 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming Copyright Barriers in Corpus Distribution Through Non-Reversible Hashing
Apr 25, 2026While annotated corpora are crucial in the field of natural language processing (NLP), those containing copyrighted material are difficult to exchange among researchers. Yet, such corpora are necessary to fully represent the diversity of data found in the wild in the context of NLP tasks. We tackle this issue by proposing a method to lawfully and publicly share the annotations of copyrighted literary texts. The corpus creator shares the annotations in clear, along with a non-reversible hashed version of the source material. The corpus user must own the source material, and apply the same hash function to their own tokens, in order to match them to the shared annotations. Crucially, our method is robust to reasonable divergences in the version of the copyrighted data owned by the user. As an illustration, we present alignment experiments on different editions of novels. Our results show that our method is able to correctly align 98.7 to 99.79% of tokens depending on the novel, provided the user version is sufficiently close to the corpus creator's version. We publicly release novelshare, a Python implementation of our method.
FedSV: Byzantine-Robust Federated Learning via Shapley Value
Feb 24, 2025
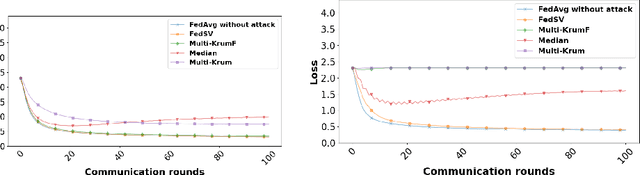


In Federated Learning (FL), several clients jointly learn a machine learning model: each client maintains a local model for its local learning dataset, while a master server maintains a global model by aggregating the local models of the client devices. However, the repetitive communication between server and clients leaves room for attacks aimed at compromising the integrity of the global model, causing errors in its targeted predictions. In response to such threats on FL, various defense measures have been proposed in the literature. In this paper, we present a powerful defense against malicious clients in FL, called FedSV, using the Shapley Value (SV), which has been proposed recently to measure user contribution in FL by computing the marginal increase of average accuracy of the model due to the addition of local data of a user. Our approach makes the identification of malicious clients more robust, since during the learning phase, it estimates the contribution of each client according to the different groups to which the target client belongs. FedSV's effectiveness is demonstrated by extensive experiments on MNIST datasets in a cross-silo context under various attacks.
The Role of Natural Language Processing Tasks in Automatic Literary Character Network Construction
Dec 16, 2024



The automatic extraction of character networks from literary texts is generally carried out using natural language processing (NLP) cascading pipelines. While this approach is widespread, no study exists on the impact of low-level NLP tasks on their performance. In this article, we conduct such a study on a literary dataset, focusing on the role of named entity recognition (NER) and coreference resolution when extracting co-occurrence networks. To highlight the impact of these tasks' performance, we start with gold-standard annotations, progressively add uniformly distributed errors, and observe their impact in terms of character network quality. We demonstrate that NER performance depends on the tested novel and strongly affects character detection. We also show that NER-detected mentions alone miss a lot of character co-occurrences, and that coreference resolution is needed to prevent this. Finally, we present comparison points with 2 methods based on large language models (LLMs), including a fully end-to-end one, and show that these models are outperformed by traditional NLP pipelines in terms of recall.
Interconnected Kingdoms: Comparing 'A Song of Ice and Fire' Adaptations Across Media Using Complex Networks
Oct 07, 2024In this article, we propose and apply a method to compare adaptations of the same story across different media. We tackle this task by modelling such adaptations through character networks. We compare them by leveraging two concepts at the core of storytelling: the characters involved, and the dynamics of the story. We propose several methods to match characters between media and compare their position in the networks; and perform narrative matching, i.e. match the sequences of narrative units that constitute the plots. We apply these methods to the novel series \textit{A Song of Ice and Fire}, by G.R.R. Martin, and its comics and TV show adaptations. Our results show that interactions between characters are not sufficient to properly match individual characters between adaptations, but that using some additional information such as character affiliation or gender significantly improves the performance. On the contrary, character interactions convey enough information to perform narrative matching, and allow us to detect the divergence between the original novels and its TV show adaptation.
Annotation Guidelines for Corpus Novelties: Part 2 -- Alias Resolution Version 1.0
Oct 01, 2024The Novelties corpus is a collection of novels (and parts of novels) annotated for Alias Resolution, among other tasks. This document describes the guidelines applied during the annotation process. It contains the instructions used by the annotators, as well as a number of examples retrieved from the annotated novels, and illustrating how canonical names should be defined, and which names should be considered as referring to the same entity.
Whole-Graph Representation Learning For the Classification of Signed Networks
Sep 30, 2024



