 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamics of core of language vocabulary
May 29, 2017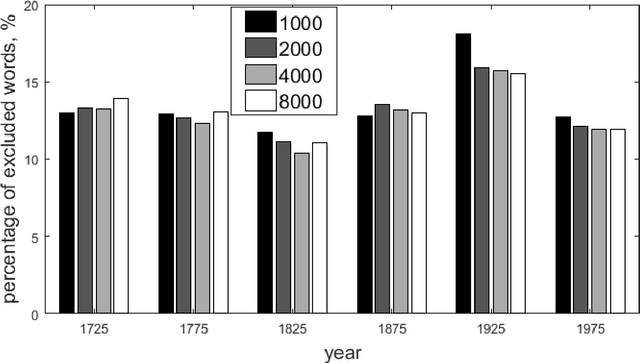
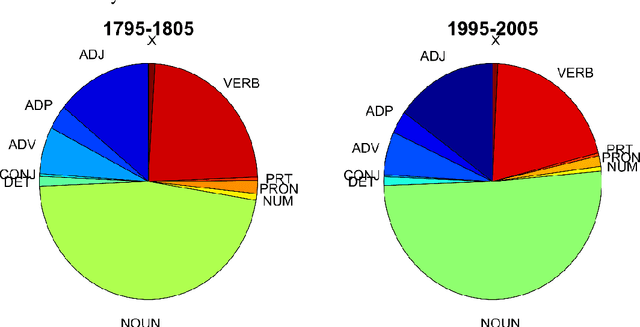
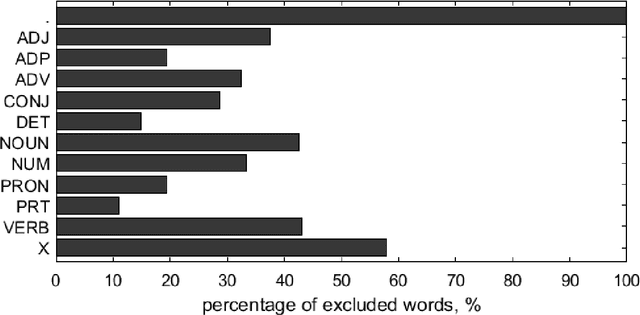
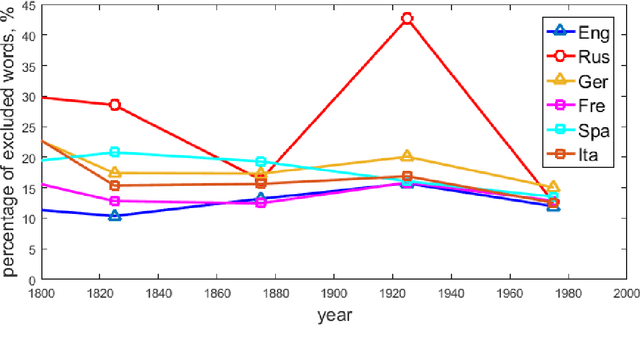
Studies of the overall structure of vocabulary and its dynamics became possible due to creation of diachronic text corpora, especially Google Books Ngram. This article discusses the question of core change rate and the degree to which the core words cover the texts. Different periods of the last three centuries and six main European languages presented in Google Books Ngram are compared. The main result is high stability of core change rate, which is analogous to stability of the Swadesh list.
Verifying Heaps' law using Google Books Ngram data
Dec 29, 2016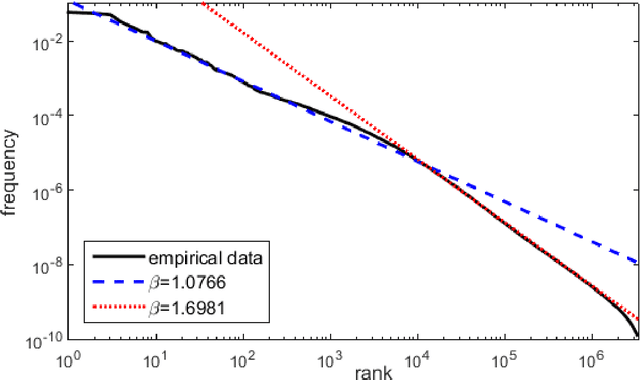
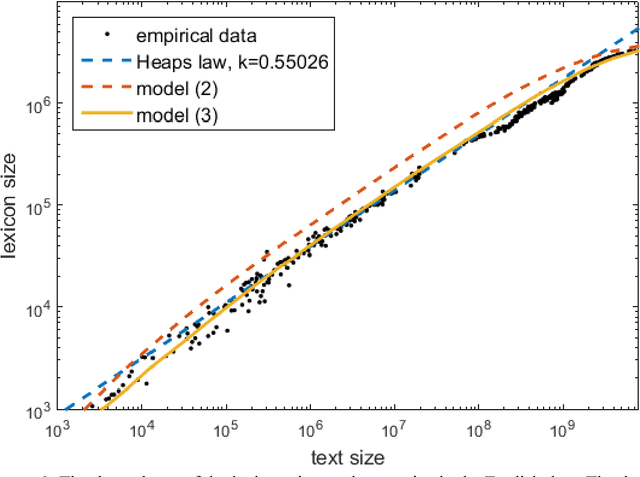
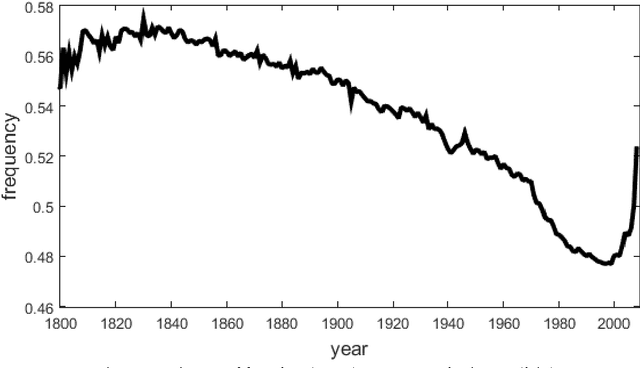
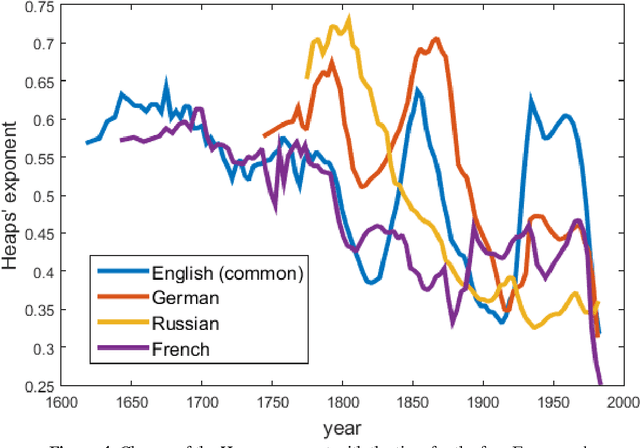
This article is devoted to the verification of the empirical Heaps law in European languages using Google Books Ngram corpus data. The connection between word distribution frequency and expected dependence of individual word number on text size is analysed in terms of a simple probability model of text generation. It is shown that the Heaps exponent varies significantly within characteristic time intervals of 60-100 years.
