 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorpus for Automatic Structuring of Legal Documents
Jan 31, 2022
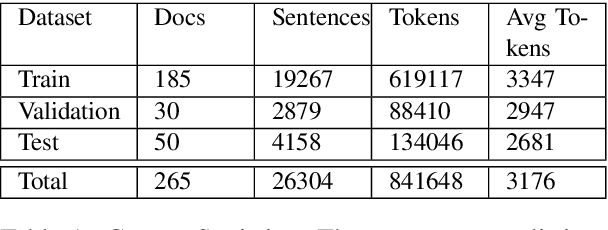
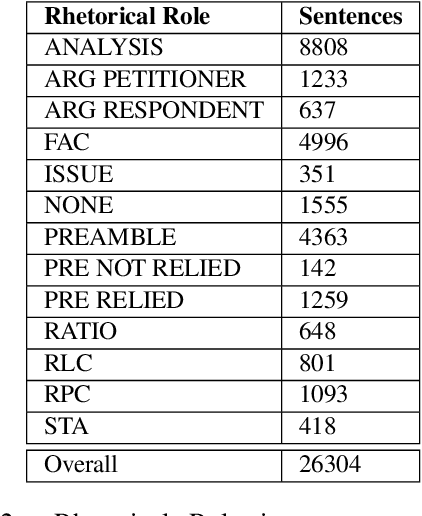
In populous countries, pending legal cases have been growing exponentially. There is a need for developing techniques for processing and organizing legal documents. In this paper, we introduce a new corpus for structuring legal documents. In particular, we introduce a corpus of legal judgment documents in English that are segmented into topical and coherent parts. Each of these parts is annotated with a label coming from a list of pre-defined Rhetorical Roles. We develop baseline models for automatically predicting rhetorical roles in a legal document based on the annotated corpus. Further, we show the application of rhetorical roles to improve performance on the tasks of summarization and legal judgment prediction. We release the corpus and baseline model code along with the paper.
CLSRIL-23: Cross Lingual Speech Representations for Indic Languages
Jul 15, 2021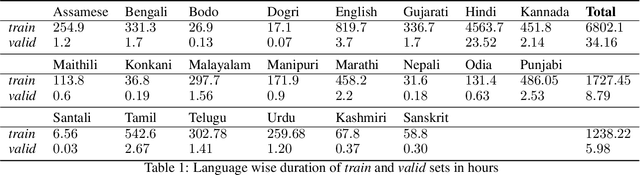
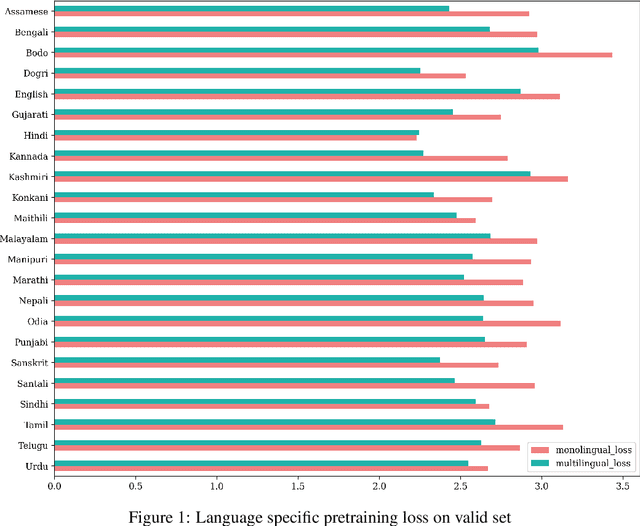
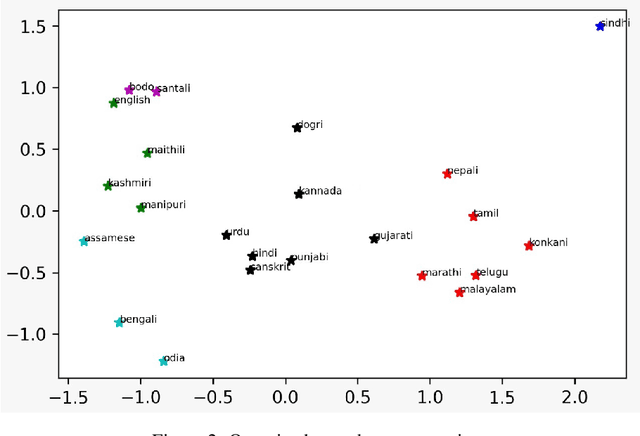

We present a CLSRIL-23, a self supervised learning based audio pre-trained model which learns cross lingual speech representations from raw audio across 23 Indic languages. It is built on top of wav2vec 2.0 which is solved by training a contrastive task over masked latent speech representations and jointly learns the quantization of latents shared across all languages. We compare the language wise loss during pretraining to compare effects of monolingual and multilingual pretraining. Performance on some downstream fine-tuning tasks for speech recognition is also compared and our experiments show that multilingual pretraining outperforms monolingual training, in terms of learning speech representations which encodes phonetic similarity of languages and also in terms of performance on down stream tasks. A decrease of 5% is observed in WER and 9.5% in CER when a multilingual pretrained model is used for finetuning in Hindi. All the code models are also open sourced. CLSRIL-23 is a model trained on $23$ languages and almost 10,000 hours of audio data to facilitate research in speech recognition for Indic languages. We hope that new state of the art systems will be created using the self supervised approach, especially for low resources Indic languages.
