 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNP-SemiSeg: When Neural Processes meet Semi-Supervised Semantic Segmentation
Aug 05, 2023



Semi-supervised semantic segmentation involves assigning pixel-wise labels to unlabeled images at training time. This is useful in a wide range of real-world applications where collecting pixel-wise labels is not feasible in time or cost. Current approaches to semi-supervised semantic segmentation work by predicting pseudo-labels for each pixel from a class-wise probability distribution output by a model. If the predicted probability distribution is incorrect, however, this leads to poor segmentation results, which can have knock-on consequences in safety critical systems, like medical images or self-driving cars. It is, therefore, important to understand what a model does not know, which is mainly achieved by uncertainty quantification. Recently, neural processes (NPs) have been explored in semi-supervised image classification, and they have been a computationally efficient and effective method for uncertainty quantification. In this work, we move one step forward by adapting NPs to semi-supervised semantic segmentation, resulting in a new model called NP-SemiSeg. We experimentally evaluated NP-SemiSeg on the public benchmarks PASCAL VOC 2012 and Cityscapes, with different training settings, and the results verify its effectiveness.
Learning from Synthetic Human Group Activities
Jul 16, 2023



The understanding of complex human interactions and group activities has garnered attention in human-centric computer vision. However, the advancement of the related tasks is hindered due to the difficulty of obtaining large-scale labeled real-world datasets. To mitigate the issue, we propose M3Act, a multi-view multi-group multi-person human atomic action and group activity data generator. Powered by the Unity engine, M3Act contains simulation-ready 3D scenes and human assets, configurable lighting and camera systems, highly parameterized modular group activities, and a large degree of domain randomization during the data generation process. Our data generator is capable of generating large-scale datasets of human activities with multiple viewpoints, modalities (RGB images, 2D poses, 3D motions), and high-quality annotations for individual persons and multi-person groups (2D bounding boxes, instance segmentation masks, individual actions and group activity categories). Using M3Act, we perform synthetic data pre-training for 2D skeleton-based group activity recognition and RGB-based multi-person pose tracking. The results indicate that learning from our synthetic datasets largely improves the model performances on real-world datasets, with the highest gain of 5.59% and 7.32% respectively in group and person recognition accuracy on CAD2, as well as an improvement of 6.63 in MOTP on HiEve. Pre-training with our synthetic data also leads to faster model convergence on downstream tasks (up to 6.8% faster). Moreover, M3Act opens new research problems for 3D group activity generation. We release M3Act3D, an 87.6-hour 3D motion dataset of human activities with larger group sizes and higher complexity of inter-person interactions than previous multi-person datasets. We define multiple metrics and propose a competitive baseline for the novel task.
MSI: Maximize Support-Set Information for Few-Shot Segmentation
Dec 09, 2022



FSS(Few-shot segmentation)~aims to segment a target class with a small number of labeled images (support Set). To extract information relevant to target class, a dominant approach in best performing FSS baselines removes background features using support mask. We observe that this support mask presents an information bottleneck in several challenging FSS cases e.g., for small targets and/or inaccurate target boundaries. To this end, we present a novel method (MSI), which maximizes the support-set information by exploiting two complementary source of features in generating super correlation maps. We validate the effectiveness of our approach by instantiating it into three recent and strong FSS baselines. Experimental results on several publicly available FSS benchmarks show that our proposed method consistently improves the performance by visible margins and allows faster convergence. Our codes and models will be publicly released.
D2DF2WOD: Learning Object Proposals for Weakly-Supervised Object Detection via Progressive Domain Adaptation
Dec 02, 2022



Weakly-supervised object detection (WSOD) models attempt to leverage image-level annotations in lieu of accurate but costly-to-obtain object localization labels. This oftentimes leads to substandard object detection and localization at inference time. To tackle this issue, we propose D2DF2WOD, a Dual-Domain Fully-to-Weakly Supervised Object Detection framework that leverages synthetic data, annotated with precise object localization, to supplement a natural image target domain, where only image-level labels are available. In its warm-up domain adaptation stage, the model learns a fully-supervised object detector (FSOD) to improve the precision of the object proposals in the target domain, and at the same time learns target-domain-specific and detection-aware proposal features. In its main WSOD stage, a WSOD model is specifically tuned to the target domain. The feature extractor and the object proposal generator of the WSOD model are built upon the fine-tuned FSOD model. We test D2DF2WOD on five dual-domain image benchmarks. The results show that our method results in consistently improved object detection and localization compared with state-of-the-art methods.
