 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Personalized Age Estimation
Apr 10, 2026Existing age estimation methods treat each face as an independent sample, learning a global mapping from appearance to age. This ignores a well-documented phenomenon: individuals age at different rates due to genetics, lifestyle, and health, making the mapping from face to age identity-dependent. When reference images of the same person with known ages are available, we can exploit this context to personalize the estimate. The only existing benchmark for this task (NIST FRVT) is closed-source and limited to a single reference image. In this work, we introduce OpenPAE, the first open benchmark for $N$-shot personalized age estimation with strict evaluation protocols. We establish a hierarchy of increasingly sophisticated baselines: from arithmetic offset, through closed-form Bayesian linear regression, to a conditional attentive neural process. Our experiments show that personalization consistently improves performance, that the gains are not merely domain adaptation, and that nonlinear methods significantly outperform simpler alternatives. We release all models, code, protocols, and evaluation splits.
On Model Evaluation under Non-constant Class Imbalance
Jan 15, 2020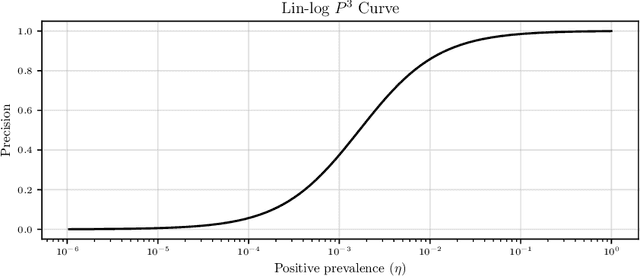
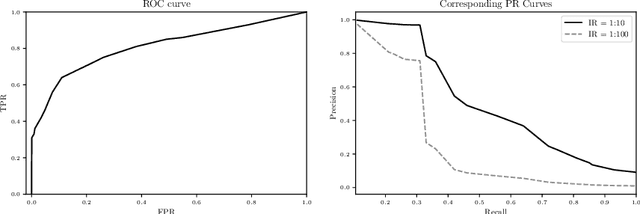
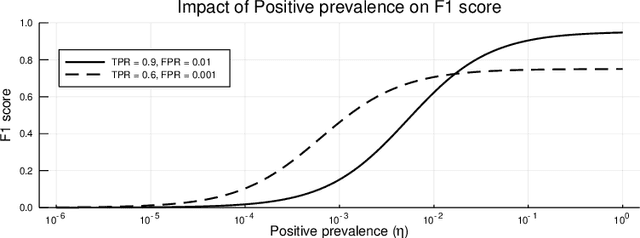
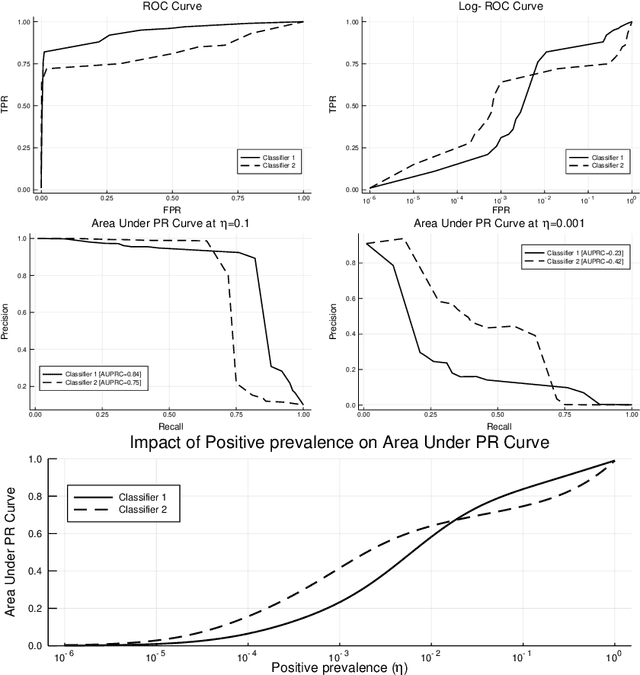
Many real-world classification problems are significantly class-imbalanced to detriment of the class of interest. The standard set of proper evaluation metrics is well-known but the usual assumption is that the test dataset imbalance equals the real-world imbalance. In practice, this assumption is often broken for various reasons. The reported results are then often too optimistic and may lead to wrong conclusions about industrial impact and suitability of proposed techniques. We introduce methods focusing on evaluation under non-constant class imbalance. We show that not only the absolute values of commonly used metrics, but even the order of classifiers in relation to the evaluation metric used is affected by the change of the imbalance rate. Finally, we demonstrate that using subsampling in order to get a test dataset with class imbalance equal to the one observed in the wild is not necessary, and eventually can lead to significant errors in classifier's performance estimate.