 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative analysis of criteria for filtering time series of word usage frequencies
Dec 10, 2017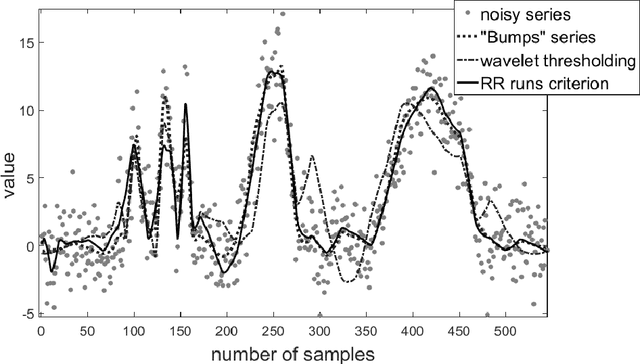
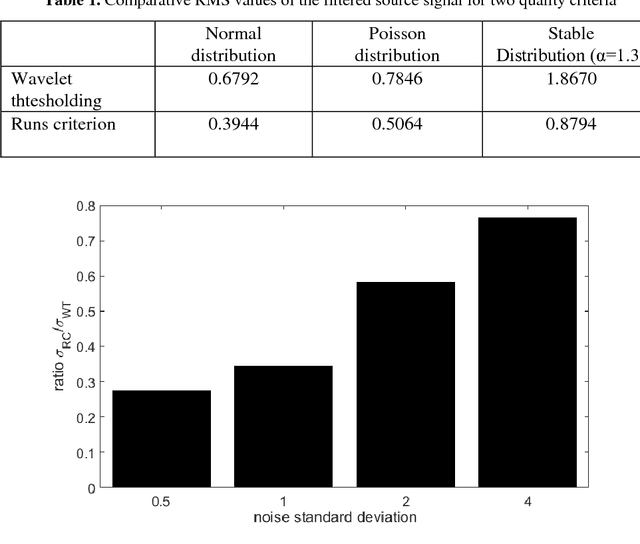
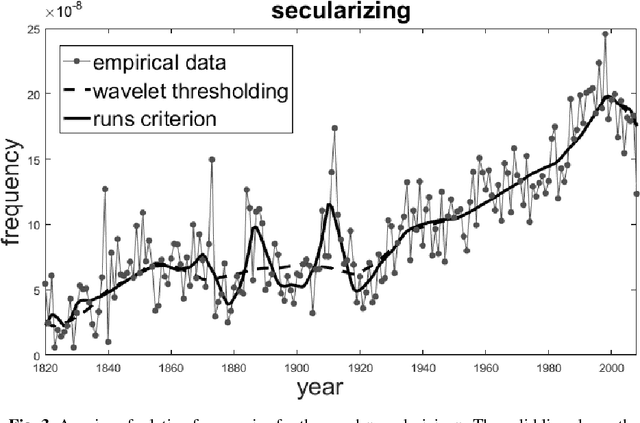
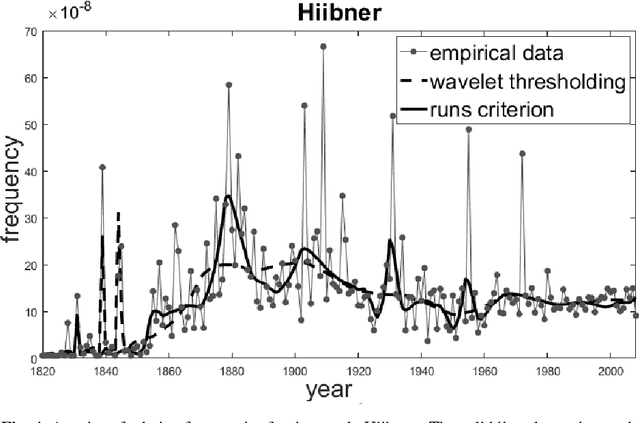
This paper describes a method of nonlinear wavelet thresholding of time series. The Ramachandran-Ranganathan runs test is used to assess the quality of approximation. To minimize the objective function, it is proposed to use genetic algorithms - one of the stochastic optimization methods. The suggested method is tested both on the model series and on the word frequency series using the Google Books Ngram data. It is shown that method of filtering which uses the runs criterion shows significantly better results compared with the standard wavelet thresholding. The method can be used when quality of filtering is of primary importance but not the speed of calculations.
