 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamguider: Improved Training free Diffusion-based Conditional Generation
Jun 04, 2024



Diffusion models have emerged as a formidable tool for training-free conditional generation.However, a key hurdle in inference-time guidance techniques is the need for compute-heavy backpropagation through the diffusion network for estimating the guidance direction. Moreover, these techniques often require handcrafted parameter tuning on a case-by-case basis. Although some recent works have introduced minimal compute methods for linear inverse problems, a generic lightweight guidance solution to both linear and non-linear guidance problems is still missing. To this end, we propose Dreamguider, a method that enables inference-time guidance without compute-heavy backpropagation through the diffusion network. The key idea is to regulate the gradient flow through a time-varying factor. Moreover, we propose an empirical guidance scale that works for a wide variety of tasks, hence removing the need for handcrafted parameter tuning. We further introduce an effective lightweight augmentation strategy that significantly boosts the performance during inference-time guidance. We present experiments using Dreamguider on multiple tasks across multiple datasets and models to show the effectiveness of the proposed modules. To facilitate further research, we will make the code public after the review process.
MaxFusion: Plug&Play Multi-Modal Generation in Text-to-Image Diffusion Models
Apr 15, 2024



Large diffusion-based Text-to-Image (T2I) models have shown impressive generative powers for text-to-image generation as well as spatially conditioned image generation. For most applications, we can train the model end-toend with paired data to obtain photorealistic generation quality. However, to add an additional task, one often needs to retrain the model from scratch using paired data across all modalities to retain good generation performance. In this paper, we tackle this issue and propose a novel strategy to scale a generative model across new tasks with minimal compute. During our experiments, we discovered that the variance maps of intermediate feature maps of diffusion models capture the intensity of conditioning. Utilizing this prior information, we propose MaxFusion, an efficient strategy to scale up text-to-image generation models to accommodate new modality conditions. Specifically, we combine aligned features of multiple models, hence bringing a compositional effect. Our fusion strategy can be integrated into off-the-shelf models to enhance their generative prowess.
Ambiguous Medical Image Segmentation using Diffusion Models
Apr 10, 2023



Collective insights from a group of experts have always proven to outperform an individual's best diagnostic for clinical tasks. For the task of medical image segmentation, existing research on AI-based alternatives focuses more on developing models that can imitate the best individual rather than harnessing the power of expert groups. In this paper, we introduce a single diffusion model-based approach that produces multiple plausible outputs by learning a distribution over group insights. Our proposed model generates a distribution of segmentation masks by leveraging the inherent stochastic sampling process of diffusion using only minimal additional learning. We demonstrate on three different medical image modalities- CT, ultrasound, and MRI that our model is capable of producing several possible variants while capturing the frequencies of their occurrences. Comprehensive results show that our proposed approach outperforms existing state-of-the-art ambiguous segmentation networks in terms of accuracy while preserving naturally occurring variation. We also propose a new metric to evaluate the diversity as well as the accuracy of segmentation predictions that aligns with the interest of clinical practice of collective insights.
