 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Feature Relevance Through Step Size Adaptation in Temporal-Difference Learning
Mar 08, 2019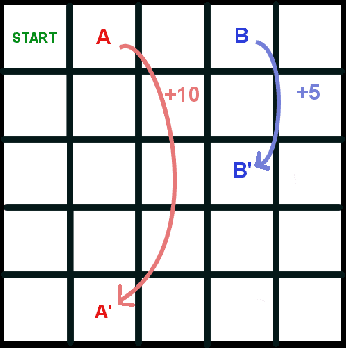
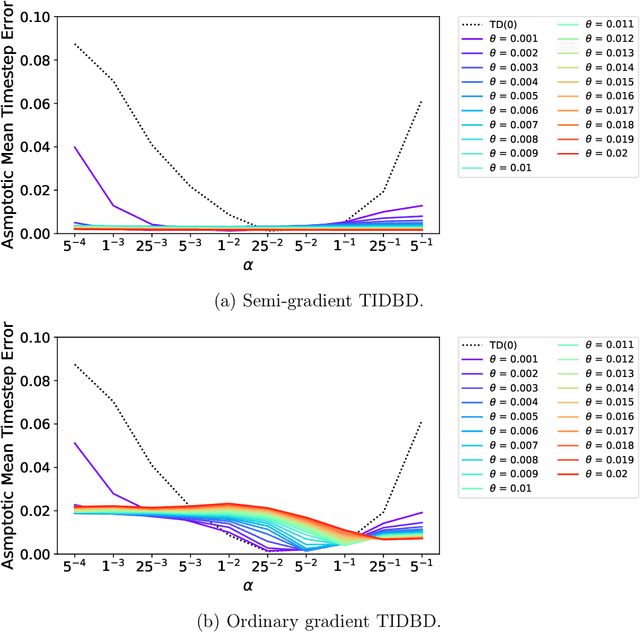
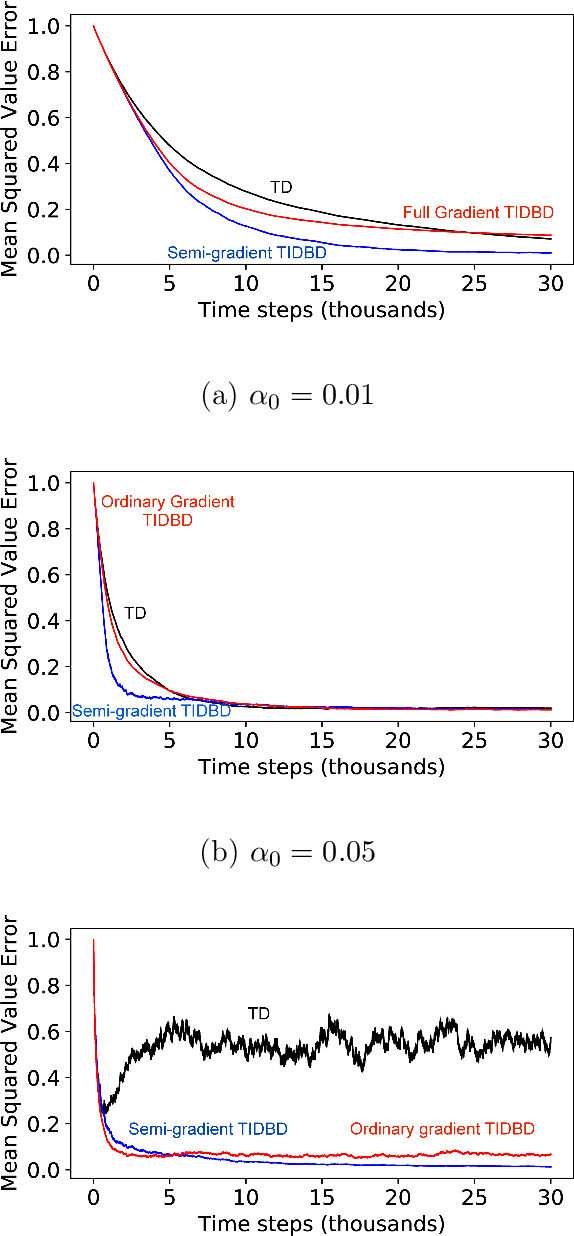
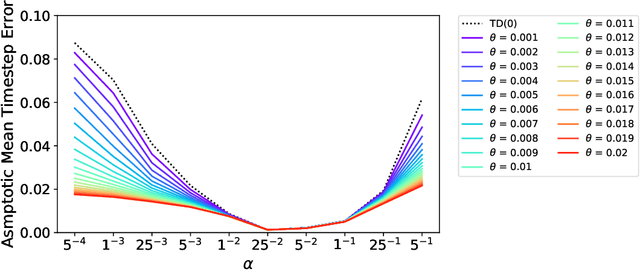
There is a long history of using meta learning as representation learning, specifically for determining the relevance of inputs. In this paper, we examine an instance of meta-learning in which feature relevance is learned by adapting step size parameters of stochastic gradient descent---building on a variety of prior work in stochastic approximation, machine learning, and artificial neural networks. In particular, we focus on stochastic meta-descent introduced in the Incremental Delta-Bar-Delta (IDBD) algorithm for setting individual step sizes for each feature of a linear function approximator. Using IDBD, a feature with large or small step sizes will have a large or small impact on generalization from training examples. As a main contribution of this work, we extend IDBD to temporal-difference (TD) learning---a form of learning which is effective in sequential, non i.i.d. problems. We derive a variety of IDBD generalizations for TD learning, demonstrating that they are able to distinguish which features are relevant and which are not. We demonstrate that TD IDBD is effective at learning feature relevance in both an idealized gridworld and a real-world robotic prediction task.