Dynamics of core of language vocabulary
May 29, 2017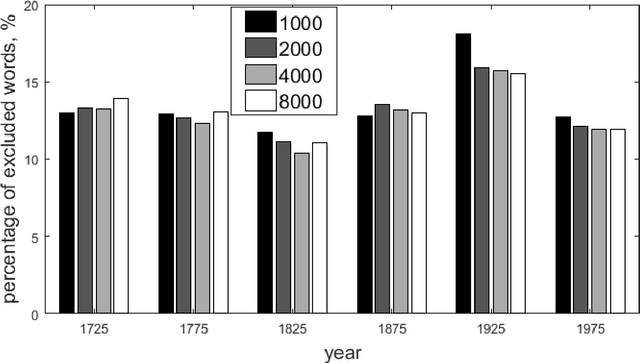
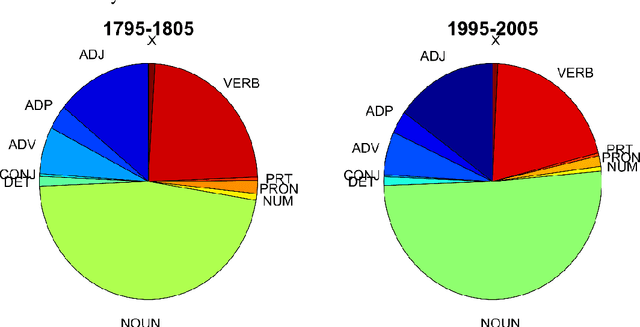
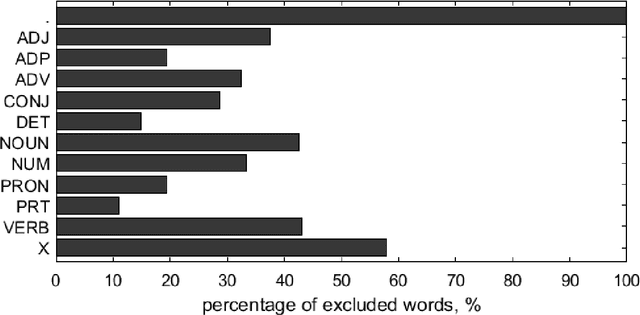
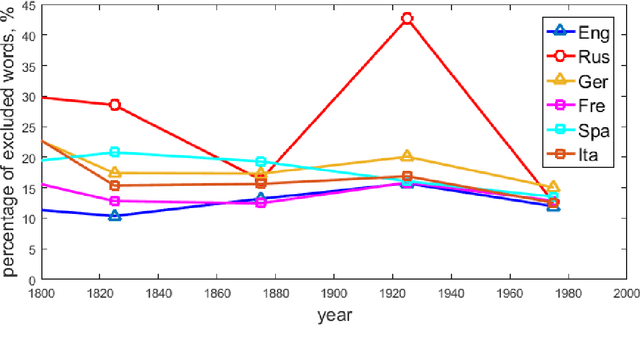
Studies of the overall structure of vocabulary and its dynamics became possible due to creation of diachronic text corpora, especially Google Books Ngram. This article discusses the question of core change rate and the degree to which the core words cover the texts. Different periods of the last three centuries and six main European languages presented in Google Books Ngram are compared. The main result is high stability of core change rate, which is analogous to stability of the Swadesh list.
Verifying Heaps' law using Google Books Ngram data
Dec 29, 2016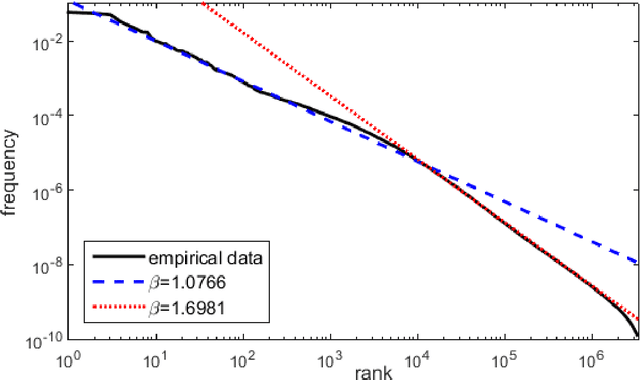
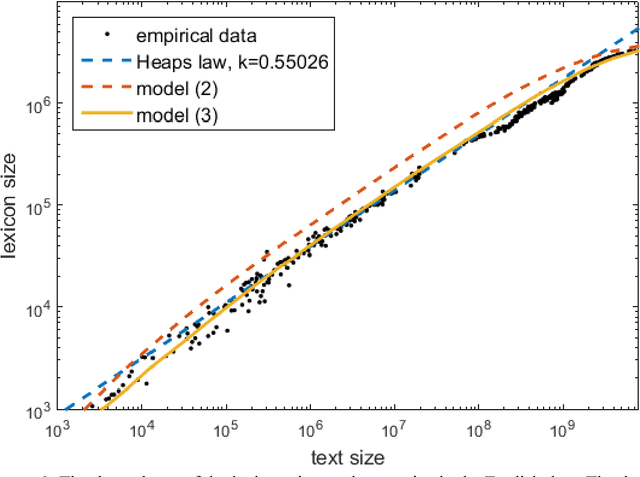
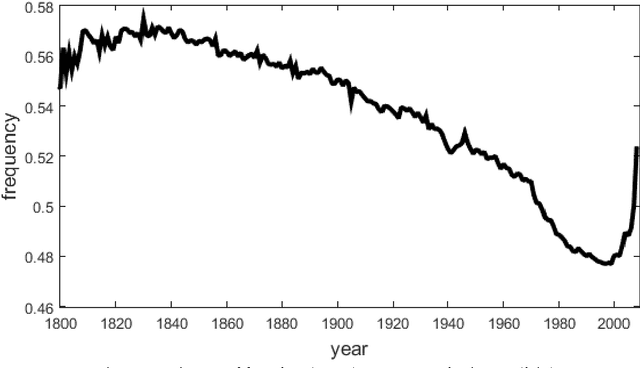
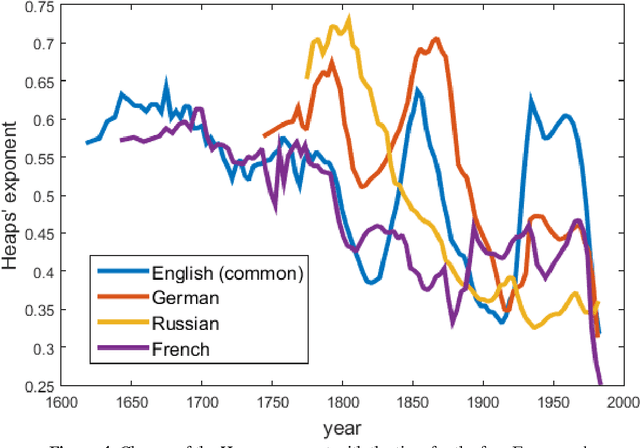
This article is devoted to the verification of the empirical Heaps law in European languages using Google Books Ngram corpus data. The connection between word distribution frequency and expected dependence of individual word number on text size is analysed in terms of a simple probability model of text generation. It is shown that the Heaps exponent varies significantly within characteristic time intervals of 60-100 years.
Initialization of multilayer forecasting artifical neural networks
Oct 23, 2014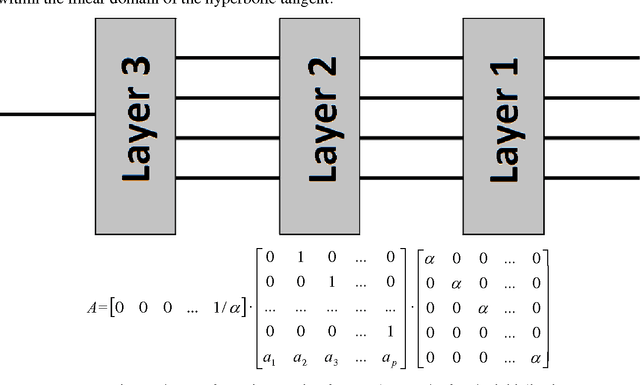


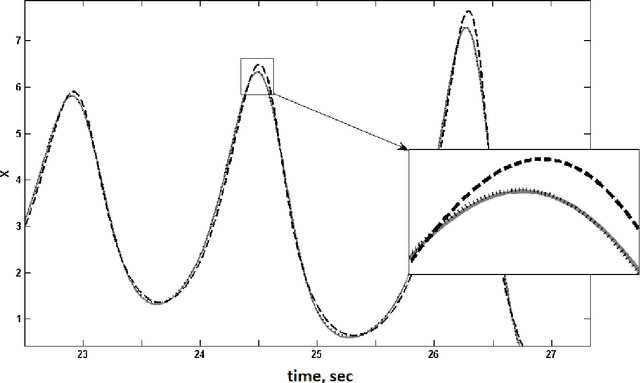
In this paper, a new method was developed for initialising artificial neural networks predicting dynamics of time series. Initial weighting coefficients were determined for neurons analogously to the case of a linear prediction filter. Moreover, to improve the accuracy of the initialization method for a multilayer neural network, some variants of decomposition of the transformation matrix corresponding to the linear prediction filter were suggested. The efficiency of the proposed neural network prediction method by forecasting solutions of the Lorentz chaotic system is shown in this paper.
* 9 pages, 3 figures
Training Algorithm for Neuro-Fuzzy Network Based on Singular Spectrum Analysis
Oct 05, 2014


In this article, we propose a combination of an noise-reduction algorithm based on Singular Spectrum Analysis (SSA) and a standard feedforward neural prediction model. Basically, the proposed algorithm consists of two different steps: data preprocessing based on the SSA filtering method and step-by-step training procedure in which we use a simple feedforward multilayer neural network with backpropagation learning. The proposed noise-reduction procedure successfully removes most of the noise. That increases long-term predictability of the processed dataset comparison with the raw dataset. The method was applied to predict the International sunspot number RZ time series. The results show that our combined technique has better performances than those offered by the same network directly applied to raw dataset.