AT-DDPM: Restoring Faces degraded by Atmospheric Turbulence using Denoising Diffusion Probabilistic Models
Aug 24, 2022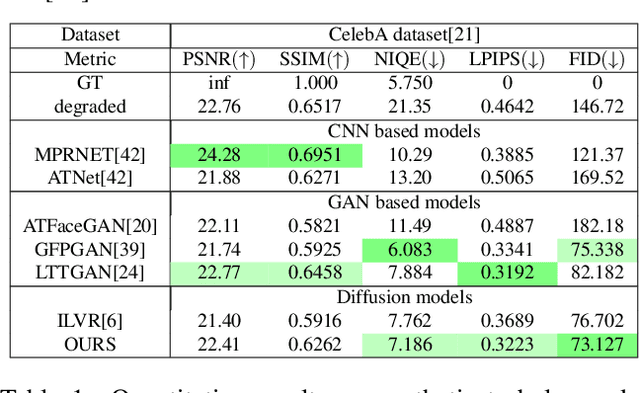
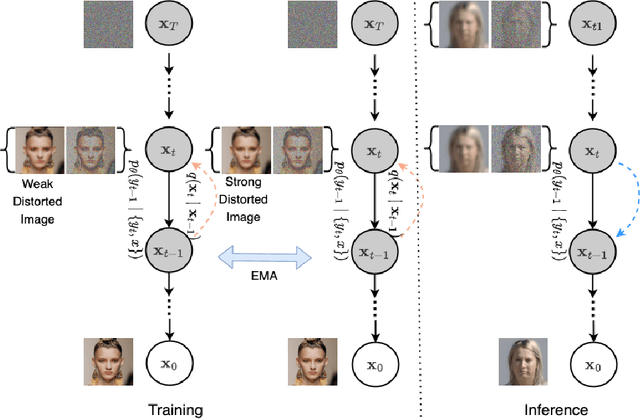
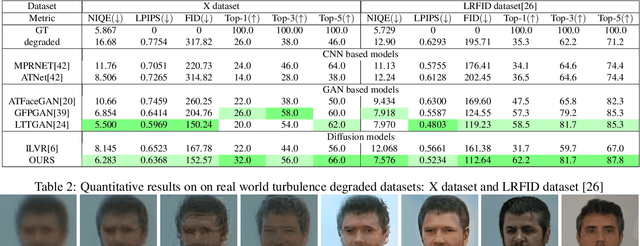

Although many long-range imaging systems are designed to support extended vision applications, a natural obstacle to their operation is degradation due to atmospheric turbulence. Atmospheric turbulence causes significant degradation to image quality by introducing blur and geometric distortion. In recent years, various deep learning-based single image atmospheric turbulence mitigation methods, including CNN-based and GAN inversion-based, have been proposed in the literature which attempt to remove the distortion in the image. However, some of these methods are difficult to train and often fail to reconstruct facial features and produce unrealistic results especially in the case of high turbulence. Denoising Diffusion Probabilistic Models (DDPMs) have recently gained some traction because of their stable training process and their ability to generate high quality images. In this paper, we propose the first DDPM-based solution for the problem of atmospheric turbulence mitigation. We also propose a fast sampling technique for reducing the inference times for conditional DDPMs. Extensive experiments are conducted on synthetic and real-world data to show the significance of our model. To facilitate further research, all codes and pretrained models will be made public after the review process.
Orientation-guided Graph Convolutional Network for Bone Surface Segmentation
Jun 16, 2022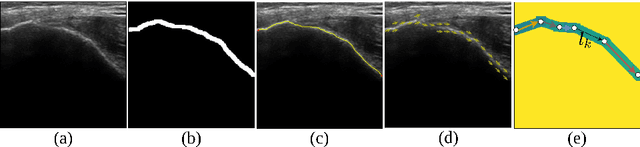
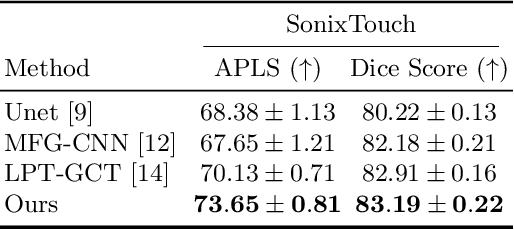
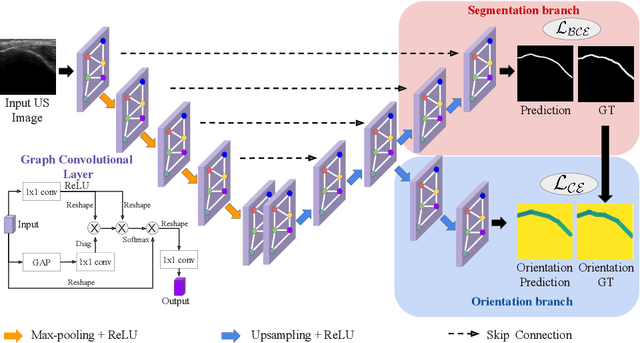
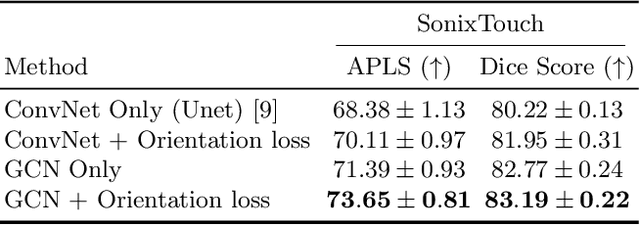
Due to imaging artifacts and low signal-to-noise ratio in ultrasound images, automatic bone surface segmentation networks often produce fragmented predictions that can hinder the success of ultrasound-guided computer-assisted surgical procedures. Existing pixel-wise predictions often fail to capture the accurate topology of bone tissues due to a lack of supervision to enforce connectivity. In this work, we propose an orientation-guided graph convolutional network to improve connectivity while segmenting the bone surface. We also propose an additional supervision on the orientation of the bone surface to further impose connectivity. We validated our approach on 1042 vivo US scans of femur, knee, spine, and distal radius. Our approach improves over the state-of-the-art methods by 5.01% in connectivity metric.