Many-Goals Reinforcement Learning
Jun 22, 2018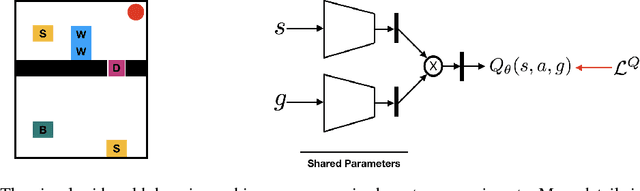
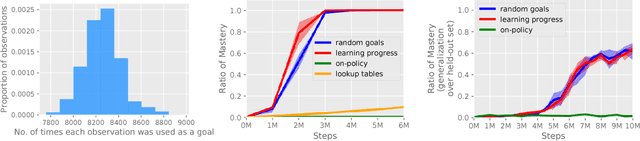
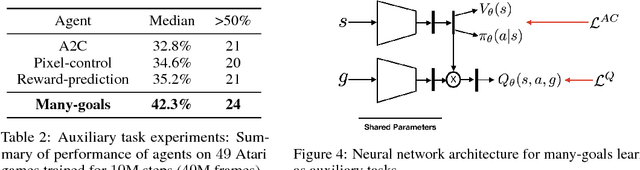
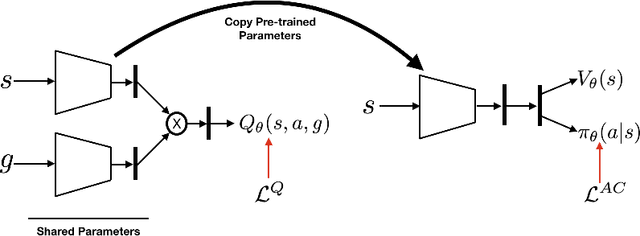
All-goals updating exploits the off-policy nature of Q-learning to update all possible goals an agent could have from each transition in the world, and was introduced into Reinforcement Learning (RL) by Kaelbling (1993). In prior work this was mostly explored in small-state RL problems that allowed tabular representations and where all possible goals could be explicitly enumerated and learned separately. In this paper we empirically explore 3 different extensions of the idea of updating many (instead of all) goals in the context of RL with deep neural networks (or DeepRL for short). First, in a direct adaptation of Kaelbling's approach we explore if many-goals updating can be used to achieve mastery in non-tabular visual-observation domains. Second, we explore whether many-goals updating can be used to pre-train a network to subsequently learn faster and better on a single main task of interest. Third, we explore whether many-goals updating can be used to provide auxiliary task updates in training a network to learn faster and better on a single main task of interest. We provide comparisons to baselines for each of the 3 extensions.
