 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandshakes AI Research at CASE 2021 Task 1: Exploring different approaches for multilingual tasks
Oct 29, 2021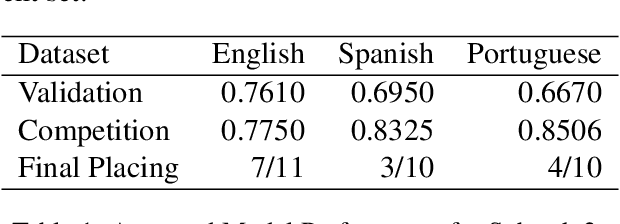
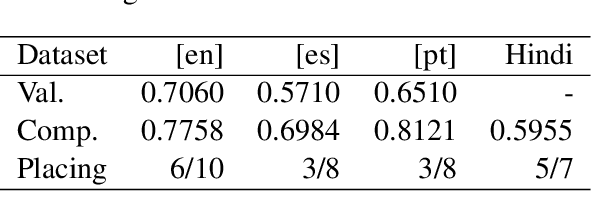
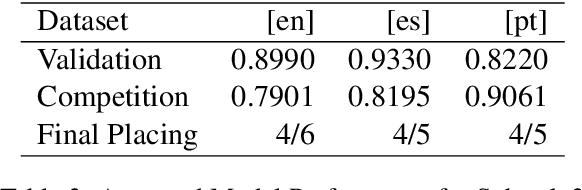

The aim of the CASE 2021 Shared Task 1 (H\"urriyeto\u{g}lu et al., 2021) was to detect and classify socio-political and crisis event information at document, sentence, cross-sentence, and token levels in a multilingual setting, with each of these subtasks being evaluated separately in each test language. Our submission contained entries in all of the subtasks, and the scores obtained validated our research finding: That the multilingual aspect of the tasks should be embraced, so that modeling and training regimes use the multilingual nature of the tasks to their mutual benefit, rather than trying to tackle the different languages separately. Our code is available at https://github.com/HandshakesByDC/case2021/
* Accepted paper for CASE 2021 workshop at ACL-IJCNLP 2021. (6 pages including references)
Red Dragon AI at TextGraphs 2021 Shared Task: Multi-Hop Inference Explanation Regeneration by Matching Expert Ratings
Jul 27, 2021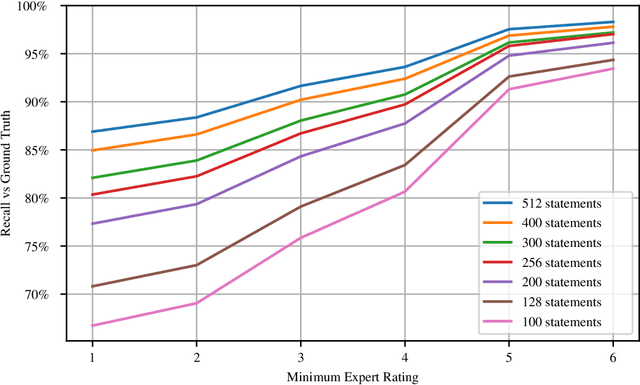



Creating explanations for answers to science questions is a challenging task that requires multi-hop inference over a large set of fact sentences. This year, to refocus the Textgraphs Shared Task on the problem of gathering relevant statements (rather than solely finding a single 'correct path'), the WorldTree dataset was augmented with expert ratings of 'relevance' of statements to each overall explanation. Our system, which achieved second place on the Shared Task leaderboard, combines initial statement retrieval; language models trained to predict the relevance scores; and ensembling of a number of the resulting rankings. Our code implementation is made available at https://github.com/mdda/worldtree_corpus/tree/textgraphs_2021