 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering User Types: Mapping User Traits by Task-Specific Behaviors in Reinforcement Learning
Jul 16, 2023



When assisting human users in reinforcement learning (RL), we can represent users as RL agents and study key parameters, called \emph{user traits}, to inform intervention design. We study the relationship between user behaviors (policy classes) and user traits. Given an environment, we introduce an intuitive tool for studying the breakdown of "user types": broad sets of traits that result in the same behavior. We show that seemingly different real-world environments admit the same set of user types and formalize this observation as an equivalence relation defined on environments. By transferring intervention design between environments within the same equivalence class, we can help rapidly personalize interventions.
On Identification of Sparse Multivariable ARX Model: A Sparse Bayesian Learning Approach
Sep 30, 2016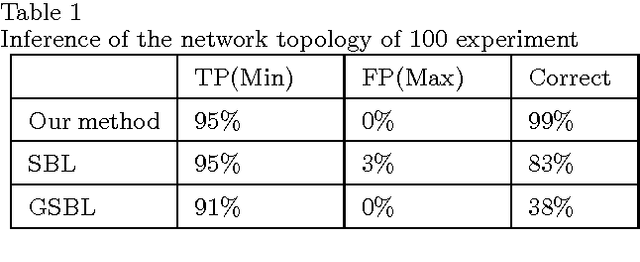
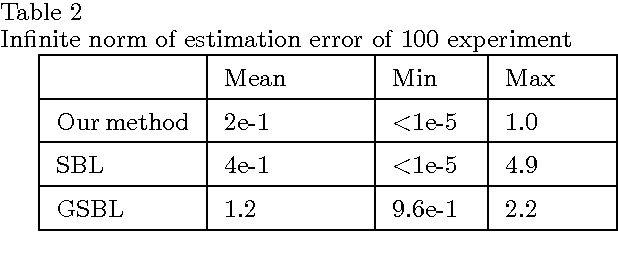
This paper begins with considering the identification of sparse linear time-invariant networks described by multivariable ARX models. Such models possess relatively simple structure thus used as a benchmark to promote further research. With identifiability of the network guaranteed, this paper presents an identification method that infers both the Boolean structure of the network and the internal dynamics between nodes. Identification is performed directly from data without any prior knowledge of the system, including its order. The proposed method solves the identification problem using Maximum a posteriori estimation (MAP) but with inseparable penalties for complexity, both in terms of element (order of nonzero connections) and group sparsity (network topology). Such an approach is widely applied in Compressive Sensing (CS) and known as Sparse Bayesian Learning (SBL). We then propose a novel scheme that combines sparse Bayesian and group sparse Bayesian to efficiently solve the problem. The resulted algorithm has a similar form of the standard Sparse Group Lasso (SGL) while with known noise variance, it simplifies to exact re-weighted SGL. The method and the developed toolbox can be applied to infer networks from a wide range of fields, including systems biology applications such as signaling and genetic regulatory networks.
A Characterization of the Non-Uniqueness of Nonnegative Matrix Factorizations
Apr 03, 2016

Nonnegative matrix factorization (NMF) is a popular dimension reduction technique that produces interpretable decomposition of the data into parts. However, this decompostion is not generally identifiable (even up to permutation and scaling). While other studies have provide criteria under which NMF is identifiable, we present the first (to our knowledge) characterization of the non-identifiability of NMF. We describe exactly when and how non-uniqueness can occur, which has important implications for algorithms to efficiently discover alternate solutions, if they exist.