Simultaneous Bone and Shadow Segmentation Network using Task Correspondence Consistency
Jun 16, 2022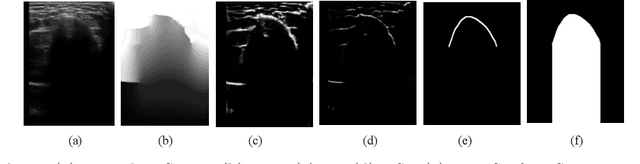
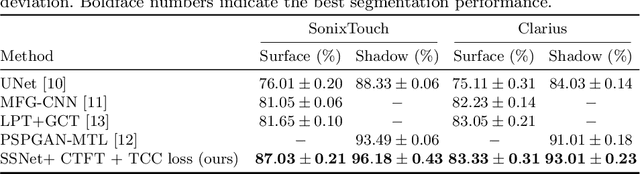
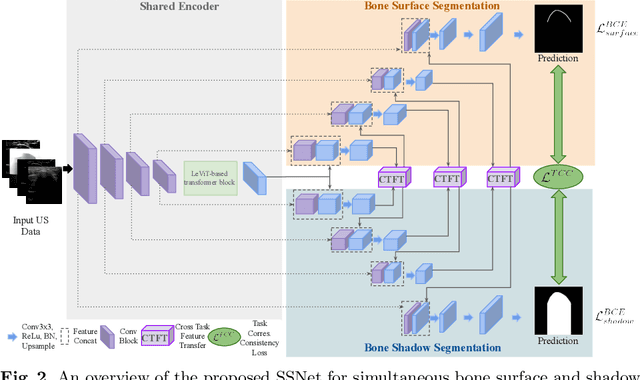

Segmenting both bone surface and the corresponding acoustic shadow are fundamental tasks in ultrasound (US) guided orthopedic procedures. However, these tasks are challenging due to minimal and blurred bone surface response in US images, cross-machine discrepancy, imaging artifacts, and low signal-to-noise ratio. Notably, bone shadows are caused by a significant acoustic impedance mismatch between the soft tissue and bone surfaces. To leverage this mutual information between these highly related tasks, we propose a single end-to-end network with a shared transformer-based encoder and task independent decoders for simultaneous bone and shadow segmentation. To share complementary features, we propose a cross task feature transfer block which learns to transfer meaningful features from decoder of shadow segmentation to that of bone segmentation and vice-versa. We also introduce a correspondence consistency loss which makes sure that network utilizes the inter-dependency between the bone surface and its corresponding shadow to refine the segmentation. Validation against expert annotations shows that the method outperforms the previous state-of-the-art for both bone surface and shadow segmentation.
