 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXTE: Explainable Text Entailment
Sep 25, 2020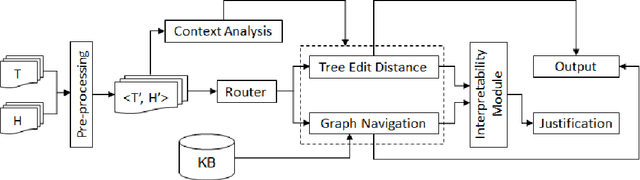

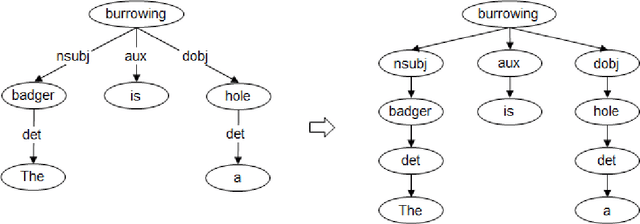

Text entailment, the task of determining whether a piece of text logically follows from another piece of text, is a key component in NLP, providing input for many semantic applications such as question answering, text summarization, information extraction, and machine translation, among others. Entailment scenarios can range from a simple syntactic variation to more complex semantic relationships between pieces of text, but most approaches try a one-size-fits-all solution that usually favors some scenario to the detriment of another. Furthermore, for entailments requiring world knowledge, most systems still work as a "black box", providing a yes/no answer that does not explain the underlying reasoning process. In this work, we introduce XTE - Explainable Text Entailment - a novel composite approach for recognizing text entailment which analyzes the entailment pair to decide whether it must be resolved syntactically or semantically. Also, if a semantic matching is involved, we make the answer interpretable, using external knowledge bases composed of structured lexical definitions to generate natural language justifications that explain the semantic relationship holding between the pieces of text. Besides outperforming well-established entailment algorithms, our composite approach gives an important step towards Explainable AI, allowing the inference model interpretation, making the semantic reasoning process explicit and understandable.
