 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLikeThis! Empowering App Users to Submit UI Improvement Suggestions Instead of Complaints
Mar 04, 2026User feedback is crucial for the evolution of mobile apps. However, research suggests that users tend to submit uninformative, vague, or destructive feedback. Unlike recent AI4SE approaches that focus on generating code and other development artifacts, our work aims at empowering users to submit better and more constructive UI feedback with concrete suggestions on how to improve the app. We propose LikeThis!, a GenAI-based approach that takes a user comment with the corresponding screenshot to immediately generate multiple improvement alternatives, from which the user can easily choose their preferred option. To evaluate LikeThis!, we first conducted a model benchmarking study based on a public dataset of carefully critiqued UI designs. The results show that GPT-Image-1 significantly outperformed three other state-of-the-art image generation models in improving the designs to address UI issues while keeping the fidelity and without introducing new issues. An intermediate step in LikeThis! is to generate a solution specification before sketching the design as a key to achieving effective improvement. Second, we conducted a user study with 10 production apps, where 15 users used LikeThis! to submit their feedback on encountered issues. Later, the developers of the apps assessed the understandability and actionability of the feedback with and without generated improvements. The results show that our approach helps generate better feedback from both user and developer perspectives, paving the way for AI-assisted user-developer collaboration.
FeedAIde: Guiding App Users to Submit Rich Feedback Reports by Asking Context-Aware Follow-Up Questions
Mar 04, 2026User feedback is essential for the success of mobile apps, yet what users report and what developers need often diverge. Research shows that users often submit vague feedback and omit essential contextual details. This leads to incomplete reports and time-consuming clarification discussions. To overcome this challenge, we propose FeedAIde, a context-aware, interactive feedback approach that supports users during the reporting process by leveraging the reasoning capabilities of Multimodal Large Language Models. FeedAIde captures contextual information, such as the screenshot where the issue emerges, and uses it for adaptive follow-up questions to collaboratively refine with the user a rich feedback report that contains information relevant to developers. We implemented an iOS framework of FeedAIde and evaluated it on a gym's app with its users. Compared to the app's simple feedback form, participants rated FeedAIde as easier and more helpful for reporting feedback. An assessment by two industry experts of the resulting 54 reports showed that FeedAIde improved the quality of both bug reports and feature requests, particularly in terms of completeness. The findings of our study demonstrate the potential of context-aware, GenAI-powered feedback reporting to enhance the experience for users and increase the information value for developers.
How Do Programming Students Use Generative AI?
Jan 17, 2025Programming students have a widespread access to powerful Generative AI tools like ChatGPT. While this can help understand the learning material and assist with exercises, educators are voicing more and more concerns about an over-reliance on generated outputs and lack of critical thinking skills. It is thus important to understand how students actually use generative AI and what impact this could have on their learning behavior. To this end, we conducted a study including an exploratory experiment with 37 programming students, giving them monitored access to ChatGPT while solving a code understanding and improving exercise. While only 23 of the students actually opted to use the chatbot, the majority of those eventually prompted it to simply generate a full solution. We observed two prevalent usage strategies: to seek knowledge about general concepts and to directly generate solutions. Instead of using the bot to comprehend the code and their own mistakes, students often got trapped in a vicious cycle of submitting wrong generated code and then asking the bot for a fix. Those who self-reported using generative AI regularly were more likely to prompt the bot to generate a solution. Our findings indicate that concerns about potential decrease in programmers' agency and productivity with Generative AI are justified. We discuss how researchers and educators can respond to the potential risk of students uncritically over-relying on generative AI. We also discuss potential modifications to our study design for large-scale replications.
Getting Inspiration for Feature Elicitation: App Store- vs. LLM-based Approach
Aug 30, 2024Over the past decade, app store (AppStore)-inspired requirements elicitation has proven to be highly beneficial. Developers often explore competitors' apps to gather inspiration for new features. With the advance of Generative AI, recent studies have demonstrated the potential of large language model (LLM)-inspired requirements elicitation. LLMs can assist in this process by providing inspiration for new feature ideas. While both approaches are gaining popularity in practice, there is a lack of insight into their differences. We report on a comparative study between AppStore- and LLM-based approaches for refining features into sub-features. By manually analyzing 1,200 sub-features recommended from both approaches, we identified their benefits, challenges, and key differences. While both approaches recommend highly relevant sub-features with clear descriptions, LLMs seem more powerful particularly concerning novel unseen app scopes. Moreover, some recommended features are imaginary with unclear feasibility, which suggests the importance of a human-analyst in the elicitation loop.
