 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Relationship Detection with Internal and External Linguistic Knowledge Distillation
Aug 03, 2017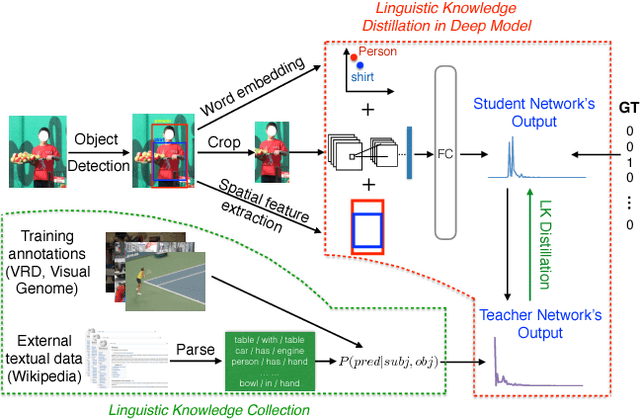
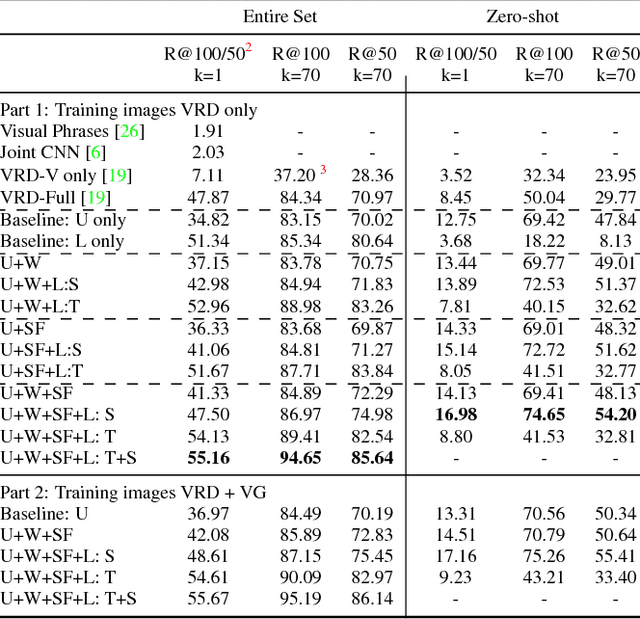

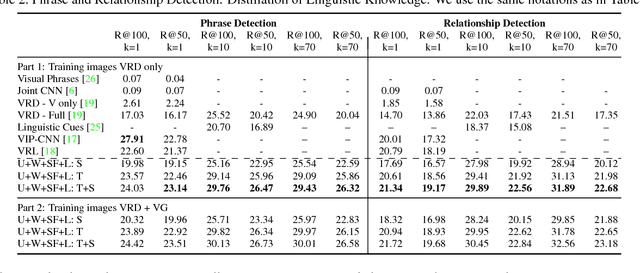
Understanding visual relationships involves identifying the subject, the object, and a predicate relating them. We leverage the strong correlations between the predicate and the (subj,obj) pair (both semantically and spatially) to predict the predicates conditioned on the subjects and the objects. Modeling the three entities jointly more accurately reflects their relationships, but complicates learning since the semantic space of visual relationships is huge and the training data is limited, especially for the long-tail relationships that have few instances. To overcome this, we use knowledge of linguistic statistics to regularize visual model learning. We obtain linguistic knowledge by mining from both training annotations (internal knowledge) and publicly available text, e.g., Wikipedia (external knowledge), computing the conditional probability distribution of a predicate given a (subj,obj) pair. Then, we distill the knowledge into a deep model to achieve better generalization. Our experimental results on the Visual Relationship Detection (VRD) and Visual Genome datasets suggest that with this linguistic knowledge distillation, our model outperforms the state-of-the-art methods significantly, especially when predicting unseen relationships (e.g., recall improved from 8.45% to 19.17% on VRD zero-shot testing set).
