 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeach Me What to Say and I Will Learn What to Pick: Unsupervised Knowledge Selection Through Response Generation with Pretrained Generative Models
Oct 05, 2021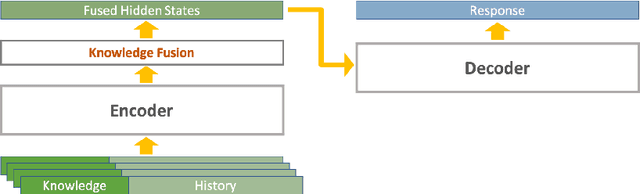

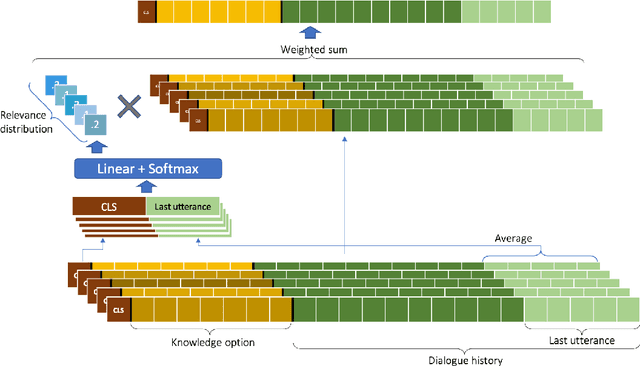
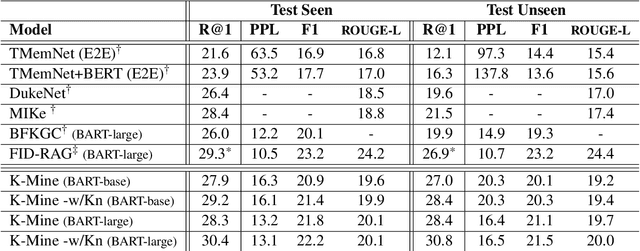
Knowledge Grounded Conversation Models (KGCM) are usually based on a selection/retrieval module and a generation module, trained separately or simultaneously, with or without having access to a gold knowledge option. With the introduction of large pre-trained generative models, the selection and generation part have become more and more entangled, shifting the focus towards enhancing knowledge incorporation (from multiple sources) instead of trying to pick the best knowledge option. These approaches however depend on knowledge labels and/or a separate dense retriever for their best performance. In this work we study the unsupervised selection abilities of pre-trained generative models (e.g. BART) and show that by adding a score-and-aggregate module between encoder and decoder, they are capable of learning to pick the proper knowledge through minimising the language modelling loss (i.e. without having access to knowledge labels). Trained as such, our model - K-Mine - shows competitive selection and generation performance against models that benefit from knowledge labels and/or separate dense retriever.
ConveRT for FAQ Answering
Aug 03, 2021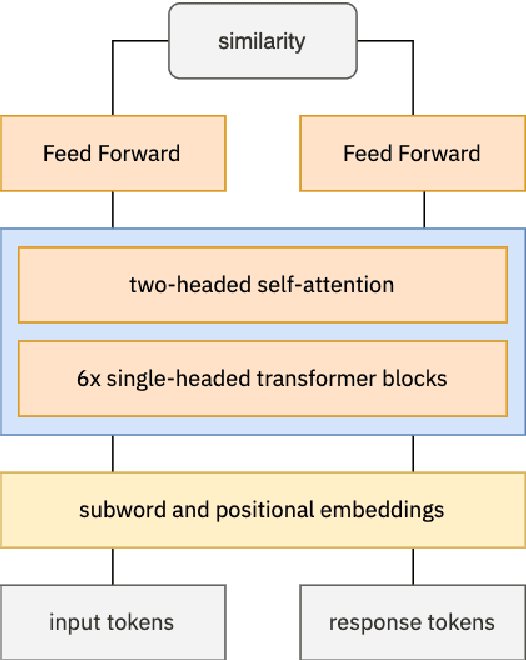
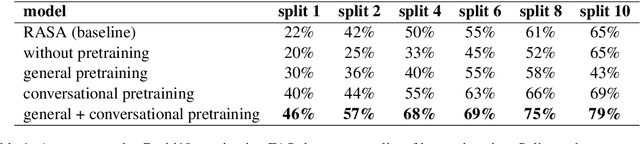
Knowledgeable FAQ chatbots are a valuable resource to any organization. Unlike traditional call centers or FAQ web pages, they provide instant responses and are always available. Our experience running a COVID19 chatbot revealed the lack of resources available for FAQ answering in non-English languages. While powerful and efficient retrieval-based models exist for English, it is rarely the case for other languages which do not have the same amount of training data available. In this work, we propose a novel pretaining procedure to adapt ConveRT, an English SOTA conversational agent, to other languages with less training data available. We apply it for the first time to the task of Dutch FAQ answering related to the COVID19 vaccine. We show it performs better than an open-source alternative in a low-data regime and high-data regime.