Can Developers Prompt? A Controlled Experiment for Code Documentation Generation
Aug 01, 2024Large language models (LLMs) bear great potential for automating tedious development tasks such as creating and maintaining code documentation. However, it is unclear to what extent developers can effectively prompt LLMs to create concise and useful documentation. We report on a controlled experiment with 20 professionals and 30 computer science students tasked with code documentation generation for two Python functions. The experimental group freely entered ad-hoc prompts in a ChatGPT-like extension of Visual Studio Code, while the control group executed a predefined few-shot prompt. Our results reveal that professionals and students were unaware of or unable to apply prompt engineering techniques. Especially students perceived the documentation produced from ad-hoc prompts as significantly less readable, less concise, and less helpful than documentation from prepared prompts. Some professionals produced higher quality documentation by just including the keyword Docstring in their ad-hoc prompts. While students desired more support in formulating prompts, professionals appreciated the flexibility of ad-hoc prompting. Participants in both groups rarely assessed the output as perfect. Instead, they understood the tools as support to iteratively refine the documentation. Further research is needed to understand which prompting skills and preferences developers have and which support they need for certain tasks.
On AI-Inspired UI-Design
Jun 19, 2024



Graphical User Interface (or simply UI) is a primary mean of interaction between users and their device. In this paper, we discuss three major complementary approaches on how to use Artificial Intelligence (AI) to support app designers create better, more diverse, and creative UI of mobile apps. First, designers can prompt a Large Language Model (LLM) like GPT to directly generate and adjust one or multiple UIs. Second, a Vision-Language Model (VLM) enables designers to effectively search a large screenshot dataset, e.g. from apps published in app stores. The third approach is to train a Diffusion Model (DM) specifically designed to generate app UIs as inspirational images. We discuss how AI should be used, in general, to inspire and assist creative app design rather than automating it.
GUing: A Mobile GUI Search Engine using a Vision-Language Model
Apr 30, 2024



App developers use the Graphical User Interface (GUI) of other apps as an important source of inspiration to design and improve their own apps. In recent years, research suggested various approaches to retrieve GUI designs that fit a certain text query from screenshot datasets acquired through automated GUI exploration. However, such text-to-GUI retrieval approaches only leverage the textual information of the GUI elements in the screenshots, neglecting visual information such as icons or background images. In addition, the retrieved screenshots are not steered by app developers and often lack important app features, e.g. whose UI pages require user authentication. To overcome these limitations, this paper proposes GUing, a GUI search engine based on a vision-language model called UIClip, which we trained specifically for the app GUI domain. For this, we first collected app introduction images from Google Play, which usually display the most representative screenshots selected and often captioned (i.e. labeled) by app vendors. Then, we developed an automated pipeline to classify, crop, and extract the captions from these images. This finally results in a large dataset which we share with this paper: including 303k app screenshots, out of which 135k have captions. We used this dataset to train a novel vision-language model, which is, to the best of our knowledge, the first of its kind in GUI retrieval. We evaluated our approach on various datasets from related work and in manual experiment. The results demonstrate that our model outperforms previous approaches in text-to-GUI retrieval achieving a Recall@10 of up to 0.69 and a HIT@10 of 0.91. We also explored the performance of UIClip for other GUI tasks including GUI classification and Sketch-to-GUI retrieval with encouraging results.
Tailoring Requirements Engineering for Responsible AI
Feb 21, 2023Requirements Engineering (RE) is the discipline for identifying, analyzing, as well as ensuring the implementation and delivery of user, technical, and societal requirements. Recently reported issues concerning the acceptance of Artificial Intelligence (AI) solutions after deployment, e.g. in the medical, automotive, or scientific domains, stress the importance of RE for designing and delivering Responsible AI systems. In this paper, we argue that RE should not only be carefully conducted but also tailored for Responsible AI. We outline related challenges for research and practice.
