 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDark Energy Survey Year 3 results: Simulation-based $w$CDM inference from weak lensing and galaxy clustering maps with deep learning. I. Analysis design
Nov 06, 2025Data-driven approaches using deep learning are emerging as powerful techniques to extract non-Gaussian information from cosmological large-scale structure. This work presents the first simulation-based inference (SBI) pipeline that combines weak lensing and galaxy clustering maps in a realistic Dark Energy Survey Year 3 (DES Y3) configuration and serves as preparation for a forthcoming analysis of the survey data. We develop a scalable forward model based on the CosmoGridV1 suite of N-body simulations to generate over one million self-consistent mock realizations of DES Y3 at the map level. Leveraging this large dataset, we train deep graph convolutional neural networks on the full survey footprint in spherical geometry to learn low-dimensional features that approximately maximize mutual information with target parameters. These learned compressions enable neural density estimation of the implicit likelihood via normalizing flows in a ten-dimensional parameter space spanning cosmological $w$CDM, intrinsic alignment, and linear galaxy bias parameters, while marginalizing over baryonic, photometric redshift, and shear bias nuisances. To ensure robustness, we extensively validate our inference pipeline using synthetic observations derived from both systematic contaminations in our forward model and independent Buzzard galaxy catalogs. Our forecasts yield significant improvements in cosmological parameter constraints, achieving $2-3\times$ higher figures of merit in the $\Omega_m - S_8$ plane relative to our implementation of baseline two-point statistics and effectively breaking parameter degeneracies through probe combination. These results demonstrate the potential of SBI analyses powered by deep learning for upcoming Stage-IV wide-field imaging surveys.
A machine learning approach to galaxy properties: Joint redshift - stellar mass probability distributions with Random Forest
Dec 10, 2020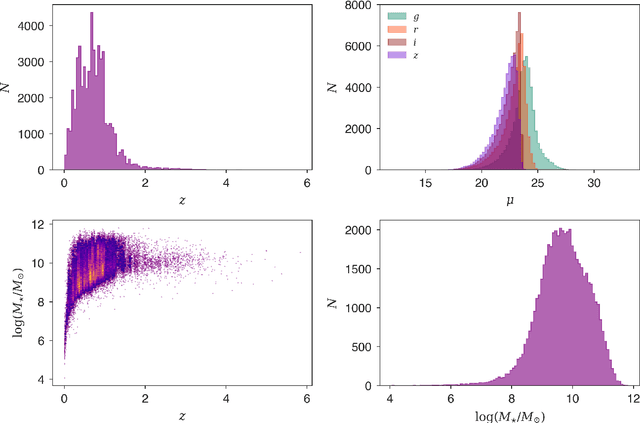

