 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking LLM Summaries of Multimodal Clinical Time Series for Remote Monitoring
Mar 02, 2026Large language models (LLMs) can generate fluent clinical summaries of remote therapeutic monitoring time series. However, it remains unclear whether these narratives faithfully capture clinically significant events, such as sustained abnormalities. Existing evaluation metrics primarily focus on semantic similarity and linguistic quality, leaving event-level correctness largely unmeasured. To address this gap, we introduce an event-based evaluation framework for multimodal time-series summarization using the Technology-Integrated Health Management (TIHM)-1.5 dementia monitoring dataset. Clinically grounded daily events are derived through rule-based abnormal thresholds and temporal persistence criteria. Model-generated summaries are then aligned with these structured facts. Our evaluation protocol measures abnormality recall, duration recall, measurement coverage, and hallucinated event mentions. We benchmark three approaches: zero-shot prompting, statistical prompting, and a vision-based pipeline that uses rendered time-series visualizations. The results reveal a striking decoupling between conventional metrics and clinical event fidelity. Models that achieve high semantic similarity scores often exhibit near-zero abnormality recall. In contrast, the vision-based approach demonstrates the strongest event alignment, achieving 45.7% abnormality recall and 100% duration recall. These findings underscore the importance of event-aware evaluation to ensure reliable clinical time-series summarization.
Handshakes AI Research at CASE 2021 Task 1: Exploring different approaches for multilingual tasks
Oct 29, 2021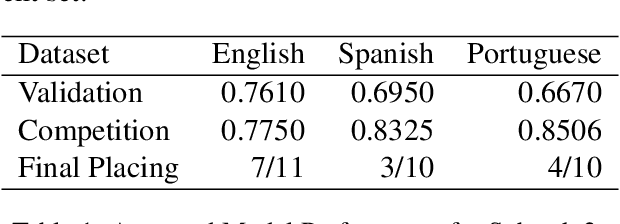
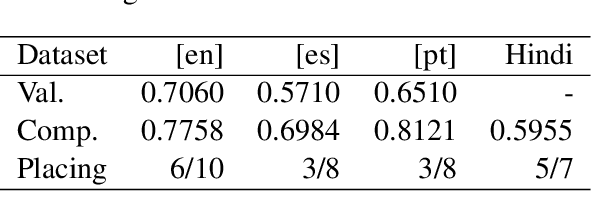
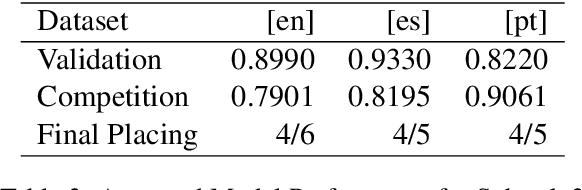

The aim of the CASE 2021 Shared Task 1 (H\"urriyeto\u{g}lu et al., 2021) was to detect and classify socio-political and crisis event information at document, sentence, cross-sentence, and token levels in a multilingual setting, with each of these subtasks being evaluated separately in each test language. Our submission contained entries in all of the subtasks, and the scores obtained validated our research finding: That the multilingual aspect of the tasks should be embraced, so that modeling and training regimes use the multilingual nature of the tasks to their mutual benefit, rather than trying to tackle the different languages separately. Our code is available at https://github.com/HandshakesByDC/case2021/
* Accepted paper for CASE 2021 workshop at ACL-IJCNLP 2021. (6 pages including references)