TIDBD: Adapting Temporal-difference Step-sizes Through Stochastic Meta-descent
Apr 10, 2018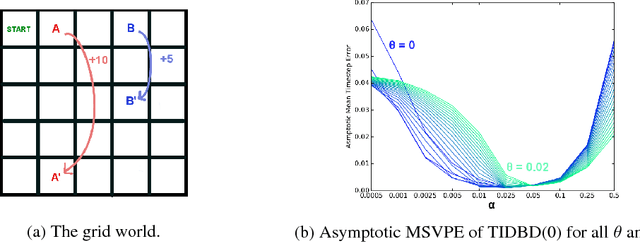
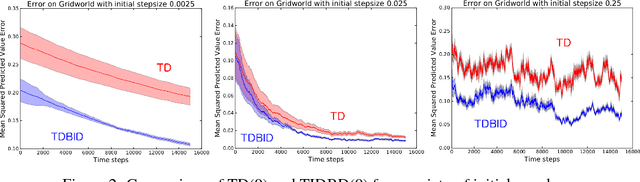
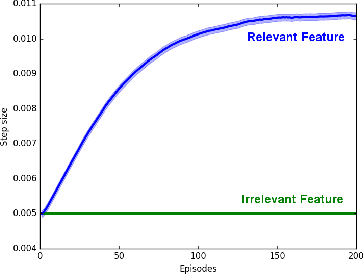
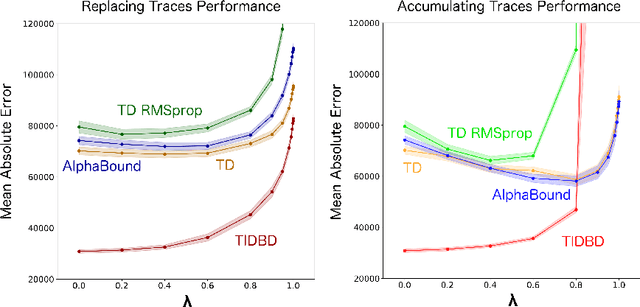
In this paper, we introduce a method for adapting the step-sizes of temporal difference (TD) learning. The performance of TD methods often depends on well chosen step-sizes, yet few algorithms have been developed for setting the step-size automatically for TD learning. An important limitation of current methods is that they adapt a single step-size shared by all the weights of the learning system. A vector step-size enables greater optimization by specifying parameters on a per-feature basis. Furthermore, adapting parameters at different rates has the added benefit of being a simple form of representation learning. We generalize Incremental Delta Bar Delta (IDBD)---a vectorized adaptive step-size method for supervised learning---to TD learning, which we name TIDBD. We demonstrate that TIDBD is able to find appropriate step-sizes in both stationary and non-stationary prediction tasks, outperforming ordinary TD methods and TD methods with scalar step-size adaptation; we demonstrate that it can differentiate between features which are relevant and irrelevant for a given task, performing representation learning; and we show on a real-world robot prediction task that TIDBD is able to outperform ordinary TD methods and TD methods augmented with AlphaBound and RMSprop.
Learning Representations by Stochastic Meta-Gradient Descent in Neural Networks
Apr 27, 2017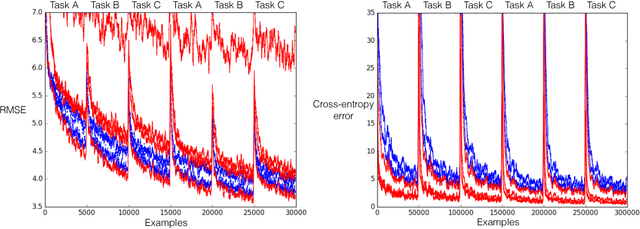
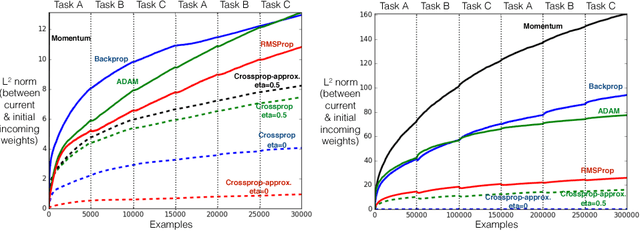
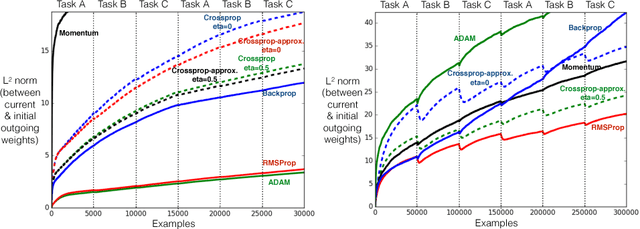
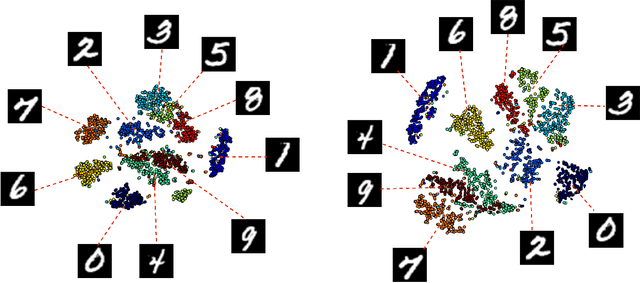
Representations are fundamental to artificial intelligence. The performance of a learning system depends on the type of representation used for representing the data. Typically, these representations are hand-engineered using domain knowledge. More recently, the trend is to learn these representations through stochastic gradient descent in multi-layer neural networks, which is called backprop. Learning the representations directly from the incoming data stream reduces the human labour involved in designing a learning system. More importantly, this allows in scaling of a learning system for difficult tasks. In this paper, we introduce a new incremental learning algorithm called crossprop, which learns incoming weights of hidden units based on the meta-gradient descent approach, that was previously introduced by Sutton (1992) and Schraudolph (1999) for learning step-sizes. The final update equation introduces an additional memory parameter for each of these weights and generalizes the backprop update equation. From our experiments, we show that crossprop learns and reuses its feature representation while tackling new and unseen tasks whereas backprop relearns a new feature representation.