An Information-Theoretic Approach for Estimating Scenario Generalization in Crowd Motion Prediction
Nov 02, 2022



Learning-based approaches to modeling crowd motion have become increasingly successful but require training and evaluation on large datasets, coupled with complex model selection and parameter tuning. To circumvent this tremendously time-consuming process, we propose a novel scoring method, which characterizes generalization of models trained on source crowd scenarios and applied to target crowd scenarios using a training-free, model-agnostic Interaction + Diversity Quantification score, ISDQ. The Interaction component aims to characterize the difficulty of scenario domains, while the diversity of a scenario domain is captured in the Diversity score. Both scores can be computed in a computation tractable manner. Our experimental results validate the efficacy of the proposed method on several simulated and real-world (source,target) generalization tasks, demonstrating its potential to select optimal domain pairs before training and testing a model.
Visual Semantic Parsing: From Images to Abstract Meaning Representation
Oct 27, 2022The success of scene graphs for visual scene understanding has brought attention to the benefits of abstracting a visual input (e.g., image) into a structured representation, where entities (people and objects) are nodes connected by edges specifying their relations. Building these representations, however, requires expensive manual annotation in the form of images paired with their scene graphs or frames. These formalisms remain limited in the nature of entities and relations they can capture. In this paper, we propose to leverage a widely-used meaning representation in the field of natural language processing, the Abstract Meaning Representation (AMR), to address these shortcomings. Compared to scene graphs, which largely emphasize spatial relationships, our visual AMR graphs are more linguistically informed, with a focus on higher-level semantic concepts extrapolated from visual input. Moreover, they allow us to generate meta-AMR graphs to unify information contained in multiple image descriptions under one representation. Through extensive experimentation and analysis, we demonstrate that we can re-purpose an existing text-to-AMR parser to parse images into AMRs. Our findings point to important future research directions for improved scene understanding.
NP-Match: When Neural Processes meet Semi-Supervised Learning
Jul 03, 2022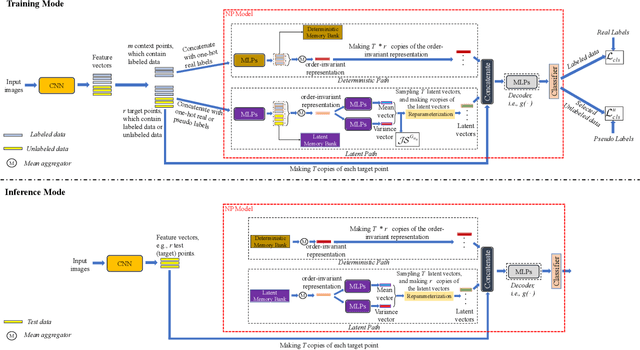
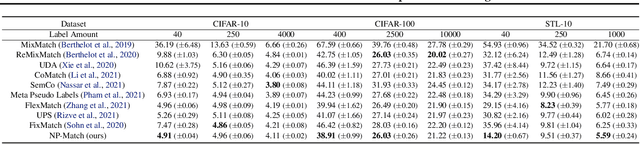
