 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Scalable Cross-Domain Graph Neural Networks for Personalized Notification at LinkedIn
Jun 15, 2025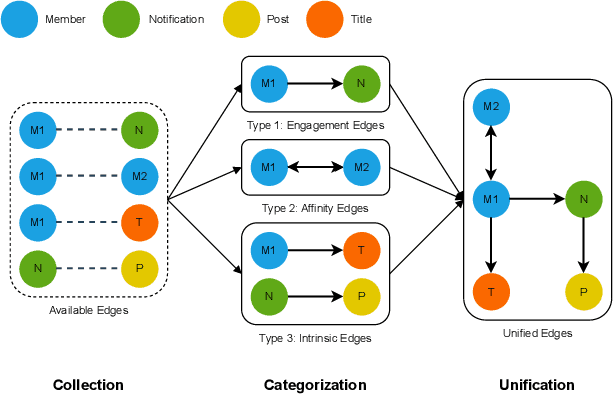
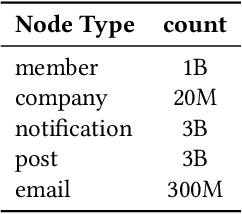
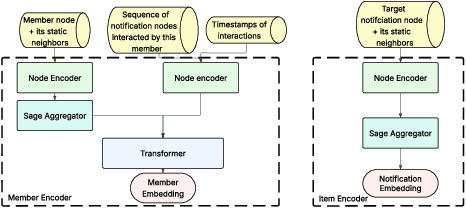

Notification recommendation systems are critical to driving user engagement on professional platforms like LinkedIn. Designing such systems involves integrating heterogeneous signals across domains, capturing temporal dynamics, and optimizing for multiple, often competing, objectives. Graph Neural Networks (GNNs) provide a powerful framework for modeling complex interactions in such environments. In this paper, we present a cross-domain GNN-based system deployed at LinkedIn that unifies user, content, and activity signals into a single, large-scale graph. By training on this cross-domain structure, our model significantly outperforms single-domain baselines on key tasks, including click-through rate (CTR) prediction and professional engagement. We introduce architectural innovations including temporal modeling and multi-task learning, which further enhance performance. Deployed in LinkedIn's notification system, our approach led to a 0.10% lift in weekly active users and a 0.62% improvement in CTR. We detail our graph construction process, model design, training pipeline, and both offline and online evaluations. Our work demonstrates the scalability and effectiveness of cross-domain GNNs in real-world, high-impact applications.
AlphaPO -- Reward shape matters for LLM alignment
Jan 07, 2025Reinforcement Learning with Human Feedback (RLHF) and its variants have made huge strides toward the effective alignment of large language models (LLMs) to follow instructions and reflect human values. More recently, Direct Alignment Algorithms (DAAs) have emerged in which the reward modeling stage of RLHF is skipped by characterizing the reward directly as a function of the policy being learned. Examples include Direct Preference Optimization (DPO) and Simple Preference Optimization (SimPO). These methods often suffer from likelihood displacement, a phenomenon by which the probabilities of preferred responses are often reduced undesirably. In this paper, we argue that, for DAAs the reward (function) shape matters. We introduce AlphaPO, a new DAA method that leverages an $\alpha$-parameter to help change the shape of the reward function beyond the standard log reward. AlphaPO helps maintain fine-grained control over likelihood displacement and over-optimization. Compared to SimPO, one of the best performing DAAs, AlphaPO leads to about 7\% to 10\% relative improvement in alignment performance for the instruct versions of Mistral-7B and Llama3-8B. The analysis and results presented highlight the importance of the reward shape, and how one can systematically change it to affect training dynamics, as well as improve alignment performance.