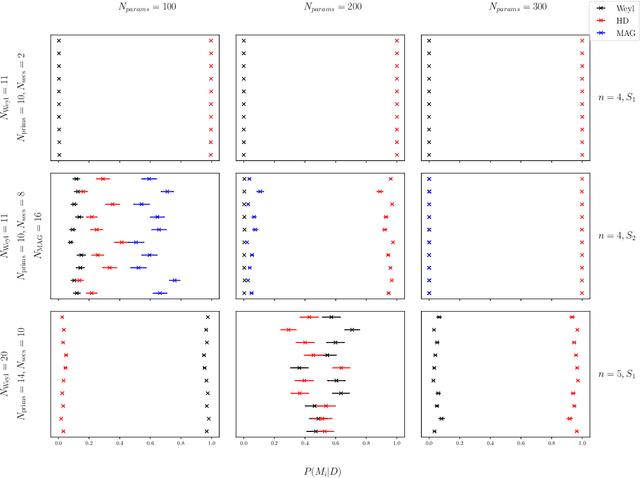
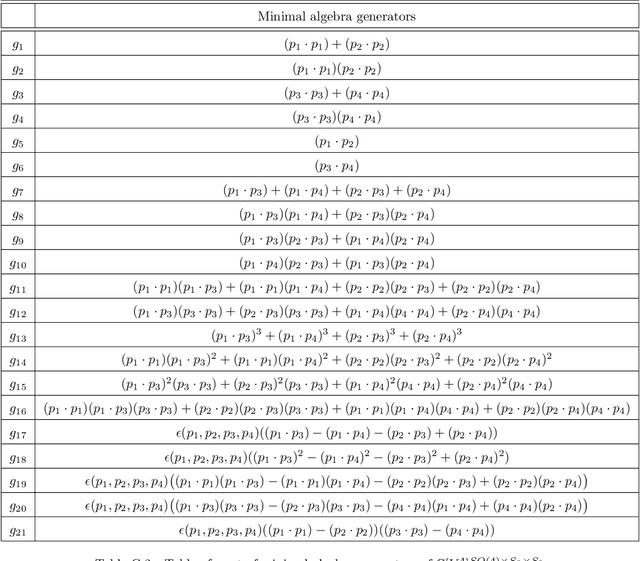
We present an application of invariant polynomials in machine learning. Using the methods developed in previous work, we obtain two types of generators of the Lorentz- and permutation-invariant polynomials in particle momenta; minimal algebra generators and Hironaka decompositions. We discuss and prove some approximation theorems to make use of these invariant generators in machine learning algorithms in general and in neural networks specifically. By implementing these generators in neural networks applied to regression tasks, we test the improvements in performance under a wide range of hyperparameter choices and find a reduction of the loss on training data and a significant reduction of the loss on validation data. For a different approach on quantifying the performance of these neural networks, we treat the problem from a Bayesian inference perspective and employ nested sampling techniques to perform model comparison. Beyond a certain network size, we find that networks utilising Hironaka decompositions perform the best.