 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving weakly supervised regression problem using low-rank manifold regularization
Apr 13, 2021


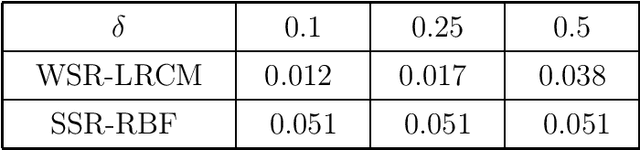
We solve a weakly supervised regression problem. Under "weakly" we understand that for some training points the labels are known, for some unknown, and for others uncertain due to the presence of random noise or other reasons such as lack of resources. The solution process requires to optimize a certain objective function (the loss function), which combines manifold regularization and low-rank matrix decomposition techniques. These low-rank approximations allow us to speed up all matrix calculations and reduce storage requirements. This is especially crucial for large datasets. Ensemble clustering is used for obtaining the co-association matrix, which we consider as the similarity matrix. The utilization of these techniques allows us to increase the quality and stability of the solution. In the numerical section, we applied the suggested method to artificial and real datasets using Monte-Carlo modeling.
Semi-Supervised Regression using Cluster Ensemble and Low-Rank Co-Association Matrix Decomposition under Uncertainties
Jan 13, 2019



In this paper, we solve a semi-supervised regression problem. Due to the lack of knowledge about the data structure and the presence of random noise, the considered data model is uncertain. We propose a method which combines graph Laplacian regularization and cluster ensemble methodologies. The co-association matrix of the ensemble is calculated on both labeled and unlabeled data; this matrix is used as a similarity matrix in the regularization framework to derive the predicted outputs. We use the low-rank decomposition of the co-association matrix to significantly speedup calculations and reduce memory. Numerical experiments using the Monte Carlo approach demonstrate robustness, efficiency, and scalability of the proposed method.