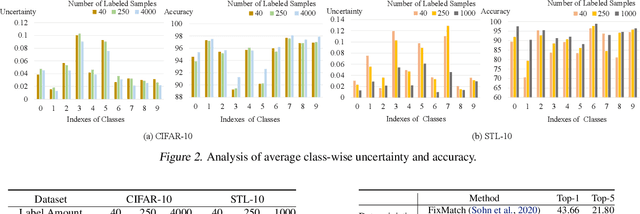
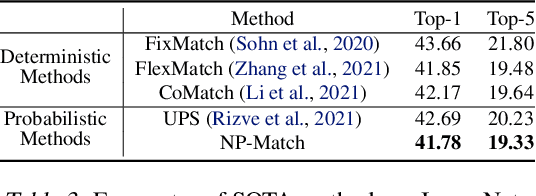
Semi-supervised learning (SSL) has been widely explored in recent years, and it is an effective way of leveraging unlabeled data to reduce the reliance on labeled data. In this work, we adjust neural processes (NPs) to the semi-supervised image classification task, resulting in a new method named NP-Match. NP-Match is suited to this task for two reasons. Firstly, NP-Match implicitly compares data points when making predictions, and as a result, the prediction of each unlabeled data point is affected by the labeled data points that are similar to it, which improves the quality of pseudo-labels. Secondly, NP-Match is able to estimate uncertainty that can be used as a tool for selecting unlabeled samples with reliable pseudo-labels. Compared with uncertainty-based SSL methods implemented with Monte Carlo (MC) dropout, NP-Match estimates uncertainty with much less computational overhead, which can save time at both the training and the testing phases. We conducted extensive experiments on four public datasets, and NP-Match outperforms state-of-the-art (SOTA) results or achieves competitive results on them, which shows the effectiveness of NP-Match and its potential for SSL.
SAViR-T: Spatially Attentive Visual Reasoning with Transformers
Jun 22, 2022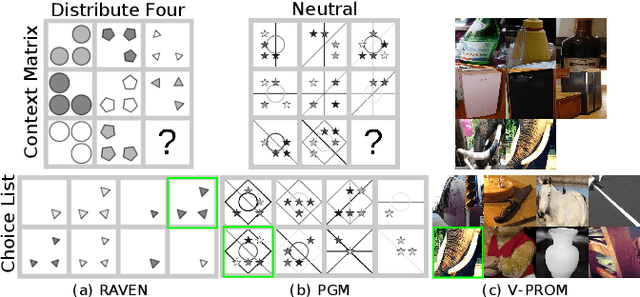
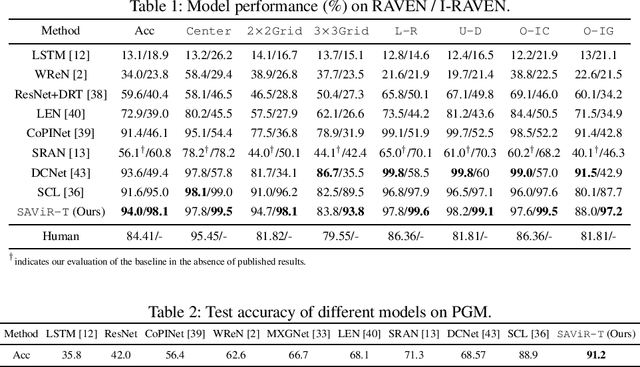
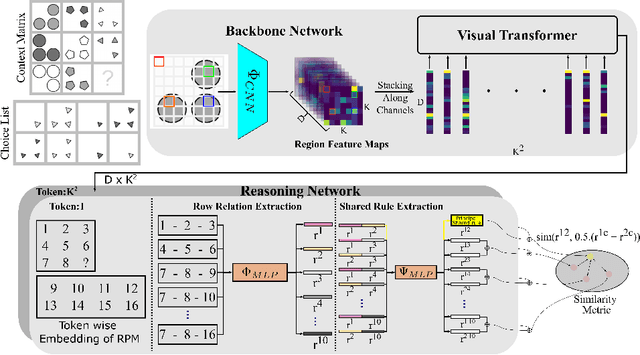
We present a novel computational model, "SAViR-T", for the family of visual reasoning problems embodied in the Raven's Progressive Matrices (RPM). Our model considers explicit spatial semantics of visual elements within each image in the puzzle, encoded as spatio-visual tokens, and learns the intra-image as well as the inter-image token dependencies, highly relevant for the visual reasoning task. Token-wise relationship, modeled through a transformer-based SAViR-T architecture, extract group (row or column) driven representations by leveraging the group-rule coherence and use this as the inductive bias to extract the underlying rule representations in the top two row (or column) per token in the RPM. We use this relation representations to locate the correct choice image that completes the last row or column for the RPM. Extensive experiments across both synthetic RPM benchmarks, including RAVEN, I-RAVEN, RAVEN-FAIR, and PGM, and the natural image-based "V-PROM" demonstrate that SAViR-T sets a new state-of-the-art for visual reasoning, exceeding prior models' performance by a considerable margin.