Character-level Transformer-based Neural Machine Translation
May 22, 2020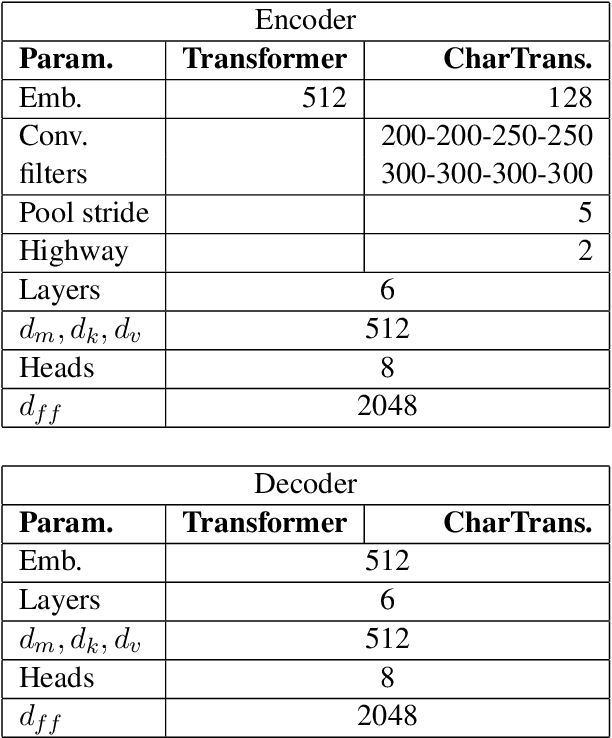
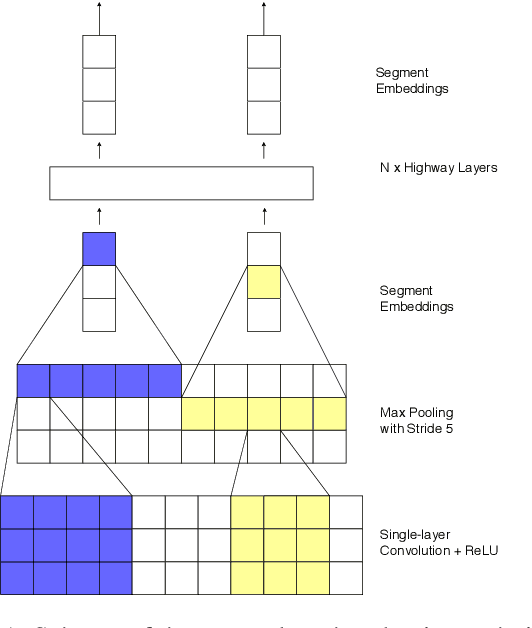
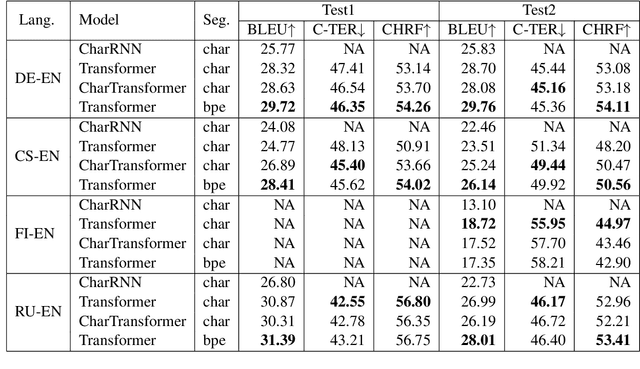
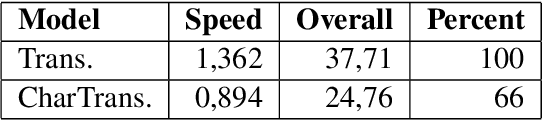
Neural machine translation (NMT) is nowadays commonly applied at the subword level, using byte-pair encoding. A promising alternative approach focuses on character-level translation, which simplifies processing pipelines in NMT considerably. This approach, however, must consider relatively longer sequences, rendering the training process prohibitively expensive. In this paper, we discuss a novel, Transformer-based approach, that we compare, both in speed and in quality to the Transformer at subword and character levels, as well as previously developed character-level models. We evaluate our models on 4 language pairs from WMT'15: DE-EN, CS-EN, FI-EN and RU-EN. The proposed novel architecture can be trained on a single GPU and is 34% percent faster than the character-level Transformer; still, the obtained results are at least on par with it. In addition, our proposed model outperforms the subword-level model in FI-EN and shows close results in CS-EN. To stimulate further research in this area and close the gap with subword-level NMT, we make all our code and models publicly available.