On the Semantic Interpretability of Artificial Intelligence Models
Jul 09, 2019
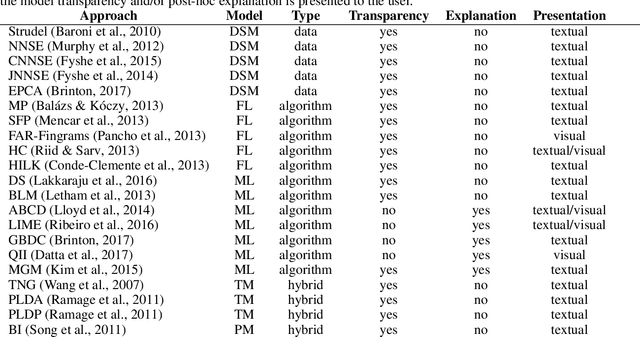
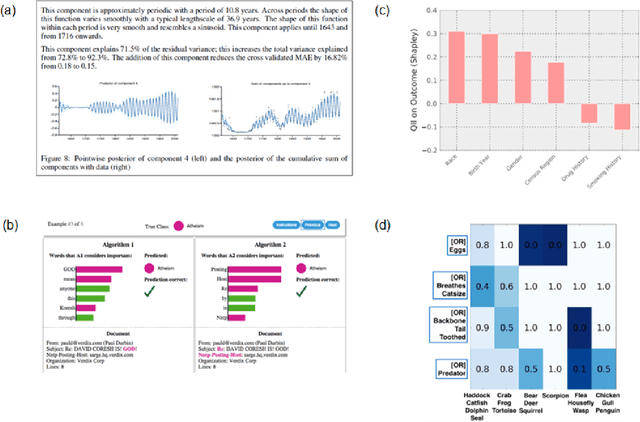
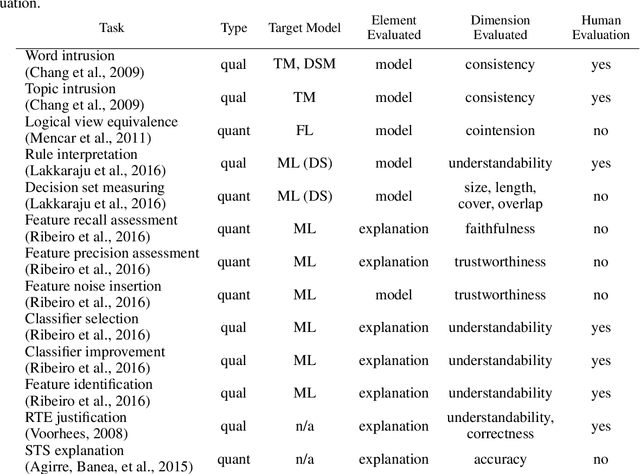
Artificial Intelligence models are becoming increasingly more powerful and accurate, supporting or even replacing humans' decision making. But with increased power and accuracy also comes higher complexity, making it hard for users to understand how the model works and what the reasons behind its predictions are. Humans must explain and justify their decisions, and so do the AI models supporting them in this process, making semantic interpretability an emerging field of study. In this work, we look at interpretability from a broader point of view, going beyond the machine learning scope and covering different AI fields such as distributional semantics and fuzzy logic, among others. We examine and classify the models according to their nature and also based on how they introduce interpretability features, analyzing how each approach affects the final users and pointing to gaps that still need to be addressed to provide more human-centered interpretability solutions.
Building a Knowledge Graph from Natural Language Definitions for Interpretable Text Entailment Recognition
Jun 20, 2018
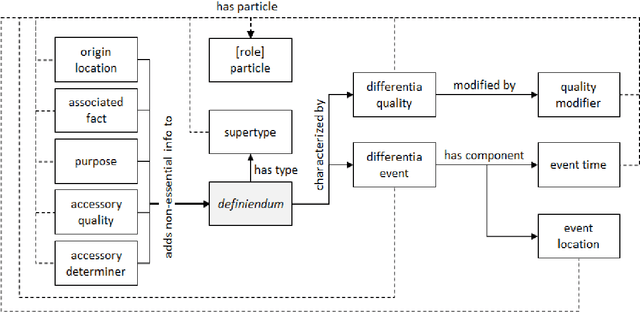


