 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised 3D Segmentation for Type-B Aortic Dissection with Slim UNETR
Dec 19, 2025



Convolutional neural networks (CNN) for multi-class segmentation of medical images are widely used today. Especially models with multiple outputs that can separately predict segmentation classes (regions) without relying on a probabilistic formulation of the segmentation of regions. These models allow for more precise segmentation by tailoring the network's components to each class (region). They have a common encoder part of the architecture but branch out at the output layers, leading to improved accuracy. These methods are used to diagnose type B aortic dissection (TBAD), which requires accurate segmentation of aortic structures based on the ImageTBDA dataset, which contains 100 3D computed tomography angiography (CTA) images. These images identify three key classes: true lumen (TL), false lumen (FL), and false lumen thrombus (FLT) of the aorta, which is critical for diagnosis and treatment decisions. In the dataset, 68 examples have a false lumen, while the remaining 32 do not, creating additional complexity for pathology detection. However, implementing these CNN methods requires a large amount of high-quality labeled data. Obtaining accurate labels for the regions of interest can be an expensive and time-consuming process, particularly for 3D data. Semi-supervised learning methods allow models to be trained by using both labeled and unlabeled data, which is a promising approach for overcoming the challenge of obtaining accurate labels. However, these learning methods are not well understood for models with multiple outputs. This paper presents a semi-supervised learning method for models with multiple outputs. The method is based on the additional rotations and flipping, and does not assume the probabilistic nature of the model's responses. This makes it a universal approach, which is especially important for architectures that involve separate segmentation.
Weakly supervised semantic segmentation of tomographic images in the diagnosis of stroke
Sep 04, 2021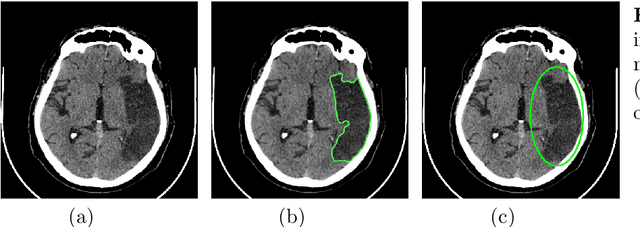



This paper presents an automatic algorithm for the segmentation of areas affected by an acute stroke on the non-contrast computed tomography brain images. The proposed algorithm is designed for learning in a weakly supervised scenario when some images are labeled accurately, and some images are labeled inaccurately. Wrong labels appear as a result of inaccuracy made by a radiologist in the process of manual annotation of computed tomography images. We propose methods for solving the segmentation problem in the case of inaccurately labeled training data. We use the U-Net neural network architecture with several modifications. Experiments on real computed tomography scans show that the proposed methods increase the segmentation accuracy.
Solving weakly supervised regression problem using low-rank manifold regularization
Apr 13, 2021


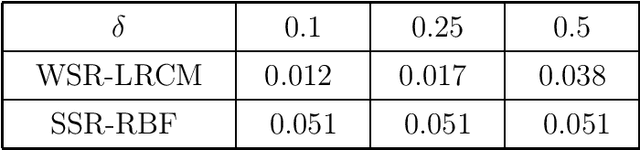
We solve a weakly supervised regression problem. Under "weakly" we understand that for some training points the labels are known, for some unknown, and for others uncertain due to the presence of random noise or other reasons such as lack of resources. The solution process requires to optimize a certain objective function (the loss function), which combines manifold regularization and low-rank matrix decomposition techniques. These low-rank approximations allow us to speed up all matrix calculations and reduce storage requirements. This is especially crucial for large datasets. Ensemble clustering is used for obtaining the co-association matrix, which we consider as the similarity matrix. The utilization of these techniques allows us to increase the quality and stability of the solution. In the numerical section, we applied the suggested method to artificial and real datasets using Monte-Carlo modeling.
Heterogeneous Transfer Learning in Ensemble Clustering
Jan 20, 2020

This work proposes an ensemble clustering method using transfer learning approach. We consider a clustering problem, in which in addition to data under consideration, "similar" labeled data are available. The datasets can be described with different features. The method is based on constructing meta-features which describe structural characteristics of data, and their transfer from source to target domain. An experimental study of the method using Monte Carlo modeling has confirmed its efficiency. In comparison with other similar methods, the proposed one is able to work under arbitrary feature descriptions of source and target domains; it has smaller complexity.
Semi-Supervised Regression using Cluster Ensemble and Low-Rank Co-Association Matrix Decomposition under Uncertainties
Jan 13, 2019



In this paper, we solve a semi-supervised regression problem. Due to the lack of knowledge about the data structure and the presence of random noise, the considered data model is uncertain. We propose a method which combines graph Laplacian regularization and cluster ensemble methodologies. The co-association matrix of the ensemble is calculated on both labeled and unlabeled data; this matrix is used as a similarity matrix in the regularization framework to derive the predicted outputs. We use the low-rank decomposition of the co-association matrix to significantly speedup calculations and reduce memory. Numerical experiments using the Monte Carlo approach demonstrate robustness, efficiency, and scalability of the proposed method.