Distilling neural networks into skipgram-level decision lists
May 18, 2020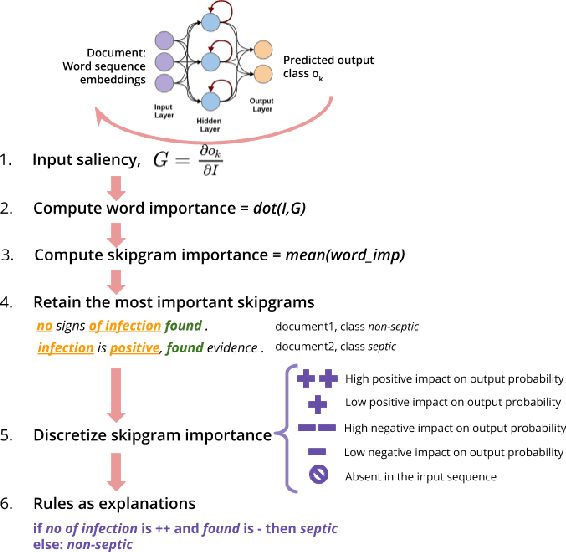
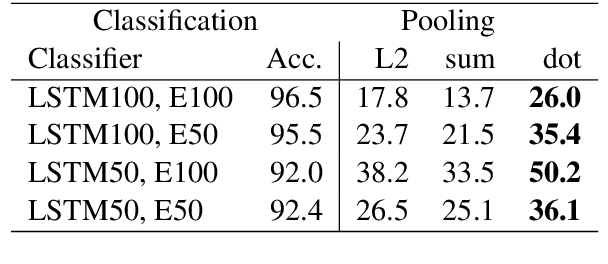

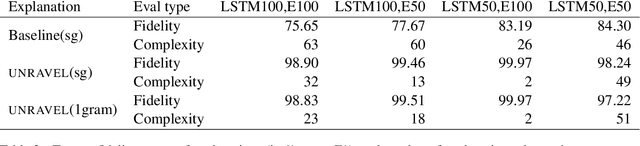
Several previous studies on explanation for recurrent neural networks focus on approaches that find the most important input segments for a network as its explanations. In that case, the manner in which these input segments combine with each other to form an explanatory pattern remains unknown. To overcome this, some previous work tries to find patterns (called rules) in the data that explain neural outputs. However, their explanations are often insensitive to model parameters, which limits the scalability of text explanations. To overcome these limitations, we propose a pipeline to explain RNNs by means of decision lists (also called rules) over skipgrams. For evaluation of explanations, we create a synthetic sepsis-identification dataset, as well as apply our technique on additional clinical and sentiment analysis datasets. We find that our technique persistently achieves high explanation fidelity and qualitatively interpretable rules.