Generating Holistic 3D Scene Abstractions for Text-based Image Retrieval
Apr 11, 2017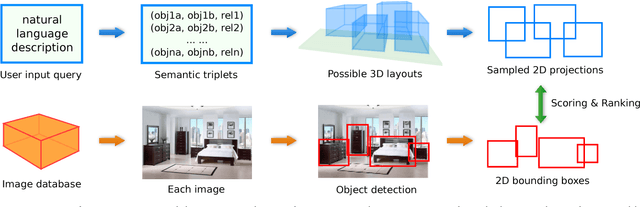

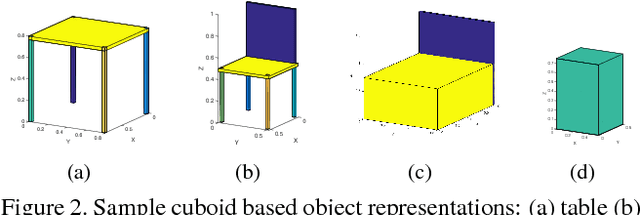
Spatial relationships between objects provide important information for text-based image retrieval. As users are more likely to describe a scene from a real world perspective, using 3D spatial relationships rather than 2D relationships that assume a particular viewing direction, one of the main challenges is to infer the 3D structure that bridges images with users' text descriptions. However, direct inference of 3D structure from images requires learning from large scale annotated data. Since interactions between objects can be reduced to a limited set of atomic spatial relations in 3D, we study the possibility of inferring 3D structure from a text description rather than an image, applying physical relation models to synthesize holistic 3D abstract object layouts satisfying the spatial constraints present in a textual description. We present a generic framework for retrieving images from a textual description of a scene by matching images with these generated abstract object layouts. Images are ranked by matching object detection outputs (bounding boxes) to 2D layout candidates (also represented by bounding boxes) which are obtained by projecting the 3D scenes with sampled camera directions. We validate our approach using public indoor scene datasets and show that our method outperforms baselines built upon object occurrence histograms and learned 2D pairwise relations.
VRFP: On-the-fly Video Retrieval using Web Images and Fast Fisher Vector Products
Apr 10, 2017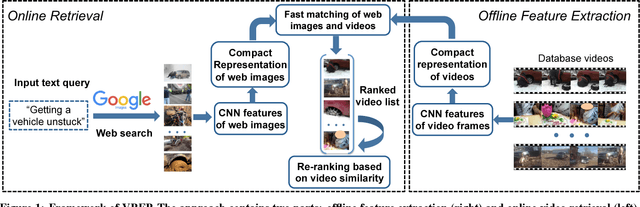
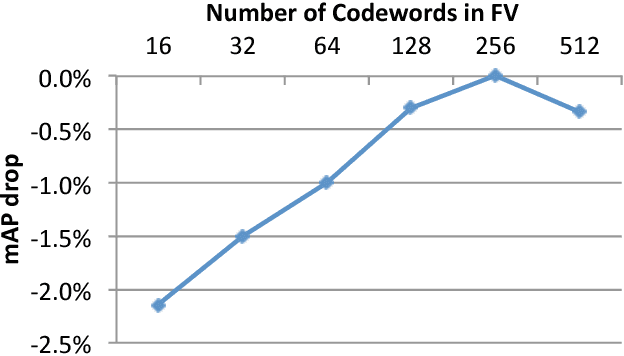
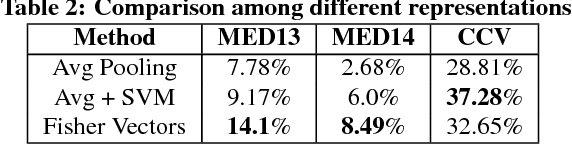
VRFP is a real-time video retrieval framework based on short text input queries, which obtains weakly labeled training images from the web after the query is known. The retrieved web images representing the query and each database video are treated as unordered collections of images, and each collection is represented using a single Fisher Vector built on CNN features. Our experiments show that a Fisher Vector is robust to noise present in web images and compares favorably in terms of accuracy to other standard representations. While a Fisher Vector can be constructed efficiently for a new query, matching against the test set is slow due to its high dimensionality. To perform matching in real-time, we present a lossless algorithm that accelerates the inner product computation between high dimensional Fisher Vectors. We prove that the expected number of multiplications required decreases quadratically with the sparsity of Fisher Vectors. We are not only able to construct and apply query models in real-time, but with the help of a simple re-ranking scheme, we also outperform state-of-the-art automatic retrieval methods by a significant margin on TRECVID MED13 (3.5%), MED14 (1.3%) and CCV datasets (5.2%). We also provide a direct comparison on standard datasets between two different paradigms for automatic video retrieval - zero-shot learning and on-the-fly retrieval.
