 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEuclid Quick Data Release (Q1). Active galactic nuclei identification using diffusion-based inpainting of Euclid VIS images
Mar 19, 2025Light emission from galaxies exhibit diverse brightness profiles, influenced by factors such as galaxy type, structural features and interactions with other galaxies. Elliptical galaxies feature more uniform light distributions, while spiral and irregular galaxies have complex, varied light profiles due to their structural heterogeneity and star-forming activity. In addition, galaxies with an active galactic nucleus (AGN) feature intense, concentrated emission from gas accretion around supermassive black holes, superimposed on regular galactic light, while quasi-stellar objects (QSO) are the extreme case of the AGN emission dominating the galaxy. The challenge of identifying AGN and QSO has been discussed many times in the literature, often requiring multi-wavelength observations. This paper introduces a novel approach to identify AGN and QSO from a single image. Diffusion models have been recently developed in the machine-learning literature to generate realistic-looking images of everyday objects. Utilising the spatial resolving power of the Euclid VIS images, we created a diffusion model trained on one million sources, without using any source pre-selection or labels. The model learns to reconstruct light distributions of normal galaxies, since the population is dominated by them. We condition the prediction of the central light distribution by masking the central few pixels of each source and reconstruct the light according to the diffusion model. We further use this prediction to identify sources that deviate from this profile by examining the reconstruction error of the few central pixels regenerated in each source's core. Our approach, solely using VIS imaging, features high completeness compared to traditional methods of AGN and QSO selection, including optical, near-infrared, mid-infrared, and X-rays. [abridged]
A machine learning approach to galaxy properties: Joint redshift - stellar mass probability distributions with Random Forest
Dec 10, 2020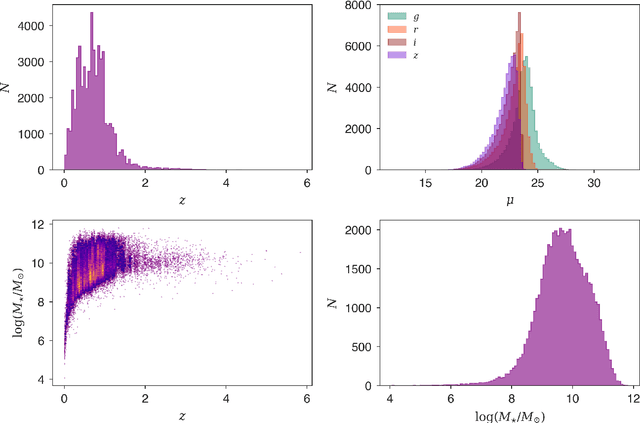