The European Language Technology Landscape in 2020: Language-Centric and Human-Centric AI for Cross-Cultural Communication in Multilingual Europe
Mar 30, 2020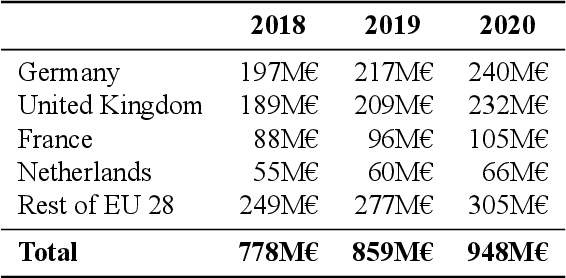
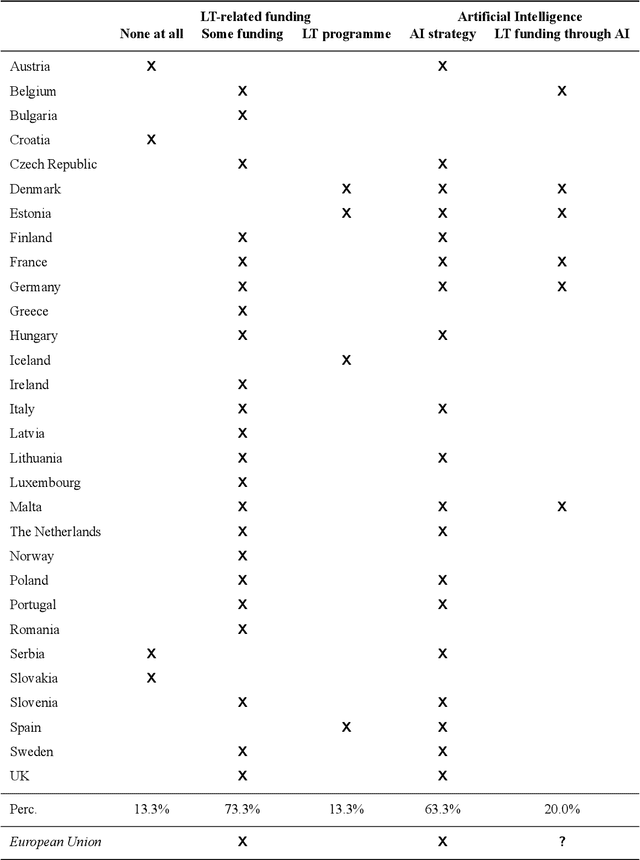
Multilingualism is a cultural cornerstone of Europe and firmly anchored in the European treaties including full language equality. However, language barriers impacting business, cross-lingual and cross-cultural communication are still omnipresent. Language Technologies (LTs) are a powerful means to break down these barriers. While the last decade has seen various initiatives that created a multitude of approaches and technologies tailored to Europe's specific needs, there is still an immense level of fragmentation. At the same time, AI has become an increasingly important concept in the European Information and Communication Technology area. For a few years now, AI, including many opportunities, synergies but also misconceptions, has been overshadowing every other topic. We present an overview of the European LT landscape, describing funding programmes, activities, actions and challenges in the different countries with regard to LT, including the current state of play in industry and the LT market. We present a brief overview of the main LT-related activities on the EU level in the last ten years and develop strategic guidance with regard to four key dimensions.
Current Limitations in Cyberbullying Detection: on Evaluation Criteria, Reproducibility, and Data Scarcity
Oct 25, 2019

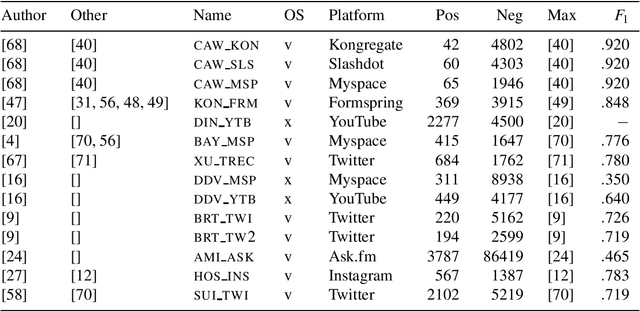
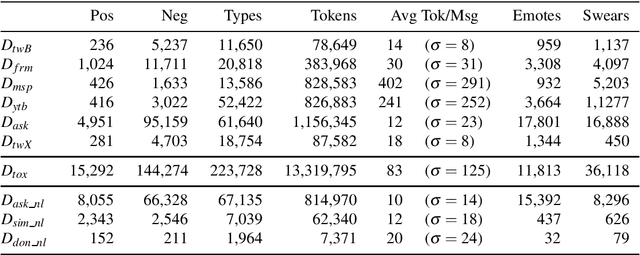
The detection of online cyberbullying has seen an increase in societal importance, popularity in research, and available open data. Nevertheless, while computational power and affordability of resources continue to increase, the access restrictions on high-quality data limit the applicability of state-of-the-art techniques. Consequently, much of the recent research uses small, heterogeneous datasets, without a thorough evaluation of applicability. In this paper, we further illustrate these issues, as we (i) evaluate many publicly available resources for this task and demonstrate difficulties with data collection. These predominantly yield small datasets that fail to capture the required complex social dynamics and impede direct comparison of progress. We (ii) conduct an extensive set of experiments that indicate a general lack of cross-domain generalization of classifiers trained on these sources, and openly provide this framework to replicate and extend our evaluation criteria. Finally, we (iii) present an effective crowdsourcing method: simulating real-life bullying scenarios in a lab setting generates plausible data that can be effectively used to enrich real data. This largely circumvents the restrictions on data that can be collected, and increases classifier performance. We believe these contributions can aid in improving the empirical practices of future research in the field.