Generalized Deep Image to Image Regression
Dec 10, 2016
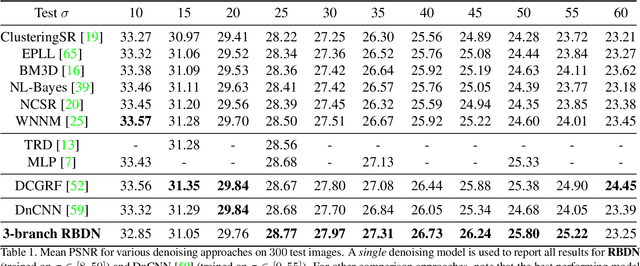
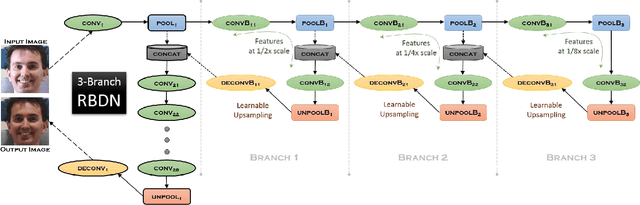

We present a Deep Convolutional Neural Network architecture which serves as a generic image-to-image regressor that can be trained end-to-end without any further machinery. Our proposed architecture: the Recursively Branched Deconvolutional Network (RBDN) develops a cheap multi-context image representation very early on using an efficient recursive branching scheme with extensive parameter sharing and learnable upsampling. This multi-context representation is subjected to a highly non-linear locality preserving transformation by the remainder of our network comprising of a series of convolutions/deconvolutions without any spatial downsampling. The RBDN architecture is fully convolutional and can handle variable sized images during inference. We provide qualitative/quantitative results on $3$ diverse tasks: relighting, denoising and colorization and show that our proposed RBDN architecture obtains comparable results to the state-of-the-art on each of these tasks when used off-the-shelf without any post processing or task-specific architectural modifications.
The Role of Context Selection in Object Detection
Sep 09, 2016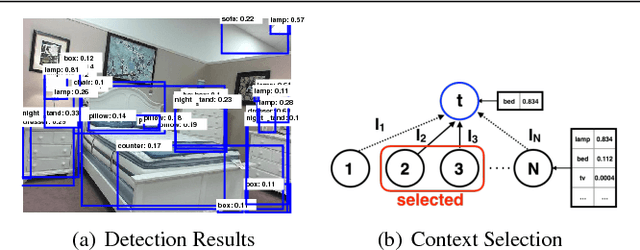
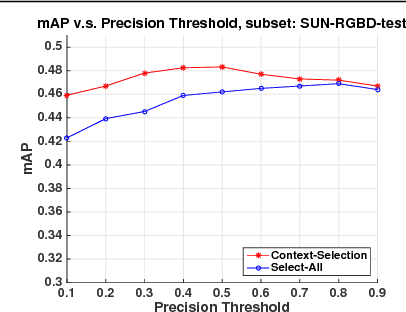


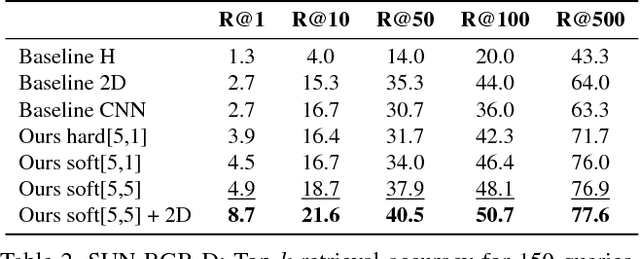
We investigate the reasons why context in object detection has limited utility by isolating and evaluating the predictive power of different context cues under ideal conditions in which context provided by an oracle. Based on this study, we propose a region-based context re-scoring method with dynamic context selection to remove noise and emphasize informative context. We introduce latent indicator variables to select (or ignore) potential contextual regions, and learn the selection strategy with latent-SVM. We conduct experiments to evaluate the performance of the proposed context selection method on the SUN RGB-D dataset. The method achieves a significant improvement in terms of mean average precision (mAP), compared with both appearance based detectors and a conventional context model without the selection scheme.