HMFS: Hybrid Masking for Few-Shot Segmentation
Mar 24, 2022
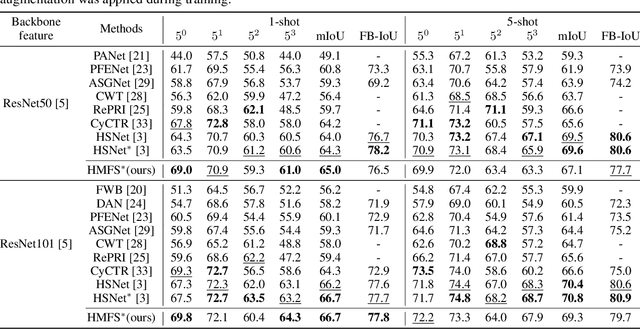
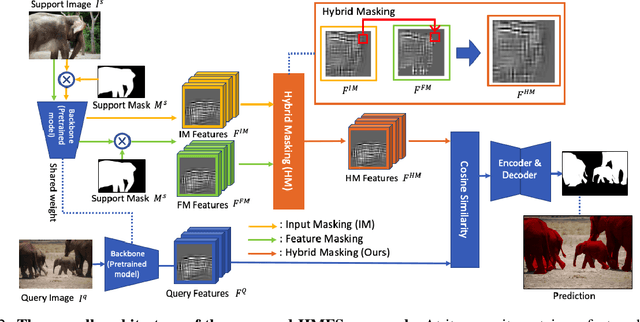
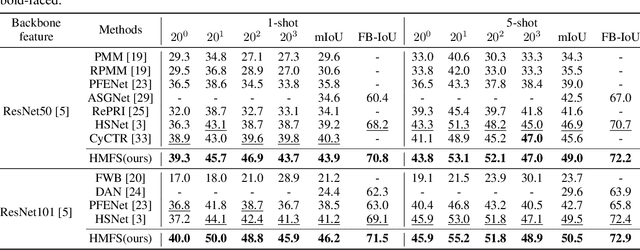
We study few-shot semantic segmentation that aims to segment a target object from a query image when provided with a few annotated support images of the target class. Several recent methods resort to a feature masking (FM) technique, introduced by [1], to discard irrelevant feature activations to facilitate reliable segmentation mask prediction. A fundamental limitation of FM is the inability to preserve the fine-grained spatial details that affect the accuracy of segmentation mask, especially for small target objects. In this paper, we develop a simple, effective, and efficient approach to enhance feature masking (FM). We dub the enhanced FM as hybrid masking (HM). Specifically, we compensate for the loss of fine-grained spatial details in FM technique by investigating and leveraging a complementary basic input masking method [2]. To validate the effectiveness of HM, we instantiate it into a strong baseline [3], and coin the resulting framework as HMFS. Experimental results on three publicly available benchmarks reveal that HMFS outperforms the current state-of-the-art methods by visible margins.