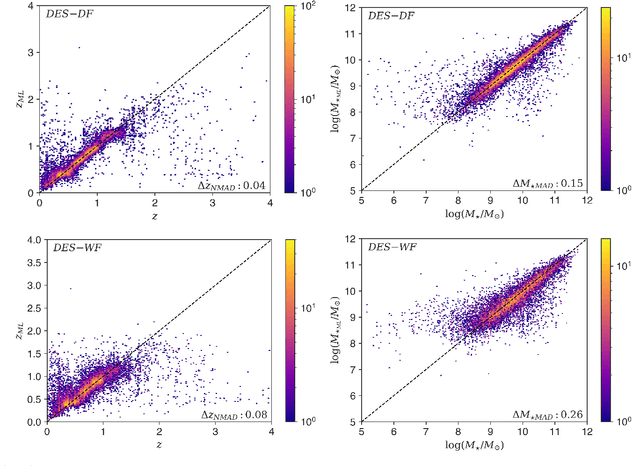

We demonstrate that highly accurate joint redshift - stellar mass PDFs can be obtained using the Random Forest (RF) machine learning (ML) algorithm, even with few photometric bands available. As an example, we use the Dark Energy Survey (DES), combined with the COSMOS2015 catalogue for redshifts and stellar masses. We build two ML models: one containing deep photometry in the $griz$ bands, and the second reflecting the photometric scatter present in the main DES survey, with carefully constructed representative training data in each case. We validate our joint PDFs for $10,699$ test galaxies by utilising the copula probability integral transform (copPIT) and the Kendall distribution function, and their univariate counterparts to validate the marginals. Benchmarked against a basic set-up of the template-fitting code BAGPIPES, our ML-based method outperforms template fitting on all of our pre-defined performance metrics. In addition to accuracy, the RF is extremely fast, able to compute joint PDFs for a million galaxies in just over $2$ hours with consumer computer hardware. Such speed enables PDFs to be derived in real-time within analysis codes, solving potential storage issues. As part of this work we have developed GALPRO, a highly intuitive and efficient Python package to rapidly generate multivariate PDFs on-the-fly. GALPRO is documented and available for researchers to use in their cosmology and galaxy evolution studies at https://galpro.readthedocs.io/.
Machine Learning for Searching the Dark Energy Survey for Trans-Neptunian Objects
Sep 27, 2020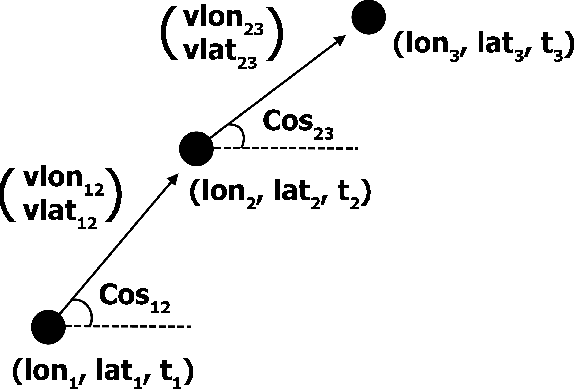

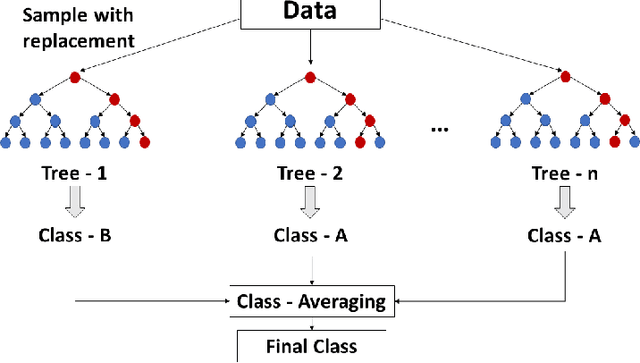
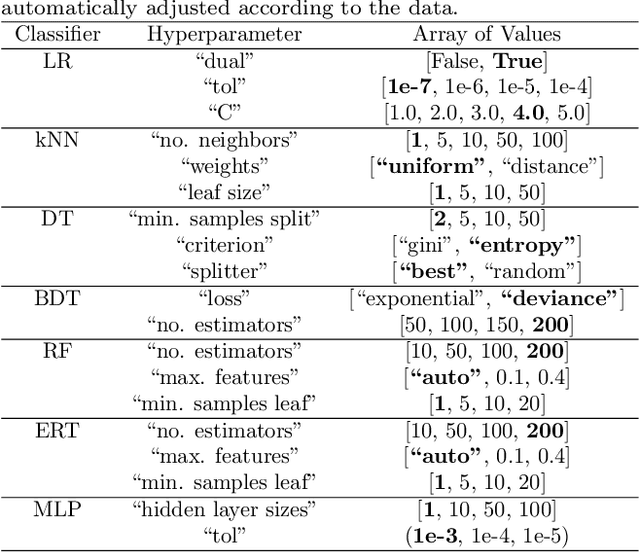
In this paper we investigate how implementing machine learning could improve the efficiency of the search for Trans-Neptunian Objects (TNOs) within Dark Energy Survey (DES) data when used alongside orbit fitting. The discovery of multiple TNOs that appear to show a similarity in their orbital parameters has led to the suggestion that one or more undetected planets, an as yet undiscovered "Planet 9", may be present in the outer Solar System. DES is well placed to detect such a planet and has already been used to discover many other TNOs. Here, we perform tests on eight different supervised machine learning algorithms, using a dataset consisting of simulated TNOs buried within real DES noise data. We found that the best performing classifier was the Random Forest which, when optimised, performed well at detecting the rare objects. We achieve an area under the receiver operating characteristic (ROC) curve, (AUC) $= 0.996 \pm 0.001$. After optimizing the decision threshold of the Random Forest, we achieve a recall of 0.96 while maintaining a precision of 0.80. Finally, by using the optimized classifier to pre-select objects, we are able to run the orbit-fitting stage of our detection pipeline five times faster.