Why can't memory networks read effectively?
Oct 16, 2019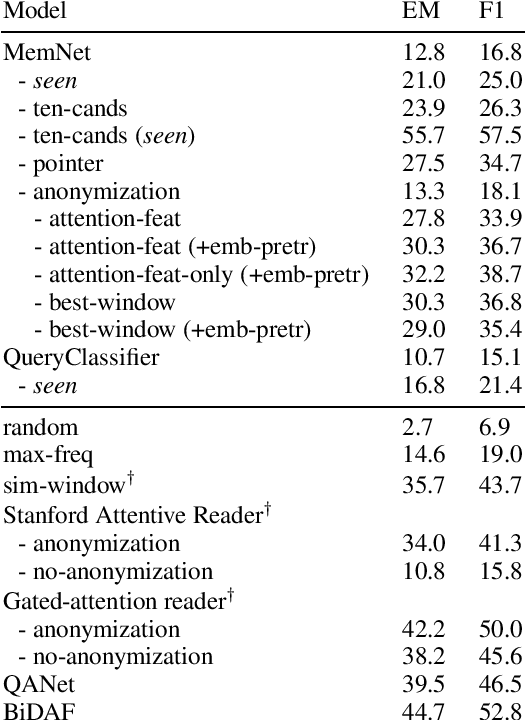
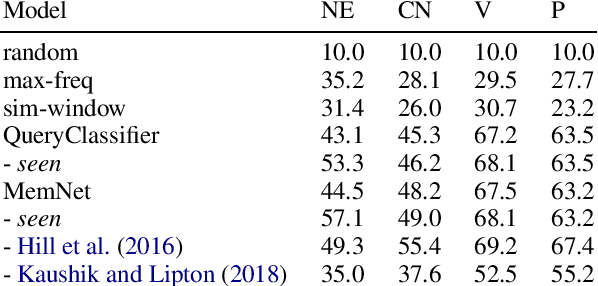

Memory networks have been a popular choice among neural architectures for machine reading comprehension and question answering. While recent work revealed that memory networks can't truly perform multi-hop reasoning, we show in the present paper that vanilla memory networks are ineffective even in single-hop reading comprehension. We analyze the reasons for this on two cloze-style datasets, one from the medical domain and another including children's fiction. We find that the output classification layer with entity-specific weights, and the aggregation of passage information with relatively flat attention distributions are the most important contributors to poor results. We propose network adaptations that can serve as simple remedies. We also find that the presence of unseen answers at test time can dramatically affect the reported results, so we suggest controlling for this factor during evaluation.
