 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCooperative Initialization based Deep Neural Network Training
Jan 05, 2020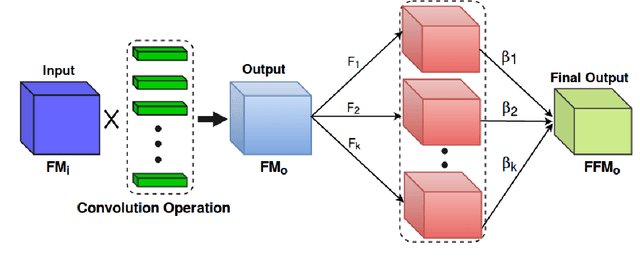

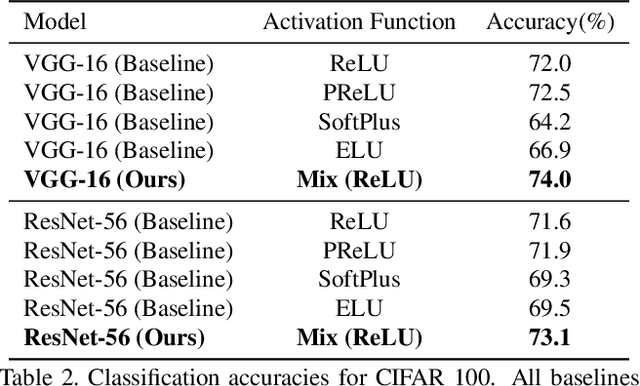
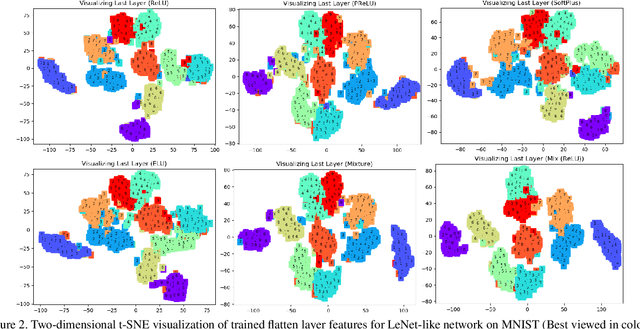
Researchers have proposed various activation functions. These activation functions help the deep network to learn non-linear behavior with a significant effect on training dynamics and task performance. The performance of these activations also depends on the initial state of the weight parameters, i.e., different initial state leads to a difference in the performance of a network. In this paper, we have proposed a cooperative initialization for training the deep network using ReLU activation function to improve the network performance. Our approach uses multiple activation functions in the initial few epochs for the update of all sets of weight parameters while training the network. These activation functions cooperate to overcome their drawbacks in the update of weight parameters, which in effect learn better "feature representation" and boost the network performance later. Cooperative initialization based training also helps in reducing the overfitting problem and does not increase the number of parameters, inference (test) time in the final model while improving the performance. Experiments show that our approach outperforms various baselines and, at the same time, performs well over various tasks such as classification and detection. The Top-1 classification accuracy of the model trained using our approach improves by 2.8% for VGG-16 and 2.1% for ResNet-56 on CIFAR-100 dataset.