Modeling Context Between Objects for Referring Expression Understanding
Aug 01, 2016
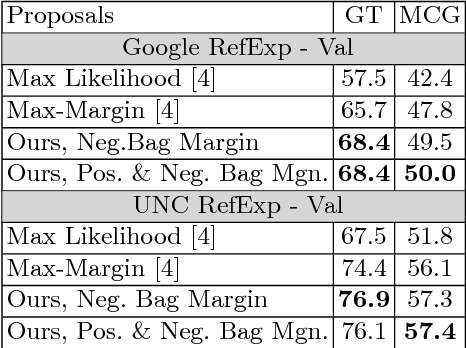
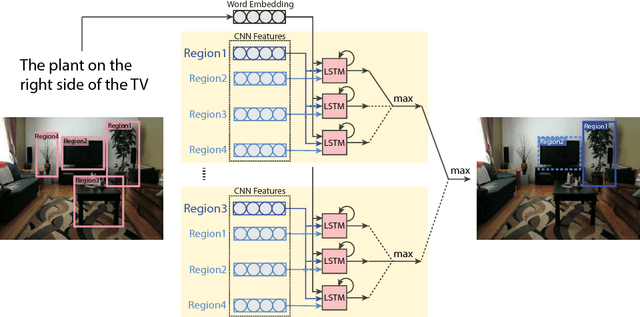
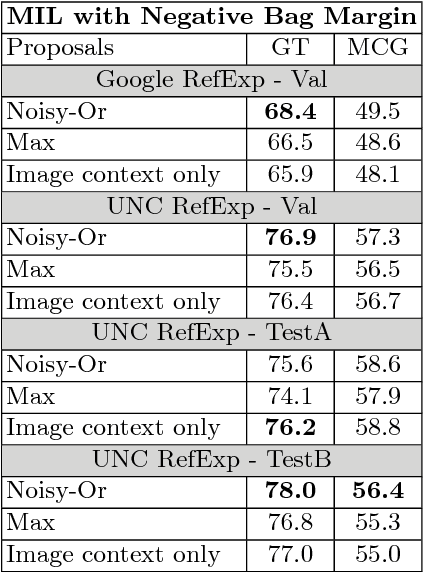
Referring expressions usually describe an object using properties of the object and relationships of the object with other objects. We propose a technique that integrates context between objects to understand referring expressions. Our approach uses an LSTM to learn the probability of a referring expression, with input features from a region and a context region. The context regions are discovered using multiple-instance learning (MIL) since annotations for context objects are generally not available for training. We utilize max-margin based MIL objective functions for training the LSTM. Experiments on the Google RefExp and UNC RefExp datasets show that modeling context between objects provides better performance than modeling only object properties. We also qualitatively show that our technique can ground a referring expression to its referred region along with the supporting context region.
Mining Discriminative Triplets of Patches for Fine-Grained Classification
May 04, 2016
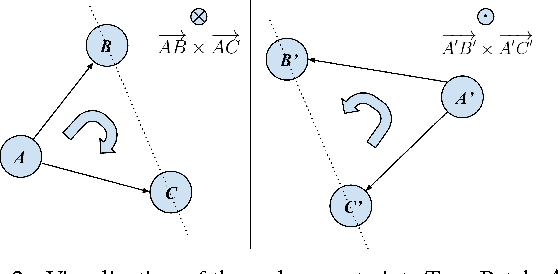
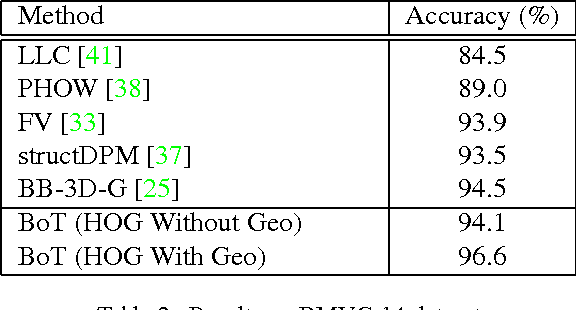
Fine-grained classification involves distinguishing between similar sub-categories based on subtle differences in highly localized regions; therefore, accurate localization of discriminative regions remains a major challenge. We describe a patch-based framework to address this problem. We introduce triplets of patches with geometric constraints to improve the accuracy of patch localization, and automatically mine discriminative geometrically-constrained triplets for classification. The resulting approach only requires object bounding boxes. Its effectiveness is demonstrated using four publicly available fine-grained datasets, on which it outperforms or achieves comparable performance to the state-of-the-art in classification.