Beyond Duplicates: Towards Understanding and Predicting Link Types in Issue Tracking Systems
Apr 27, 2022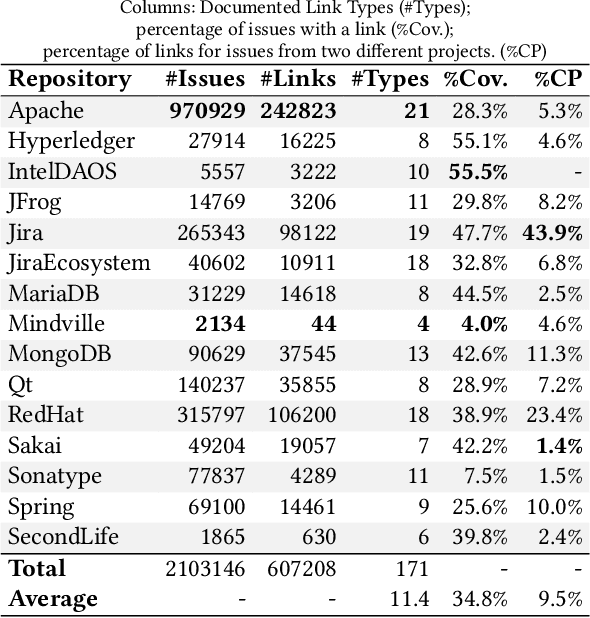
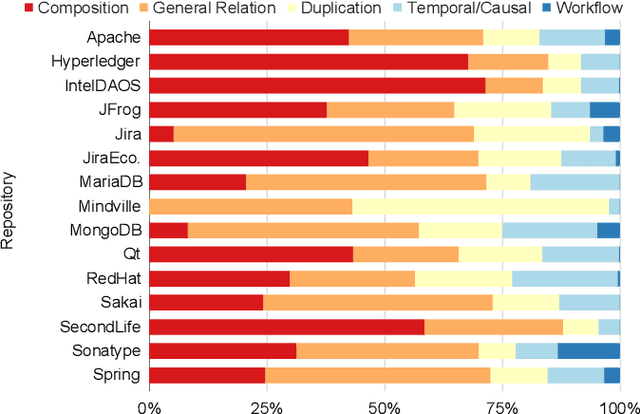
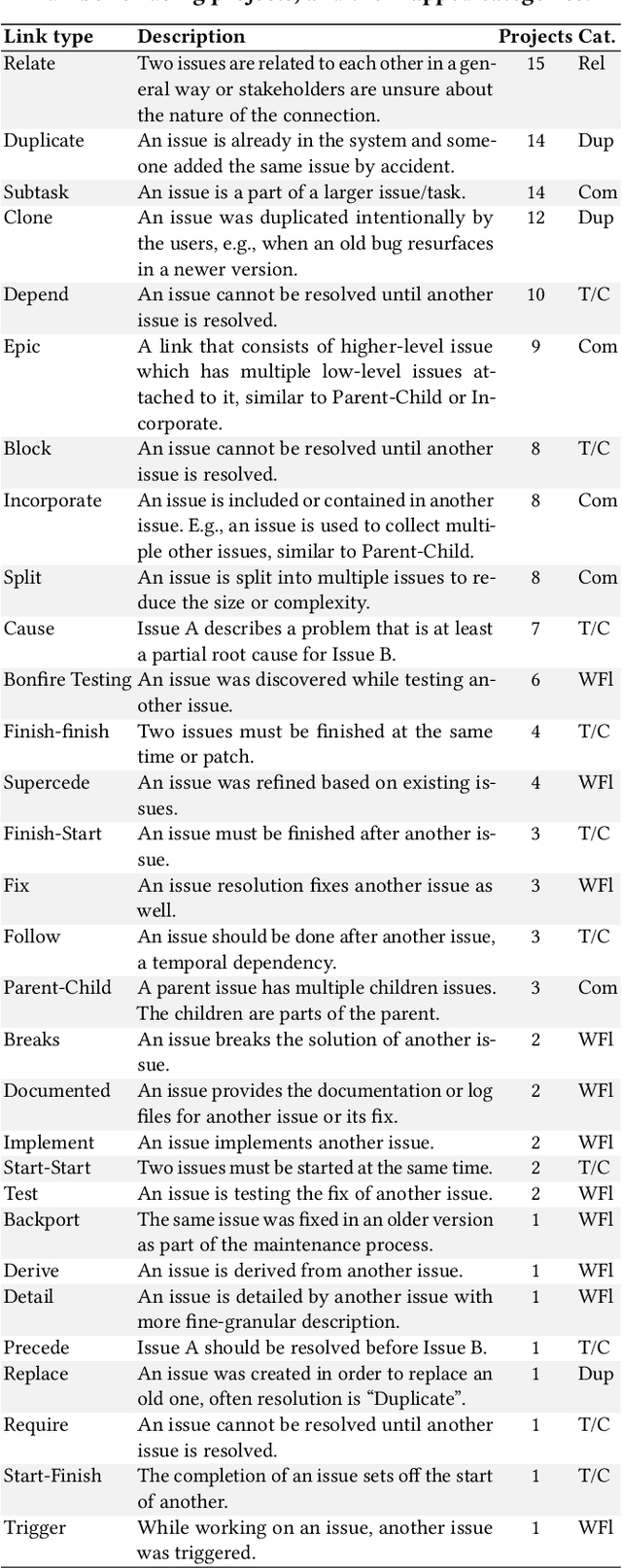
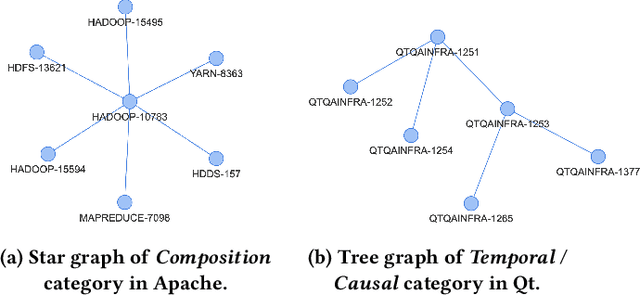
Software projects use Issue Tracking Systems (ITS) like JIRA to track issues and organize the workflows around them. Issues are often inter-connected via different links such as the default JIRA link types Duplicate, Relate, Block, or Subtask. While previous research has mostly focused on analyzing and predicting duplication links, this work aims at understanding the various other link types, their prevalence, and characteristics towards a more reliable link type prediction. For this, we studied 607,208 links connecting 698,790 issues in 15 public JIRA repositories. Besides the default types, the custom types Depend, Incorporate, Split, and Cause were also common. We manually grouped all 75 link types used in the repositories into five general categories: General Relation, Duplication, Composition, Temporal / Causal, and Workflow. Comparing the structures of the corresponding graphs, we observed several trends. For instance, Duplication links tend to represent simpler issue graphs often with two components and Composition links present the highest amount of hierarchical tree structures (97.7%). Surprisingly, General Relation links have a significantly higher transitivity score than Duplication and Temporal / Causal links. Motivated by the differences between the link types and by their popularity, we evaluated the robustness of two state-of-the-art