Average word length dynamics as indicator of cultural changes in society
Aug 30, 2012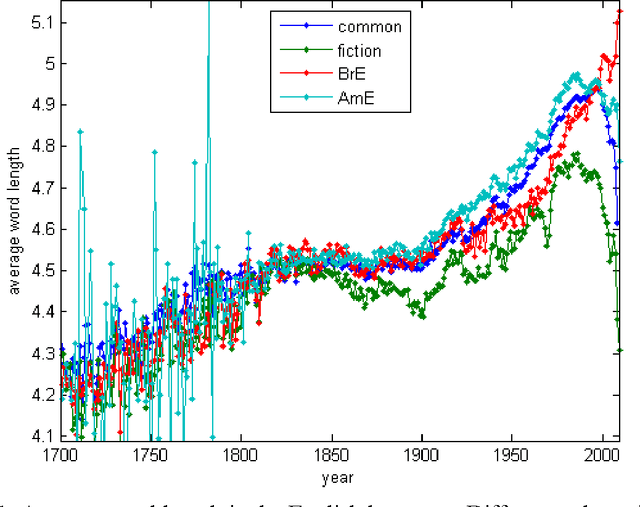
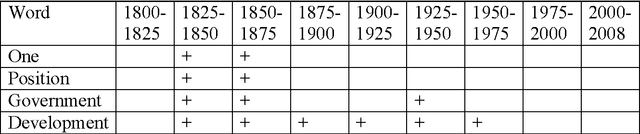
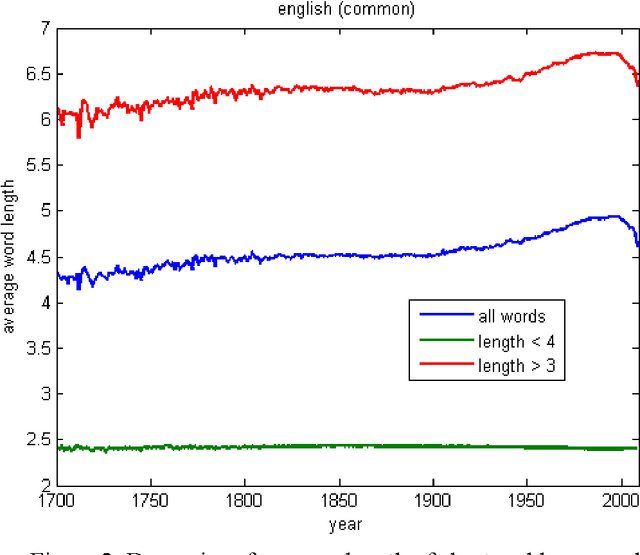
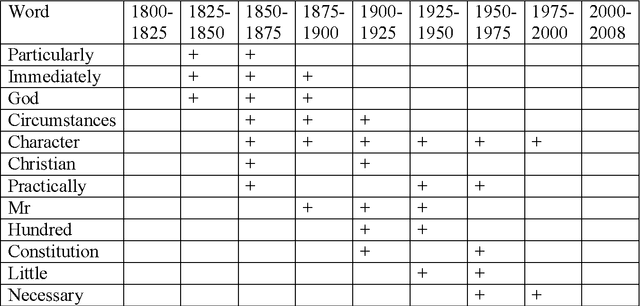
Dynamics of average length of words in Russian and English is analysed in the article. Words belonging to the diachronic text corpus Google Books Ngram and dated back to the last two centuries are studied. It was found out that average word length slightly increased in the 19th century, and then it was growing rapidly most of the 20th century and started decreasing over the period from the end of the 20th - to the beginning of the 21th century. Words which contributed mostly to increase or decrease of word average length were identified. At that, content words and functional words are analysed separately. Long content words contribute mostly to word average length of word. As it was shown, these words reflect the main tendencies of social development and thus, are used frequently. Change of frequency of personal pronouns also contributes significantly to change of average word length. The other parameters connected with average length of word were also analysed.
* 16 pages, 9 figures