Image Generation with Multimodal Priors using Denoising Diffusion Probabilistic Models
Jun 10, 2022



Image synthesis under multi-modal priors is a useful and challenging task that has received increasing attention in recent years. A major challenge in using generative models to accomplish this task is the lack of paired data containing all modalities (i.e. priors) and corresponding outputs. In recent work, a variational auto-encoder (VAE) model was trained in a weakly supervised manner to address this challenge. Since the generative power of VAEs is usually limited, it is difficult for this method to synthesize images belonging to complex distributions. To this end, we propose a solution based on a denoising diffusion probabilistic models to synthesise images under multi-model priors. Based on the fact that the distribution over each time step in the diffusion model is Gaussian, in this work we show that there exists a closed-form expression to the generate the image corresponds to the given modalities. The proposed solution does not require explicit retraining for all modalities and can leverage the outputs of individual modalities to generate realistic images according to different constraints. We conduct studies on two real-world datasets to demonstrate the effectiveness of our approach
Realistic Ultrasound Image Synthesis for Improved Classification of Liver Disease
Jul 27, 2021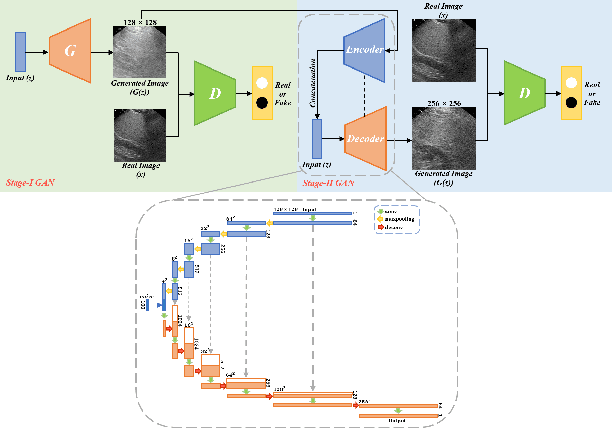

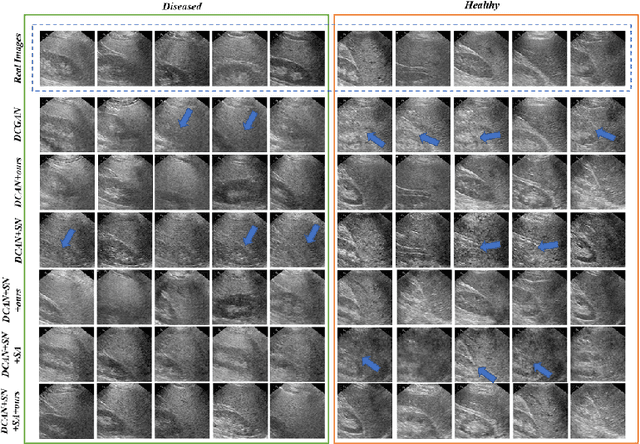
With the success of deep learning-based methods applied in medical image analysis, convolutional neural networks (CNNs) have been investigated for classifying liver disease from ultrasound (US) data. However, the scarcity of available large-scale labeled US data has hindered the success of CNNs for classifying liver disease from US data. In this work, we propose a novel generative adversarial network (GAN) architecture for realistic diseased and healthy liver US image synthesis. We adopt the concept of stacking to synthesize realistic liver US data. Quantitative and qualitative evaluation is performed on 550 in-vivo B-mode liver US images collected from 55 subjects. We also show that the synthesized images, together with real in vivo data, can be used to significantly improve the performance of traditional CNN architectures for Nonalcoholic fatty liver disease (NAFLD) classification.