duplicate detection approaches from the literature on the JIRA dataset. We found that current deep-learning approaches confuse between Duplication and other links in almost all repositories. On average, the classification accuracy dropped by 6% for one approach and 12% for the other. Extending the training sets with other link types seems to partly solve this issue. We discuss our findings and their implications for research and practice.
Efficient, Uncertainty-based Moderation of Neural Networks Text Classifiers
Apr 04, 2022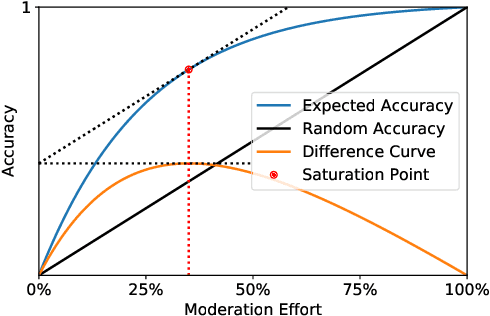
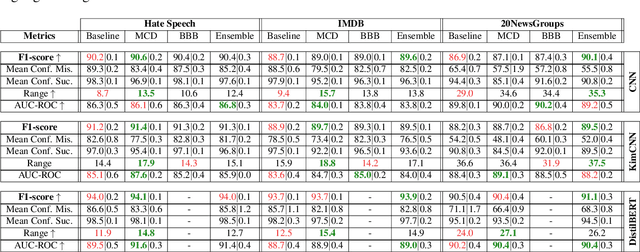
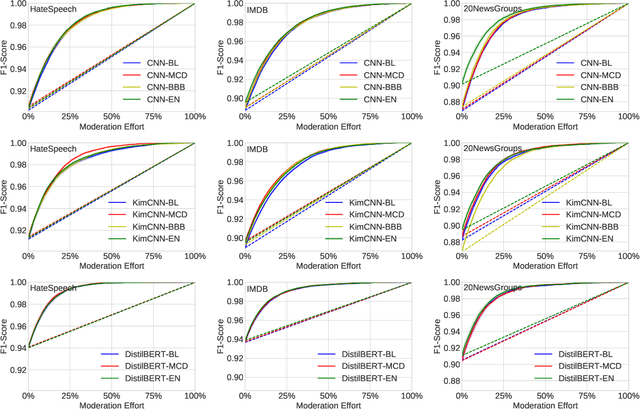
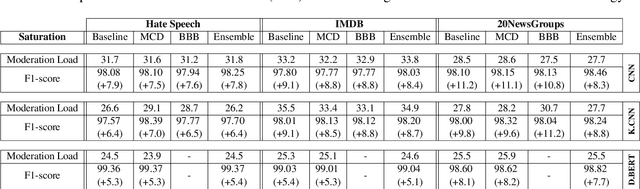
To maximize the accuracy and increase the overall acceptance of text classifiers, we propose a framework for the efficient, in-operation moderation of classifiers' output. Our framework focuses on use cases in which F1-scores of modern Neural Networks classifiers (ca.~90%) are still inapplicable in practice. We suggest a semi-automated approach that uses prediction uncertainties to pass unconfident, probably incorrect classifications to human moderators. To minimize the workload, we limit the human moderated data to the point where the accuracy gains saturate and further human effort does not lead to substantial improvements. A series of benchmarking experiments based on three different datasets and three state-of-the-art classifiers show that our framework can improve the classification F1-scores by 5.1 to 11.2% (up to approx.~98 to 99%), while reducing the moderation load up to 73.3% compared to a random moderation.