Samanantar: The Largest Publicly Available Parallel Corpora Collection for 11 Indic Languages
Apr 29, 2021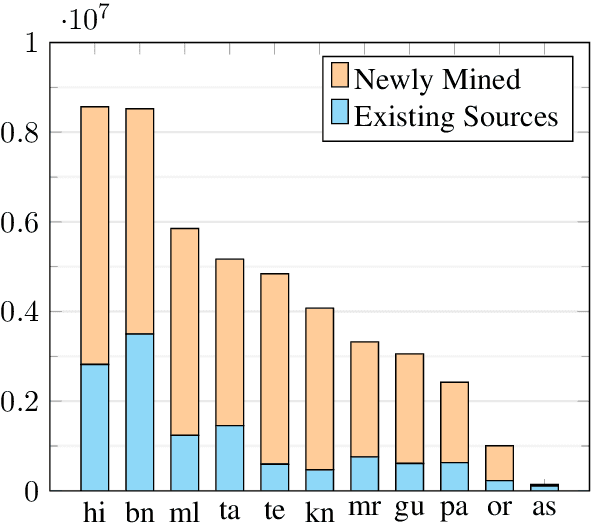
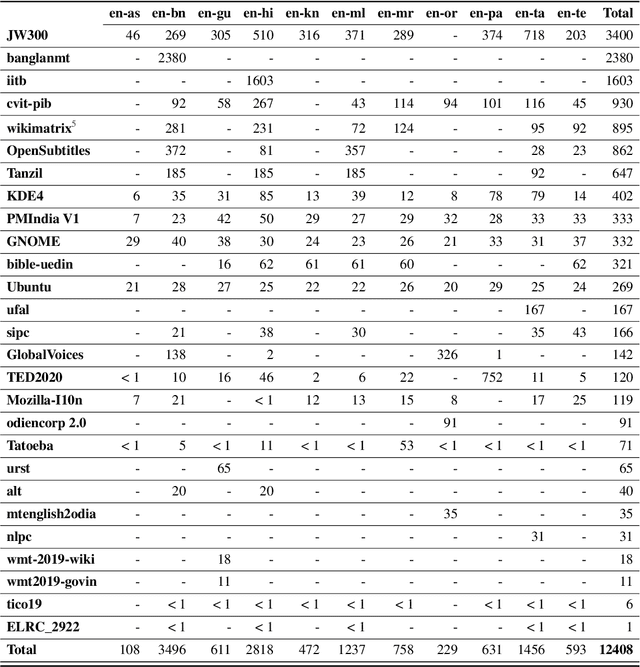
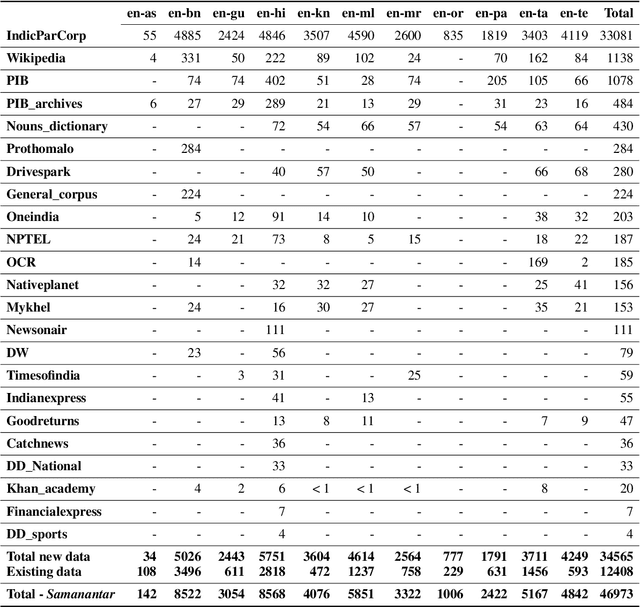
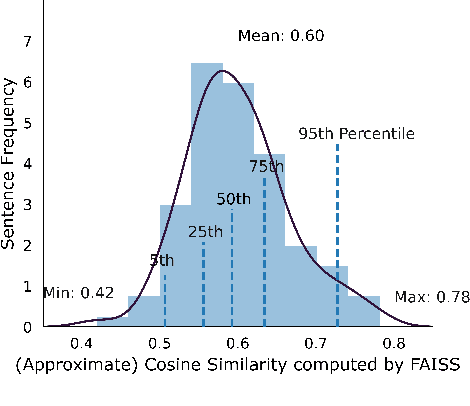
We present Samanantar, the largest publicly available parallel corpora collection for Indic languages. The collection contains a total of 46.9 million sentence pairs between English and 11 Indic languages (from two language families). In particular, we compile 12.4 million sentence pairs from existing, publicly-available parallel corpora, and we additionally mine 34.6 million sentence pairs from the web, resulting in a 2.8X increase in publicly available sentence pairs. We mine the parallel sentences from the web by combining many corpora, tools, and methods. In particular, we use (a) web-crawled monolingual corpora, (b) document OCR for extracting sentences from scanned documents (c) multilingual representation models for aligning sentences, and (d) approximate nearest neighbor search for searching in a large collection of sentences. Human evaluation of samples from the newly mined corpora validate the high quality of the parallel sentences across 11 language pairs. Further, we extracted 82.7 million sentence pairs between all 55 Indic language pairs from the English-centric parallel corpus using English as the pivot language. We trained multilingual NMT models spanning all these languages on Samanantar and compared with other baselines and previously reported results on publicly available benchmarks. Our models outperform existing models on these benchmarks, establishing the utility of Samanantar. Our data (https://indicnlp.ai4bharat.org/samanantar) and models (https://github.com/AI4Bharat/IndicTrans) will be available publicly and we hope they will help advance research in Indic NMT and multilingual NLP for Indic languages.