MUSE-VAE: Multi-Scale VAE for Environment-Aware Long Term Trajectory Prediction
Jan 18, 2022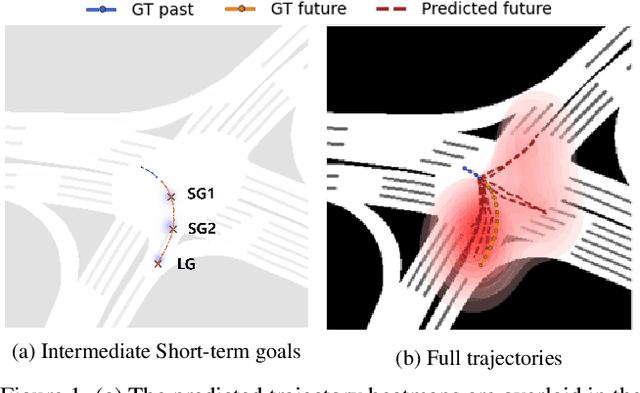
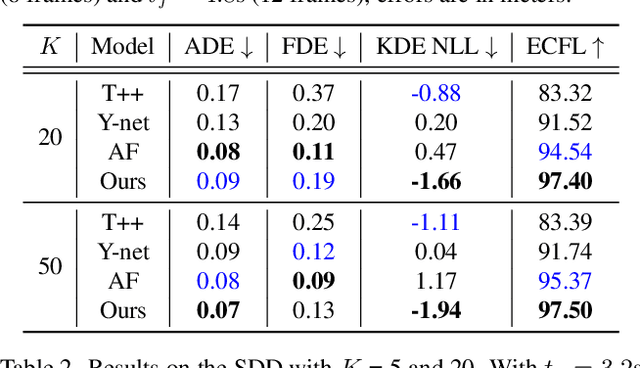
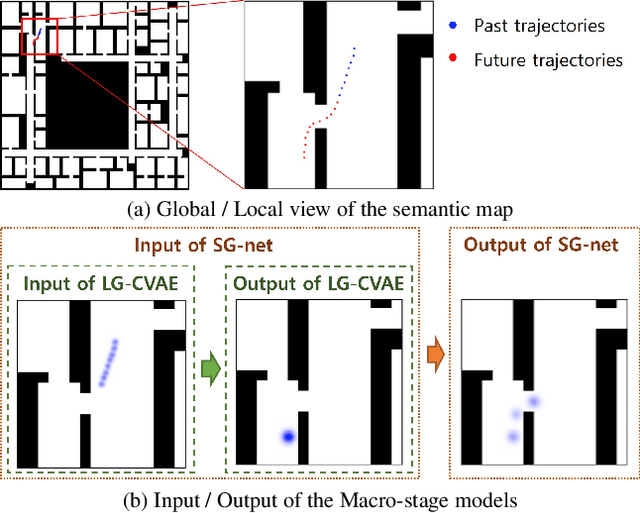
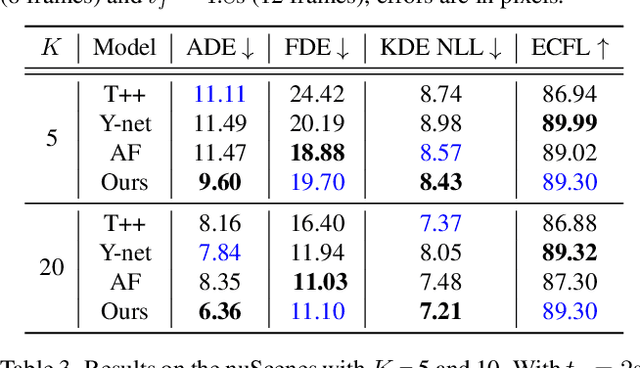
Accurate long-term trajectory prediction in complex scenes, where multiple agents (e.g., pedestrians or vehicles) interact with each other and the environment while attempting to accomplish diverse and often unknown goals, is a challenging stochastic forecasting problem. In this work, we propose MUSE, a new probabilistic modeling framework based on a cascade of Conditional VAEs, which tackles the long-term, uncertain trajectory prediction task using a coarse-to-fine multi-factor forecasting architecture. In its Macro stage, the model learns a joint pixel-space representation of two key factors, the underlying environment and the agent movements, to predict the long and short-term motion goals. Conditioned on them, the Micro stage learns a fine-grained spatio-temporal representation for the prediction of individual agent trajectories. The VAE backbones across the two stages make it possible to naturally account for the joint uncertainty at both levels of granularity. As a result, MUSE offers diverse and simultaneously more accurate predictions compared to the current state-of-the-art. We demonstrate these assertions through a comprehensive set of experiments on nuScenes and SDD benchmarks as well as PFSD, a new synthetic dataset, which challenges the forecasting ability of models on complex agent-environment interaction scenarios.