Natural language definitions of terms can serve as a rich source of knowledge, but structuring them into a comprehensible semantic model is essential to enable them to be used in semantic interpretation tasks. We propose a method and provide a set of tools for automatically building a graph world knowledge base from natural language definitions. Adopting a conceptual model composed of a set of semantic roles for dictionary definitions, we trained a classifier for automatically labeling definitions, preparing the data to be later converted to a graph representation. WordNetGraph, a knowledge graph built out of noun and verb WordNet definitions according to this methodology, was successfully used in an interpretable text entailment recognition approach which uses paths in this graph to provide clear justifications for entailment decisions.
* 5 pages, 5 figures, presented at LREC 2018
Semantic Relation Classification: Task Formalisation and Refinement
Jun 20, 2018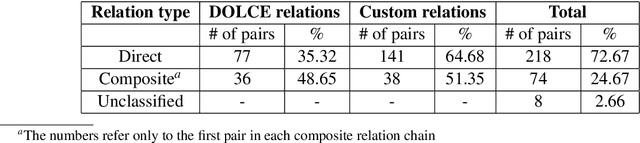

The identification of semantic relations between terms within texts is a fundamental task in Natural Language Processing which can support applications requiring a lightweight semantic interpretation model. Currently, semantic relation classification concentrates on relations which are evaluated over open-domain data. This work provides a critique on the set of abstract relations used for semantic relation classification with regard to their ability to express relationships between terms which are found in a domain-specific corpora. Based on this analysis, this work proposes an alternative semantic relation model based on reusing and extending the set of abstract relations present in the DOLCE ontology. The resulting set of relations is well grounded, allows to capture a wide range of relations and could thus be used as a foundation for automatic classification of semantic relations.
* 10 pages, presented at CogALex-V 2016
Categorization of Semantic Roles for Dictionary Definitions
Jun 20, 2018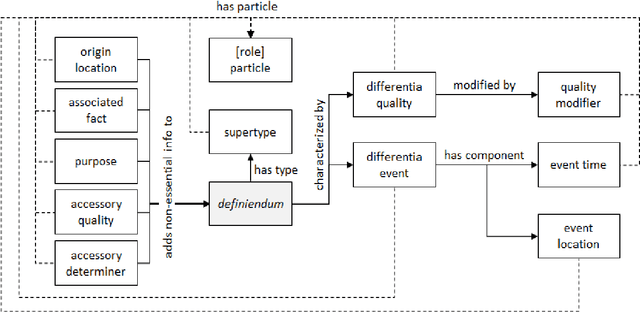
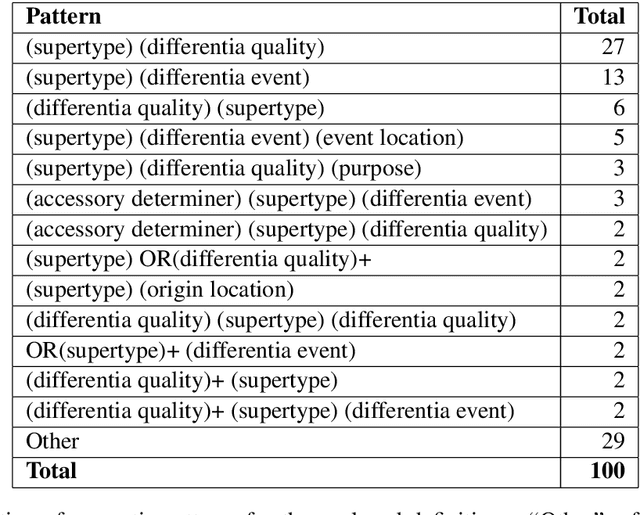


Understanding the semantic relationships between terms is a fundamental task in natural language processing applications. While structured resources that can express those relationships in a formal way, such as ontologies, are still scarce, a large number of linguistic resources gathering dictionary definitions is becoming available, but understanding the semantic structure of natural language definitions is fundamental to make them useful in semantic interpretation tasks. Based on an analysis of a subset of WordNet's glosses, we propose a set of semantic roles that compose the semantic structure of a dictionary definition, and show how they are related to the definition's syntactic configuration, identifying patterns that can be used in the development of information extraction frameworks and semantic models.
* 9 pages, 2 figures, presented at CogALex-V 2016
Word Tagging with Foundational Ontology Classes: Extending the WordNet-DOLCE Mapping to Verbs
Jun 20, 2018
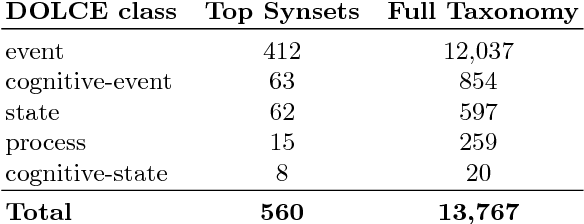
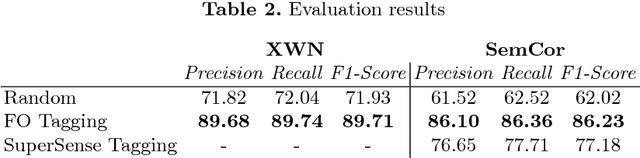
Semantic annotation is fundamental to deal with large-scale lexical information, mapping the information to an enumerable set of categories over which rules and algorithms can be applied, and foundational ontology classes can be used as a formal set of categories for such tasks. A previous alignment between WordNet noun synsets and DOLCE provided a starting point for ontology-based annotation, but in NLP tasks verbs are also of substantial importance. This work presents an extension to the WordNet-DOLCE noun mapping, aligning verbs according to their links to nouns denoting perdurants, transferring to the verb the DOLCE class assigned to the noun that best represents that verb's occurrence. To evaluate the usefulness of this resource, we implemented a foundational ontology-based semantic annotation framework, that assigns a high-level foundational category to each word or phrase in a text, and compared it to a similar annotation tool, obtaining an increase of 9.05% in accuracy.
* 13 pages, 1 figure, presented at EKAW 2016