Overview of Guidance, Navigation and Control System of the TeamIndus lunar lander
Jul 25, 2019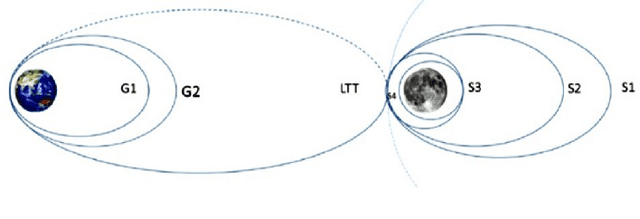


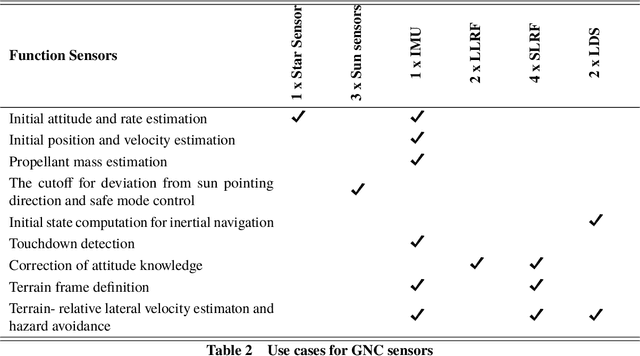
TeamIndus' lunar logistics vision includes multiple lunar missions to meet requirements of science, commercial and efforts towards global exploration. The first mission is slated for launch in 2020. The prime objective is to demonstrate autonomous precision lunar landing, and Surface Exploration Rover to collect data on the vicinity of the landing site. TeamIndus has developed various technologies towards lowering the access barrier to the lunar surface. This paper shall provide an overview of design of lander GNC system. The design of the GNC system has been described after concluding studies on sensor and actuator configurations. Frugal design approach is followed in the selection of GNC hardware. The paper describes the constraints for the orbital maneuvers and the lunar descent strategy. Various aspects of the GNC design of autonomous lunar descent maneuver: timeline of events, guidance, inertial and optical terrain-relative navigation schemes are described. The GNC software description focuses on system architecture, modes of operation, and core elements of the GNC software. The GNC algorithms have been tested using Monte-Carlo simulations and Processor-in-Loop runs. The paper concludes with a summary of key risk-mitigation studies for soft landing.