Network Architecture Search for Face Enhancement
May 13, 2021
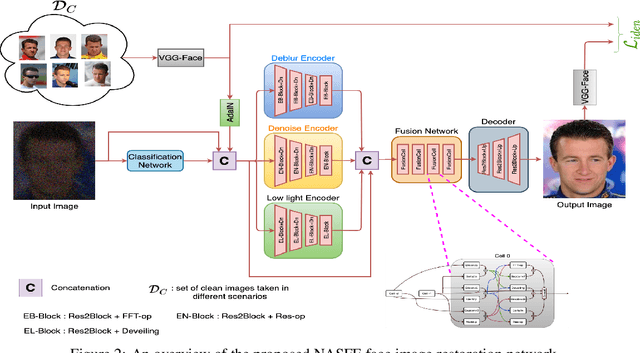
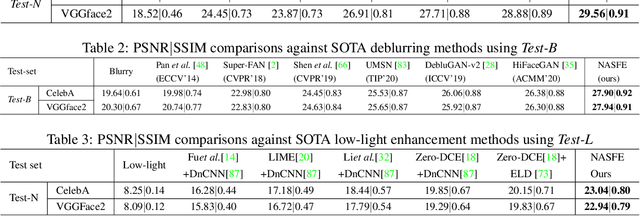
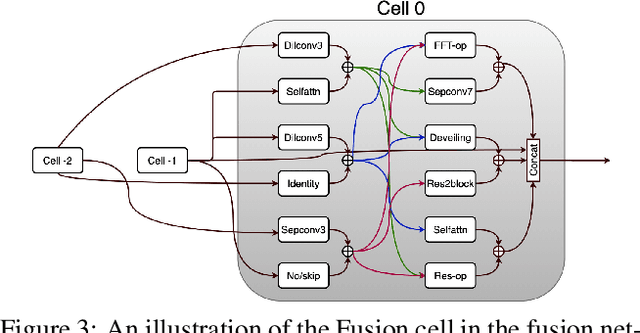
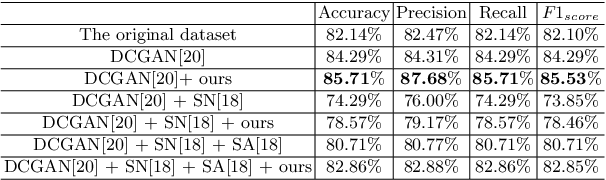
Various factors such as ambient lighting conditions, noise, motion blur, etc. affect the quality of captured face images. Poor quality face images often reduce the performance of face analysis and recognition systems. Hence, it is important to enhance the quality of face images collected in such conditions. We present a multi-task face restoration network, called Network Architecture Search for Face Enhancement (NASFE), which can enhance poor quality face images containing a single degradation (i.e. noise or blur) or multiple degradations (noise+blur+low-light). During training, NASFE uses clean face images of a person present in the degraded image to extract the identity information in terms of features for restoring the image. Furthermore, the network is guided by an identity-loss so that the identity in-formation is maintained in the restored image. Additionally, we propose a network architecture search-based fusion network in NASFE which fuses the task-specific features that are extracted using the task-specific encoders. We introduce FFT-op and deveiling operators in the fusion network to efficiently fuse the task-specific features. Comprehensive experiments on synthetic and real images demonstrate that the proposed method outperforms many recent state-of-the-art face restoration and enhancement methods in terms of quantitative and visual performance.
Learning to Restore a Single Face Image Degraded by Atmospheric Turbulence using CNNs
Jul 16, 2020
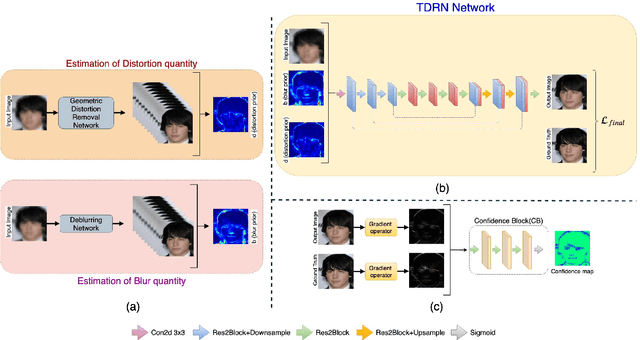


Atmospheric turbulence significantly affects imaging systems which use light that has propagated through long atmospheric paths. Images captured under such condition suffer from a combination of geometric deformation and space varying blur. We present a deep learning-based solution to the problem of restoring a turbulence-degraded face image where prior information regarding the amount of geometric distortion and blur at each location of the face image is first estimated using two separate networks. The estimated prior information is then used by a network called, Turbulence Distortion Removal Network (TDRN), to correct geometric distortion and reduce blur in the face image. Furthermore, a novel loss is proposed to train TDRN where first and second order image gradients are computed along with their confidence maps to mitigate the effect of turbulence degradation. Comprehensive experiments on synthetic and real face images show that this framework is capable of alleviating blur and geometric distortion caused by atmospheric turbulence, and significantly improves the visual quality. In addition, an ablation study is performed to demonstrate the improvements obtained by different modules in the proposed method.