A weakly supervised sequence tagging and grammar induction approach to semantic frame slot filling
Jun 15, 2019
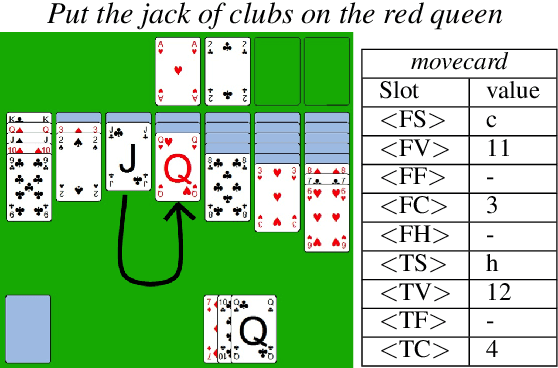
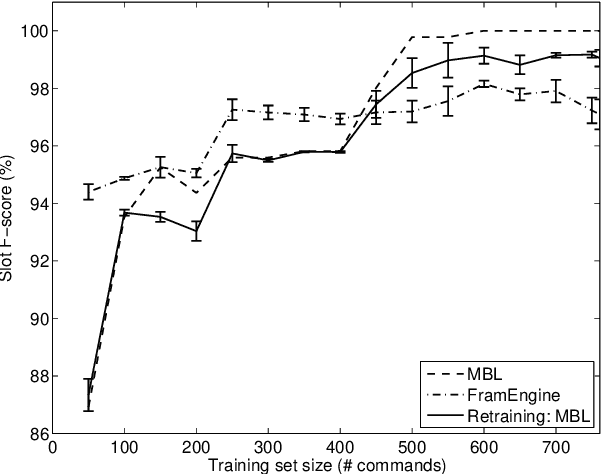
This paper describes continuing work on semantic frame slot filling for a command and control task using a weakly-supervised approach. We investigate the advantages of using retraining techniques that take the output of a hierarchical hidden markov model as input to two inductive approaches: (1) discriminative sequence labelers based on conditional random fields and memory-based learning and (2) probabilistic context-free grammar induction. Experimental results show that this setup can significantly improve F-scores without the need for additional information sources. Furthermore, qualitative analysis shows that the weakly supervised technique is able to automatically induce an easily interpretable and syntactically appropriate grammar for the domain and task at hand.
Effective weakly supervised semantic frame induction using expression sharing in hierarchical hidden Markov models
Jan 30, 2019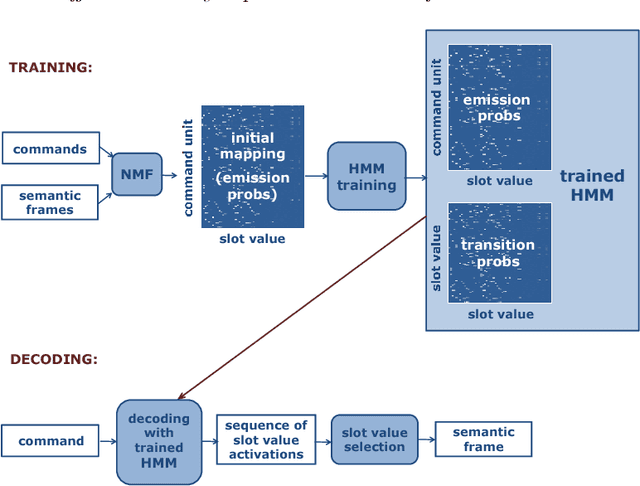
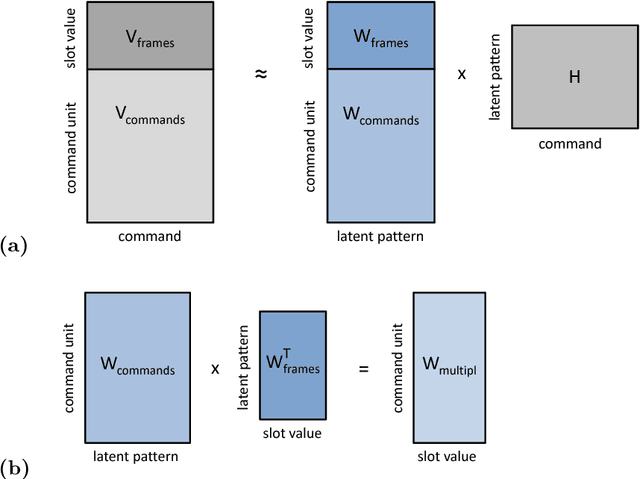
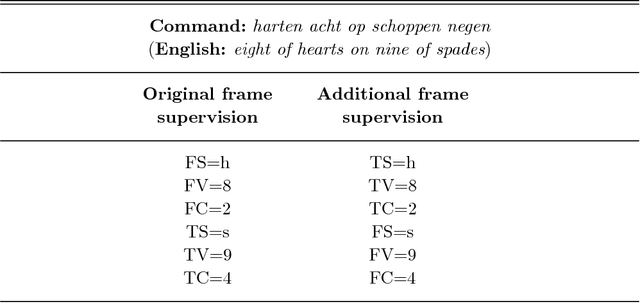
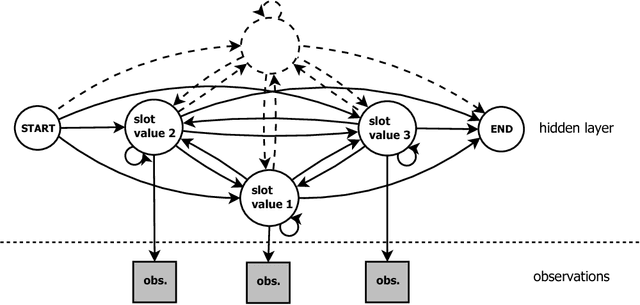
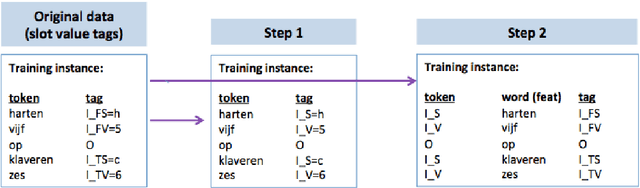
We present a framework for the induction of semantic frames from utterances in the context of an adaptive command-and-control interface. The system is trained on an individual user's utterances and the corresponding semantic frames representing controls. During training, no prior information on the alignment between utterance segments and frame slots and values is available. In addition, semantic frames in the training