 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSherlock: Scalable Fact Learning in Images
Apr 02, 2016
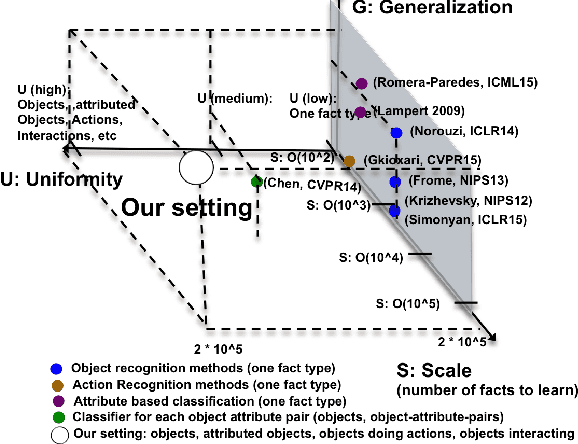
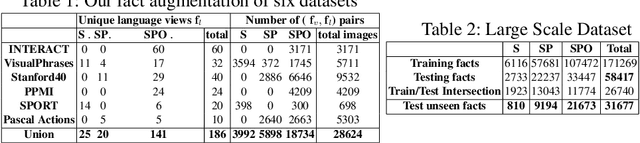
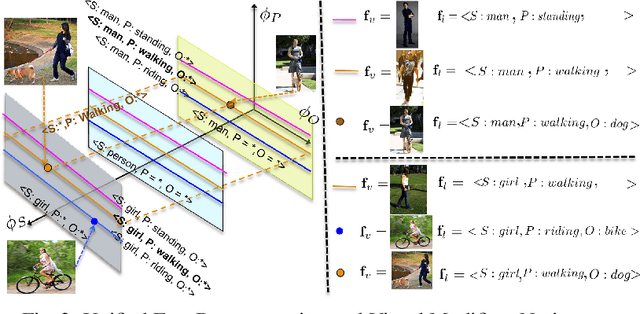
We study scalable and uniform understanding of facts in images. Existing visual recognition systems are typically modeled differently for each fact type such as objects, actions, and interactions. We propose a setting where all these facts can be modeled simultaneously with a capacity to understand unbounded number of facts in a structured way. The training data comes as structured facts in images, including (1) objects (e.g., $<$boy$>$), (2) attributes (e.g., $<$boy, tall$>$), (3) actions (e.g., $<$boy, playing$>$), and (4) interactions (e.g., $<$boy, riding, a horse $>$). Each fact has a semantic language view (e.g., $<$ boy, playing$>$) and a visual view (an image with this fact). We show that learning visual facts in a structured way enables not only a uniform but also generalizable visual understanding. We propose and investigate recent and strong approaches from the multiview learning literature and also introduce two learning representation models as potential baselines. We applied the investigated methods on several datasets that we augmented with structured facts and a large scale dataset of more than 202,000 facts and 814,000 images. Our experiments show the advantage of relating facts by the structure by the proposed models compared to the designed baselines on bidirectional fact retrieval.