 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Two-Stage Subspace Trust Region Approach for Deep Neural Network Training
May 23, 2018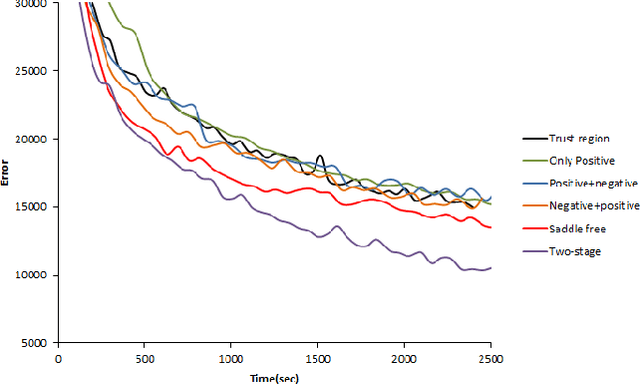
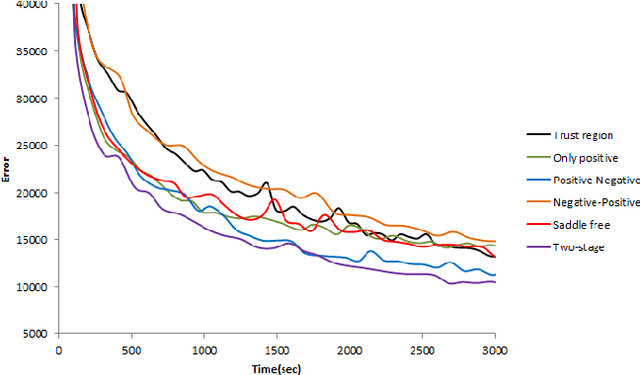
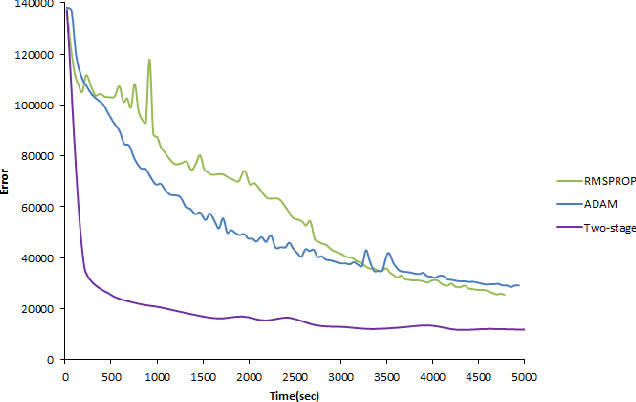
In this paper, we develop a novel second-order method for training feed-forward neural nets. At each iteration, we construct a quadratic approximation to the cost function in a low-dimensional subspace. We minimize this approximation inside a trust region through a two-stage procedure: first inside the embedded positive curvature subspace, followed by a gradient descent step. This approach leads to a fast objective function decay, prevents convergence to saddle points, and alleviates the need for manually tuning parameters. We show the good performance of the proposed algorithm on benchmark datasets.
Use of symmetric kernels for convolutional neural networks
May 23, 2018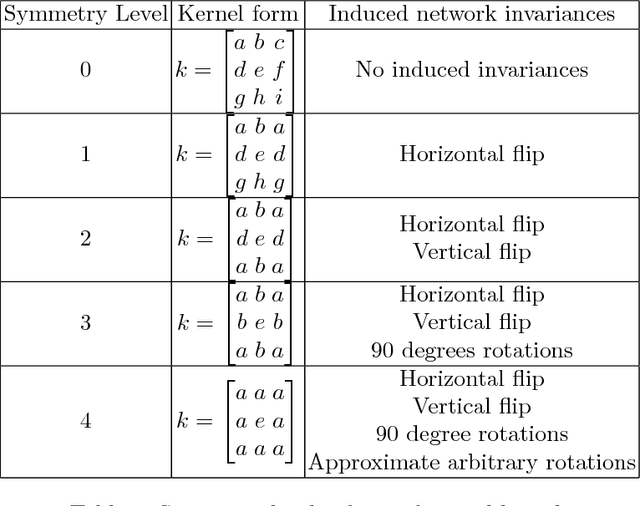
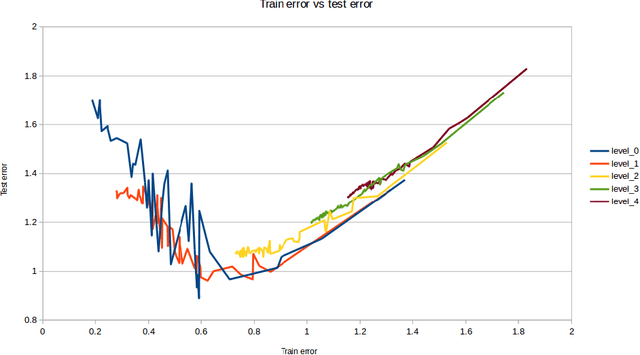

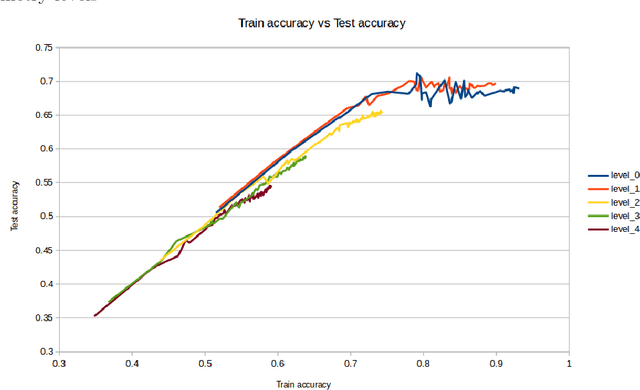
At this work we introduce horizontally symmetric convolutional kernels for CNNs which make the network output invariant to horizontal flips of the image. We also study other types of symmetric kernels which lead to vertical flip invariance, and approximate rotational invariance. We show that usage of such kernels acts as regularizer, and improves generalization of the convolutional neural networks at the cost of more complicated training process.