 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmoSpeech: Guiding FastSpeech2 Towards Emotional Text to Speech
Jun 28, 2023



State-of-the-art speech synthesis models try to get as close as possible to the human voice. Hence, modelling emotions is an essential part of Text-To-Speech (TTS) research. In our work, we selected FastSpeech2 as the starting point and proposed a series of modifications for synthesizing emotional speech. According to automatic and human evaluation, our model, EmoSpeech, surpasses existing models regarding both MOS score and emotion recognition accuracy in generated speech. We provided a detailed ablation study for every extension to FastSpeech2 architecture that forms EmoSpeech. The uneven distribution of emotions in the text is crucial for better, synthesized speech and intonation perception. Our model includes a conditioning mechanism that effectively handles this issue by allowing emotions to contribute to each phone with varying intensity levels. The human assessment indicates that proposed modifications generate audio with higher MOS and emotional expressiveness.
Connecting adversarial attacks and optimal transport for domain adaptation
Jun 04, 2022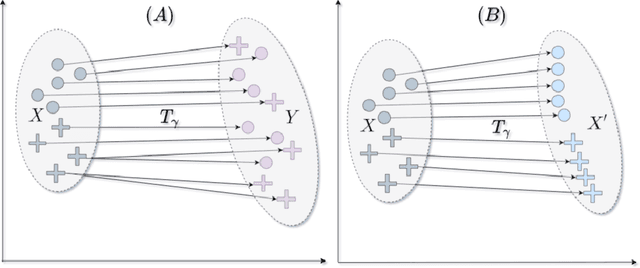
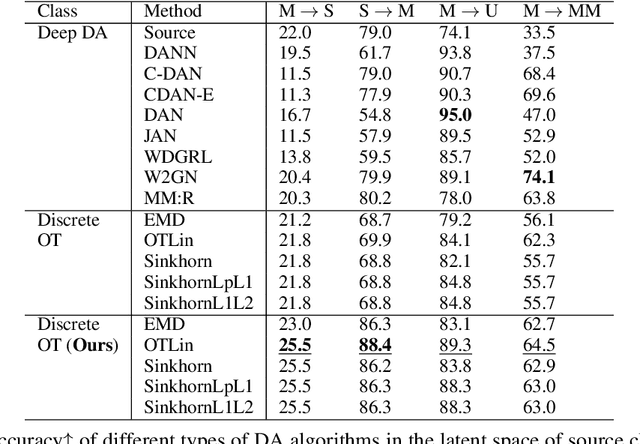
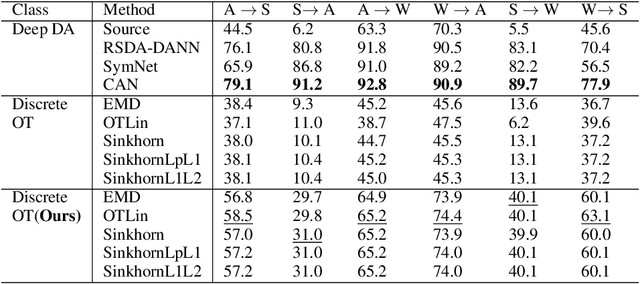
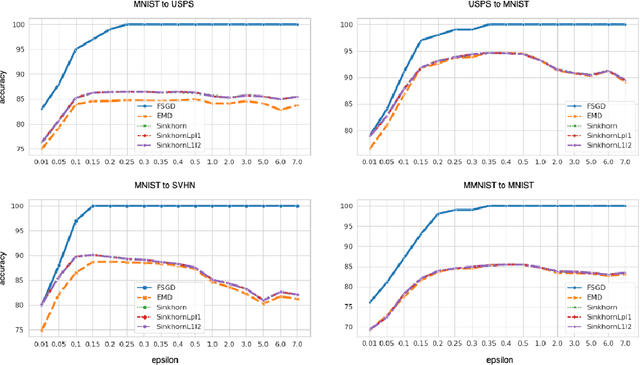
We present a novel algorithm for domain adaptation using optimal transport. In domain adaptation, the goal is to adapt a classifier trained on the source domain samples to the target domain. In our method, we use optimal transport to map target samples to the domain named source fiction. This domain differs from the source but is accurately classified by the source domain classifier. Our main idea is to generate a source fiction by c-cyclically monotone transformation over the target domain. If samples with the same labels in two domains are c-cyclically monotone, the optimal transport map between these domains preserves the class-wise structure, which is the main goal of domain adaptation. To generate a source fiction domain, we propose an algorithm that is based on our finding that adversarial attacks are a c-cyclically monotone transformation of the dataset. We conduct experiments on Digits and Modern Office-31 datasets and achieve improvement in performance for simple discrete optimal transport solvers for all adaptation tasks.