Generating abbreviations using Google Books library
Oct 04, 2014


The article describes the original method of creating a dictionary of abbreviations based on the Google Books Ngram Corpus. The dictionary of abbreviations is designed for Russian, yet as its methodology is universal it can be applied to any language. The dictionary can be used to define the function of the period during text segmentation in various applied systems of text processing. The article describes difficulties encountered in the process of its construction as well as the ways to overcome them. A model of evaluating a probability of first and second type errors (extraction accuracy and fullness) is constructed. Certain statistical data for the use of abbreviations are provided.
Average word length dynamics as indicator of cultural changes in society
Aug 30, 2012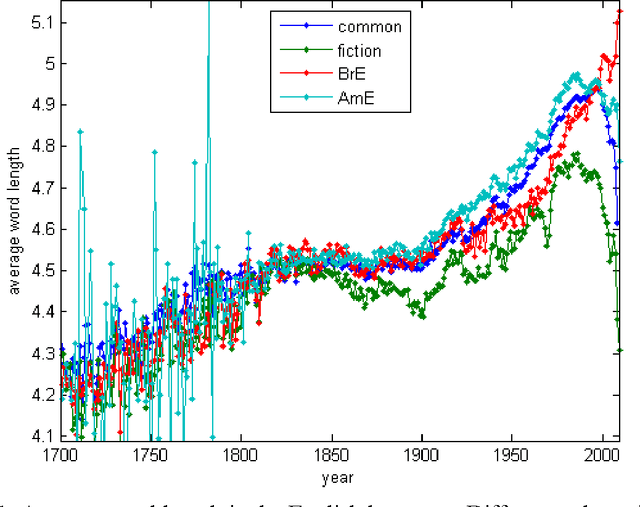
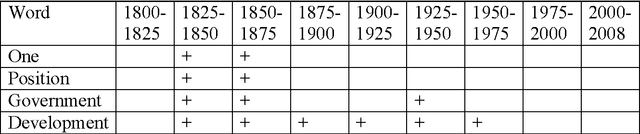
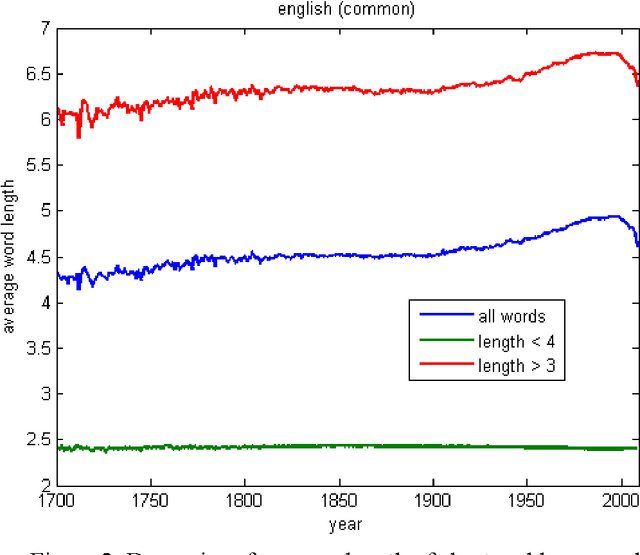
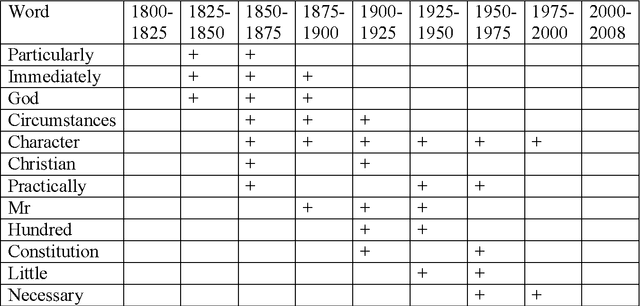
Dynamics of average length of words in Russian and English is analysed in the article. Words belonging to the diachronic text corpus Google Books Ngram and dated back to the last two centuries are studied. It was found out that average word length slightly increased in the 19th century, and then it was growing rapidly most of the 20th century and started decreasing over the period from the end of the 20th - to the beginning of the 21th century. Words which contributed mostly to increase or decrease of word average length were identified. At that, content words and functional words are analysed separately. Long content words contribute mostly to word average length of word. As it was shown, these words reflect the main tendencies of social development and thus, are used frequently. Change of frequency of personal pronouns also contributes significantly to change of average word length. The other parameters connected with average length of word were also analysed.
* 16 pages, 9 figures