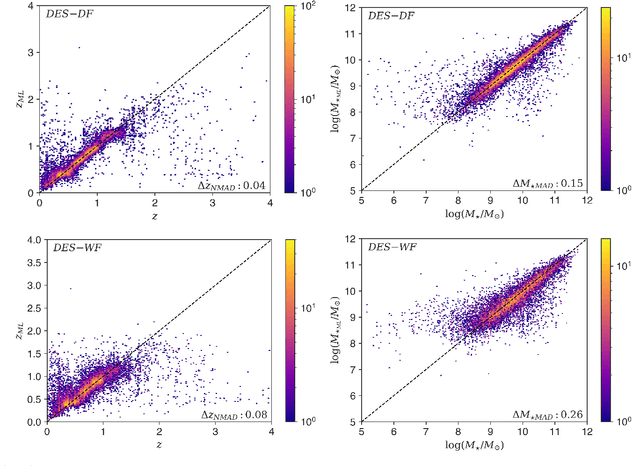

We demonstrate that highly accurate joint redshift - stellar mass PDFs can be obtained using the Random Forest (RF) machine learning (ML) algorithm, even with few photometric bands available. As an example, we use the Dark Energy Survey (DES), combined with the COSMOS2015 catalogue for redshifts and stellar masses. We build two ML models: one containing deep photometry in the $griz$ bands, and the second reflecting the photometric scatter present in the main DES survey, with carefully constructed representative training data in each case. We validate our joint PDFs for $10,699$ test galaxies by utilising the copula probability integral transform (copPIT) and the Kendall distribution function, and their univariate counterparts to validate the marginals. Benchmarked against a basic set-up of the template-fitting code BAGPIPES, our ML-based method outperforms template fitting on all of our pre-defined performance metrics. In addition to accuracy, the RF is extremely fast, able to compute joint PDFs for a million galaxies in just over $2$ hours with consumer computer hardware. Such speed enables PDFs to be derived in real-time within analysis codes, solving potential storage issues. As part of this work we have developed GALPRO, a highly intuitive and efficient Python package to rapidly generate multivariate PDFs on-the-fly. GALPRO is documented and available for researchers to use in their cosmology and galaxy evolution studies at https://galpro.readthedocs.io/.
Machine Learning for Searching the Dark Energy Survey for Trans-Neptunian Objects
Sep 27, 2020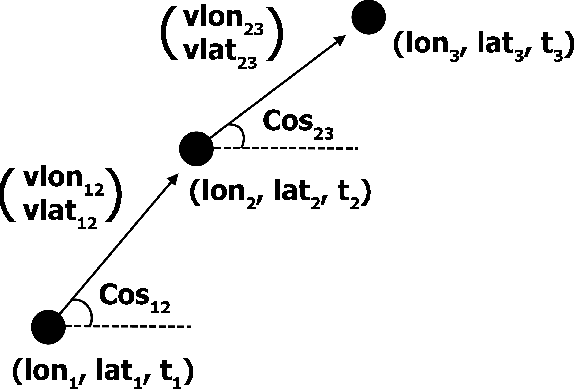

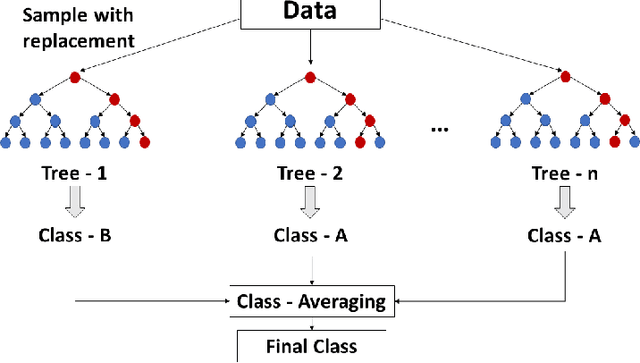
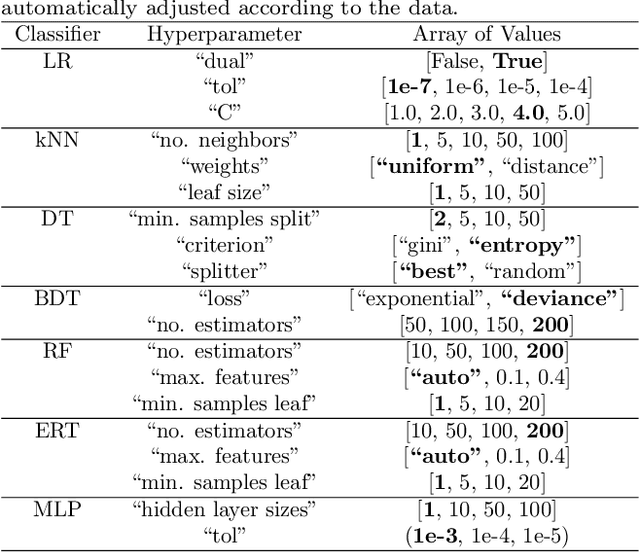
In this paper we investigate how implementing machine learning could improve the efficiency of the search for Trans-Neptunian Objects (TNOs) within Dark Energy Survey (DES) data when used alongside orbit fitting. The discovery of multiple TNOs that appear to show a similarity in their orbital parameters has led to the suggestion that one or more undetected planets, an as yet undiscovered "Planet 9", may be present in the outer Solar System. DES is well placed to detect such a planet and has already been used to discover many other TNOs. Here, we perform tests on eight different supervised machine learning algorithms, using a dataset consisting of simulated TNOs buried within real DES noise data. We found that the best performing classifier was the Random Forest which, when optimised, performed well at detecting the rare objects. We achieve an area under the receiver operating characteristic (ROC) curve, (AUC) $= 0.996 \pm 0.001$. After optimizing the decision threshold of the Random Forest, we achieve a recall of 0.96 while maintaining a precision of 0.80. Finally, by using the optimized classifier to pre-select objects, we are able to run the orbit-fitting stage of our detection pipeline five times faster.