Graphs are ubiquitous for modeling complex systems involving structured data and relationships. Consequently, graph representation learning, which aims to automatically learn low-dimensional representations of graphs, has drawn a lot of attention in recent years. The overwhelming majority of existing methods handle unsigned graphs. However, signed graphs appear in an increasing number of application domains to model systems involving two types of opposed relationships. Several authors took an interest in signed graphs and proposed methods for providing vertex-level representations, but only one exists for whole-graph representations, and it can handle only fully connected graphs. In this article, we tackle this issue by proposing two approaches to learning whole-graph representations of general signed graphs. The first is a SG2V, a signed generalization of the whole-graph embedding method Graph2vec that relies on a modification of the Weisfeiler--Lehman relabelling procedure. The second one is WSGCN, a whole-graph generalization of the signed vertex embedding method SGCN that relies on the introduction of master nodes into the GCN. We propose several variants of both these approaches. A bottleneck in the development of whole-graph-oriented methods is the lack of data. We constitute a benchmark composed of three collections of signed graphs with corresponding ground truths. We assess our methods on this benchmark, and our results show that the signed whole-graph methods learn better representations for this task. Overall, the baseline obtains an F-measure score of 58.57, when SG2V and WSGCN reach 73.01 and 81.20, respectively. Our source code and benchmark dataset are both publicly available online.
Renard: A Modular Pipeline for Extracting Character Networks from Narrative Texts
Jul 02, 2024

Renard (Relationships Extraction from NARrative Documents) is a Python library that allows users to define custom natural language processing (NLP) pipelines to extract character networks from narrative texts. Contrary to the few existing tools, Renard can extract dynamic networks, as well as the more common static networks. Renard pipelines are modular: users can choose the implementation of each NLP subtask needed to extract a character network. This allows users to specialize pipelines to particular types of texts and to study the impact of each subtask on the extracted network.
* Accepted at JOSS
Link Prediction in Bipartite Networks
Jun 10, 2024



Bipartite networks serve as highly suitable models to represent systems involving interactions between two distinct types of entities, such as online dating platforms, job search services, or ecommerce websites. These models can be leveraged to tackle a number of tasks, including link prediction among the most useful ones, especially to design recommendation systems. However, if this task has garnered much interest when conducted on unipartite (i.e. standard) networks, it is far from being the case for bipartite ones. In this study, we address this gap by performing an experimental comparison of 19 link prediction methods able to handle bipartite graphs. Some come directly from the literature, and some are adapted by us from techniques originally designed for unipartite networks. We also propose to repurpose recommendation systems based on graph convolutional networks (GCN) as a novel link prediction solution for bipartite networks. To conduct our experiments, we constitute a benchmark of 3 real-world bipartite network datasets with various topologies. Our results indicate that GCN-based personalized recommendation systems, which have received significant attention in recent years, can produce successful results for link prediction in bipartite networks. Furthermore, purely heuristic metrics that do not rely on any learning process, like the Structural Perturbation Method (SPM), can also achieve success.
Learning to Rank Context for Named Entity Recognition Using a Synthetic Dataset
Nov 06, 2023



While recent pre-trained transformer-based models can perform named entity recognition (NER) with great accuracy, their limited range remains an issue when applied to long documents such as whole novels. To alleviate this issue, a solution is to retrieve relevant context at the document level. Unfortunately, the lack of supervision for such a task means one has to settle for unsupervised approaches. Instead, we propose to generate a synthetic context retrieval training dataset using Alpaca, an instructiontuned large language model (LLM). Using this dataset, we train a neural context retriever based on a BERT model that is able to find relevant context for NER. We show that our method outperforms several retrieval baselines for the NER task on an English literary dataset composed of the first chapter of 40 books.
Pattern Mining for Anomaly Detection in Graphs: Application to Fraud in Public Procurement
Jun 19, 2023In the context of public procurement, several indicators called red flags are used to estimate fraud risk. They are computed according to certain contract attributes and are therefore dependent on the proper filling of the contract and award notices. However, these attributes are very often missing in practice, which prohibits red flags computation. Traditional fraud detection approaches focus on tabular data only, considering each contract separately, and are therefore very sensitive to this issue. In this work, we adopt a graph-based method allowing leveraging relations between contracts, to compensate for the missing attributes. We propose PANG (Pattern-Based Anomaly Detection in Graphs), a general supervised framework relying on pattern extraction to detect anomalous graphs in a collection of attributed graphs. Notably, it is able to identify induced subgraphs, a type of pattern widely overlooked in the literature. When benchmarked on standard datasets, its predictive performance is on par with state-of-the-art methods, with the additional advantage of being explainable. These experiments also reveal that induced patterns are more discriminative on certain datasets. When applying PANG to public procurement data, the prediction is superior to other methods, and it identifies subgraph patterns that are characteristic of fraud-prone situations, thereby making it possible to better understand fraudulent behavior.