 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating both Visual and Audio Cues for Enhanced Video Caption
Dec 09, 2017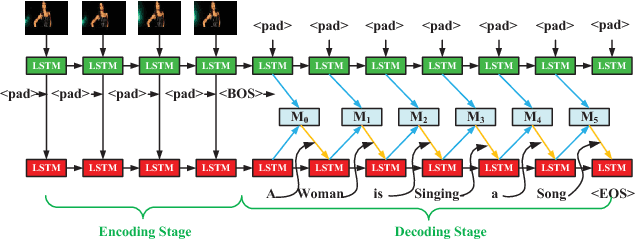
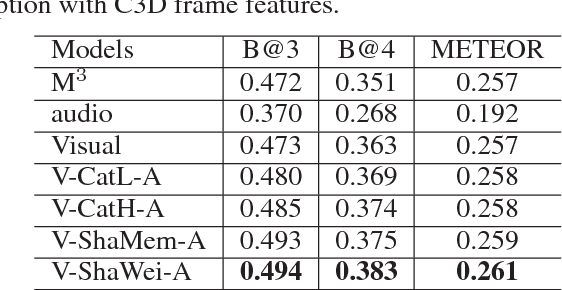
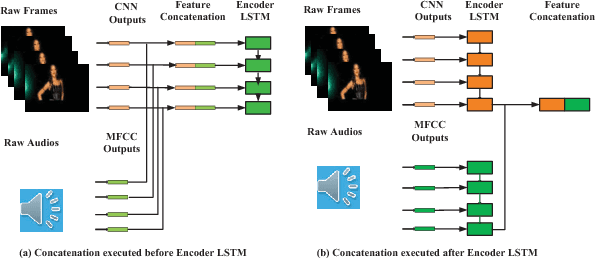
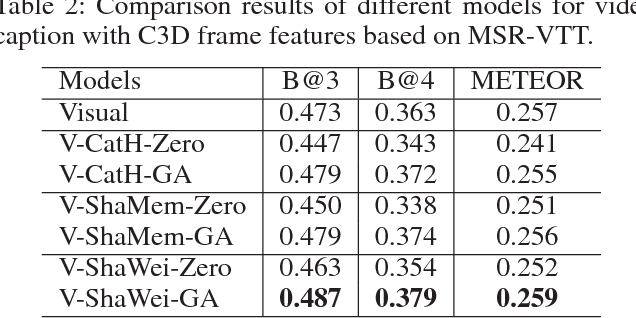
Video caption refers to generating a descriptive sentence for a specific short video clip automatically, which has achieved remarkable success recently. However, most of the existing methods focus more on visual information while ignoring the synchronized audio cues. We propose three multimodal deep fusion strategies to maximize the benefits of visual-audio resonance information. The first one explores the impact on cross-modalities feature fusion from low to high order. The second establishes the visual-audio short-term dependency by sharing weights of corresponding front-end networks. The third extends the temporal dependency to long-term through sharing multimodal memory across visual and audio modalities. Extensive experiments have validated the effectiveness of our three cross-modalities fusion strategies on two benchmark datasets, including Microsoft Research Video to Text (MSRVTT) and Microsoft Video Description (MSVD). It is worth mentioning that sharing weight can coordinate visual-audio feature fusion effectively and achieve the state-of-art performance on both BELU and METEOR metrics. Furthermore, we first propose a dynamic multimodal feature fusion framework to deal with the part modalities missing case. Experimental results demonstrate that even in the audio absence mode, we can still obtain comparable results with the aid of the additional audio modality inference module.
CMCGAN: A Uniform Framework for Cross-Modal Visual-Audio Mutual Generation
Dec 09, 2017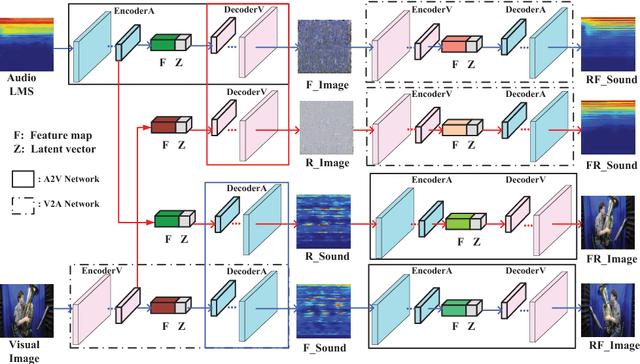

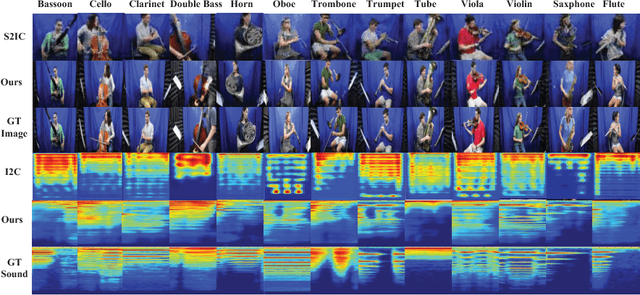

Visual and audio modalities are two symbiotic modalities underlying videos, which contain both common and complementary information. If they can be mined and fused sufficiently, performances of related video tasks can be significantly enhanced. However, due to the environmental interference or sensor fault, sometimes, only one modality exists while the other is abandoned or missing. By recovering the missing modality from the existing one based on the common information shared between them and the prior information of the specific modality, great bonus will be gained for various vision tasks. In this paper, we propose a Cross-Modal Cycle Generative Adversarial Network (CMCGAN) to handle cross-modal visual-audio mutual generation. Specifically, CMCGAN is composed of four kinds of subnetworks: audio-to-visual, visual-to-audio, audio-to-audio and visual-to-visual subnetworks respectively, which are organized in a cycle architecture. CMCGAN has several remarkable advantages. Firstly, CMCGAN unifies visual-audio mutual generation into a common framework by a joint corresponding adversarial loss. Secondly, through introducing a latent vector with Gaussian distribution, CMCGAN can handle dimension and structure asymmetry over visual and audio modalities effectively. Thirdly, CMCGAN can be trained end-to-end to achieve better convenience. Benefiting from CMCGAN, we develop a dynamic multimodal classification network to handle the modality missing problem. Abundant experiments have been conducted and validate that CMCGAN obtains the state-of-the-art cross-modal visual-audio generation results. Furthermore, it is shown that the generated modality achieves comparable effects with those of original modality, which demonstrates the effectiveness and advantages of our proposed method.