data can contain information that is not expressed in the utterances. To tackle this weakly supervised classification task, we propose a framework based on Hidden Markov Models (HMMs). Structural modifications, resulting in a hierarchical HMM, and an extension called expression sharing are introduced to minimize the amount of training time and effort required for the user. The dataset used for the present study is PATCOR, which contains commands uttered in the context of a vocally guided card game, Patience. Experiments were carried out on orthographic and phonetic transcriptions of commands, segmented on different levels of n-gram granularity. The experimental results show positive effects of all the studied system extensions, with some effect differences between the different input representations. Moreover, evaluation experiments on held-out data with the optimal system configuration show that the extended system is able to achieve high accuracies with relatively small amounts of training data.
Multilingual Cross-domain Perspectives on Online Hate Speech
Sep 11, 2018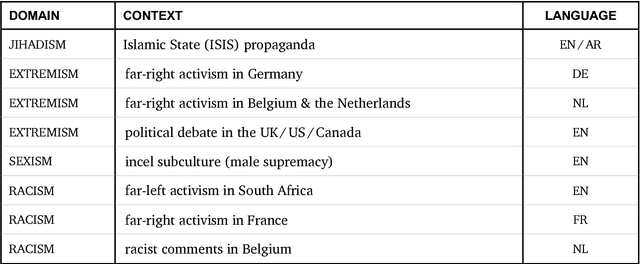

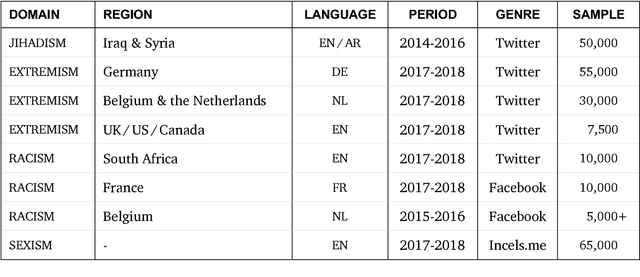
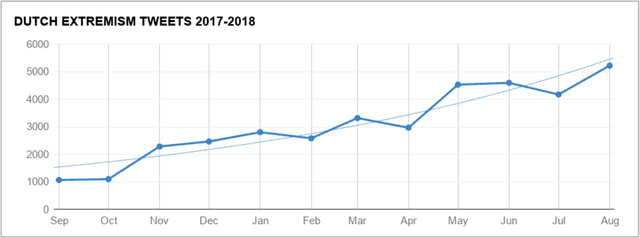
In this report, we present a study of eight corpora of online hate speech, by demonstrating the NLP techniques that we used to collect and analyze the jihadist, extremist, racist, and sexist content. Analysis of the multilingual corpora shows that the different contexts share certain characteristics in their hateful rhetoric. To expose the main features, we have focused on text classification, text profiling, keyword and collocation extraction, along with manual annotation and qualitative study.
* 24 pages