Face valuing: Training user interfaces with facial expressions and reinforcement learning
Jun 09, 2016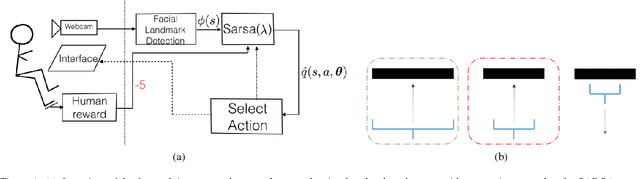



An important application of interactive machine learning is extending or amplifying the cognitive and physical capabilities of a human. To accomplish this, machines need to learn about their human users' intentions and adapt to their preferences. In most current research, a user has conveyed preferences to a machine using explicit corrective or instructive feedback; explicit feedback imposes a cognitive load on the user and is expensive in terms of human effort. The primary objective of the current work is to demonstrate that a learning agent can reduce the amount of explicit feedback required for adapting to the user's preferences pertaining to a task by learning to perceive a value of its behavior from the human user, particularly from the user's facial expressions---we call this face valuing. We empirically evaluate face valuing on a grip selection task. Our preliminary results suggest that an agent can quickly adapt to a user's changing preferences with minimal explicit feedback by learning a value function that maps facial features extracted from a camera image to expected future reward. We believe that an agent learning to perceive a value from the body language of its human user is complementary to existing interactive machine learning approaches and will help in creating successful human-machine interactive applications.
Differential Recurrent Neural Networks for Action Recognition
Apr 25, 2015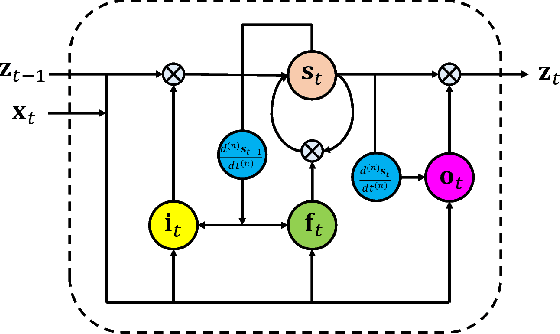
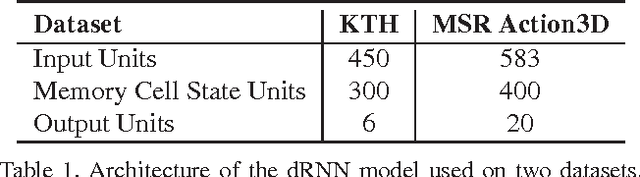

The long short-term memory (LSTM) neural network is capable of processing complex sequential information since it utilizes special gating schemes for learning representations from long input sequences. It has the potential to model any sequential time-series data, where the current hidden state has to be considered in the context of the past hidden states. This property makes LSTM an ideal choice to learn the complex dynamics of various actions. Unfortunately, the conventional LSTMs do not consider the impact of spatio-temporal dynamics corresponding to the given salient motion patterns, when they gate the information that ought to be memorized through time. To address this problem, we propose a differential gating scheme for the LSTM neural network, which emphasizes on the change in information gain caused by the salient motions between the successive frames. This change in information gain is quantified by Derivative of States (DoS), and thus the proposed LSTM model is termed as differential Recurrent Neural Network (dRNN). We demonstrate the effectiveness of the proposed model by automatically recognizing actions from the real-world 2D and 3D human action datasets. Our study is one of the first works towards demonstrating the potential of learning complex time-series representations via high-order derivatives of states.