Searching for Objects using Structure in Indoor Scenes
Nov 24, 2015
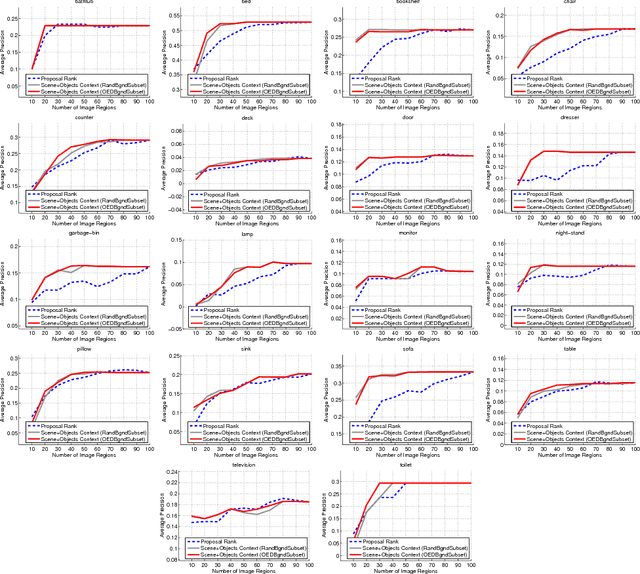
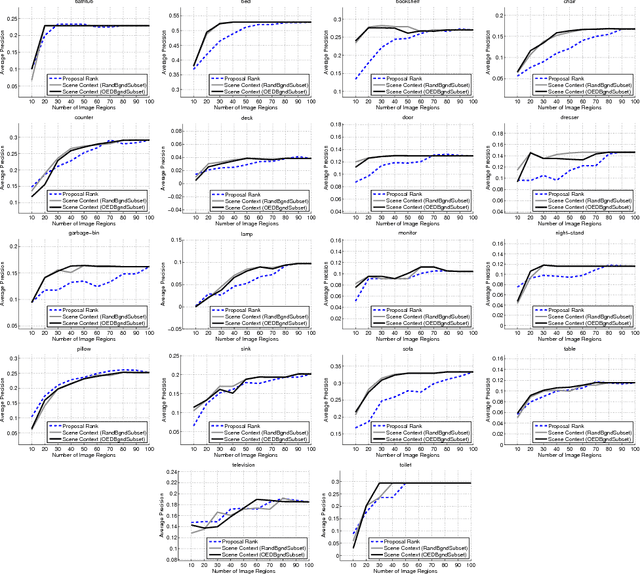

To identify the location of objects of a particular class, a passive computer vision system generally processes all the regions in an image to finally output few regions. However, we can use structure in the scene to search for objects without processing the entire image. We propose a search technique that sequentially processes image regions such that the regions that are more likely to correspond to the query class object are explored earlier. We frame the problem as a Markov decision process and use an imitation learning algorithm to learn a search strategy. Since structure in the scene is essential for search, we work with indoor scene images as they contain both unary scene context information and object-object context in the scene. We perform experiments on the NYU-depth v2 dataset and show that the unary scene context features alone can achieve a significantly high average precision while processing only 20-25\% of the regions for classes like bed and sofa. By considering object-object context along with the scene context features, the performance is further improved for classes like counter, lamp, pillow and sofa.
Selecting Relevant Web Trained Concepts for Automated Event Retrieval
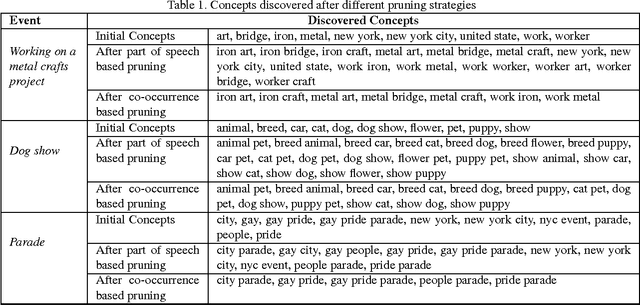
Sep 25, 2015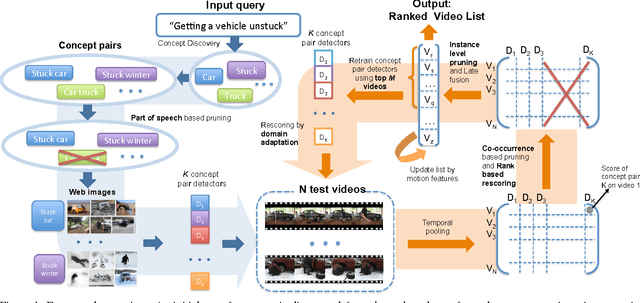


Complex event retrieval is a challenging research problem, especially when no training videos are available. An alternative to collecting training videos is to train a large semantic concept bank a priori. Given a text description of an event, event retrieval is performed by selecting concepts linguistically related to the event description and fusing the concept responses on unseen videos. However, defining an exhaustive concept lexicon and pre-training it requires vast computational resources. Therefore, recent approaches automate concept discovery and training by leveraging large amounts of weakly annotated web data. Compact visually salient concepts are automatically obtained by the use of concept pairs or, more generally, n-grams. However, not all visually salient n-grams are necessarily useful for an event query--some combinations of concepts may be visually compact but irrelevant--and this drastically affects performance. We propose an event retrieval algorithm that constructs pairs of automatically discovered concepts and then prunes those concepts that are unlikely to be helpful for retrieval. Pruning depends both on the query and on the specific video instance being evaluated. Our approach also addresses calibration and domain adaptation issues that arise when applying concept detectors to unseen videos. We demonstrate large improvements over other vision based systems on the TRECVID MED 13 dataset.