Revisiting Paraphrase Question Generator using Pairwise Discriminator
Jan 04, 2020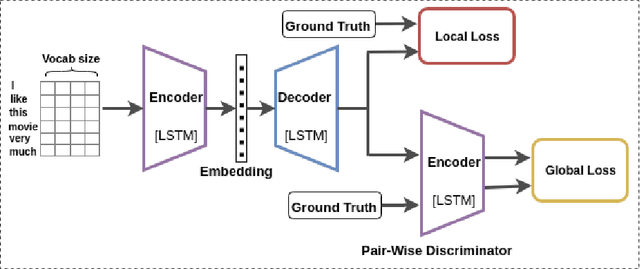
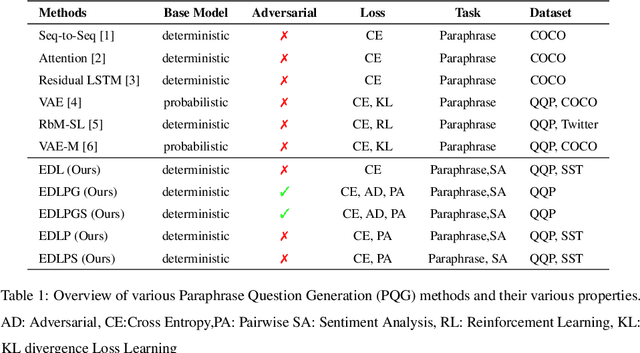
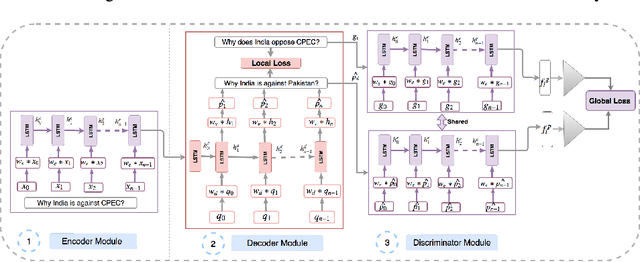
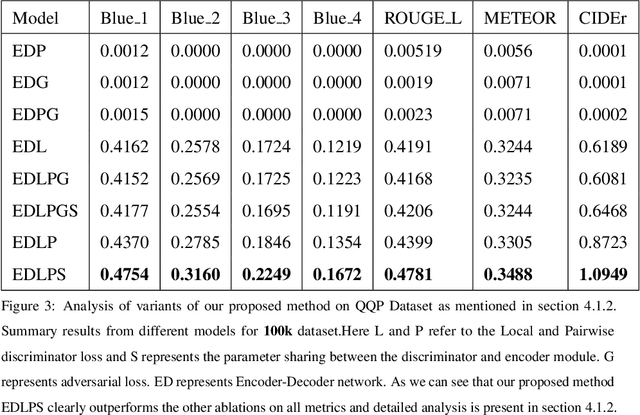
In this paper, we propose a method for obtaining sentence-level embeddings. While the problem of securing word-level embeddings is very well studied, we propose a novel method for obtaining sentence-level embeddings. This is obtained by a simple method in the context of solving the paraphrase generation task. If we use a sequential encoder-decoder model for generating paraphrase, we would like the generated paraphrase to be semantically close to the original sentence. One way to ensure this is by adding constraints for true paraphrase embeddings to be close and unrelated paraphrase candidate sentence embeddings to be far. This is ensured by using a sequential pair-wise discriminator that shares weights with the encoder that is trained with a suitable loss function. Our loss function penalizes paraphrase sentence embedding distances from being too large. This loss is used in combination with a sequential encoder-decoder network. We also validated our method by evaluating the obtained embeddings for a sentiment analysis task. The proposed method results in semantic embeddings and outperforms the state-of-the-art on the paraphrase generation and sentiment analysis task on standard datasets. These results are also shown to be statistically significant.
Deep Exemplar Networks for VQA and VQG
Dec 19, 2019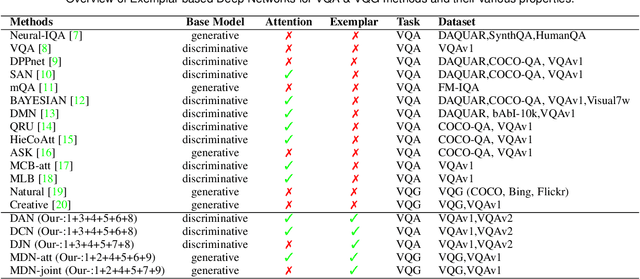
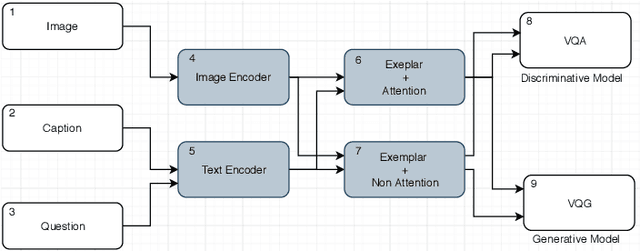
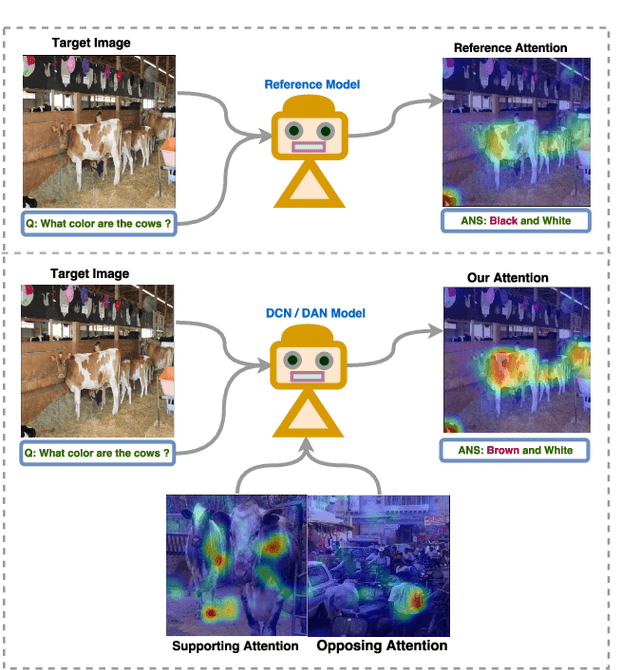
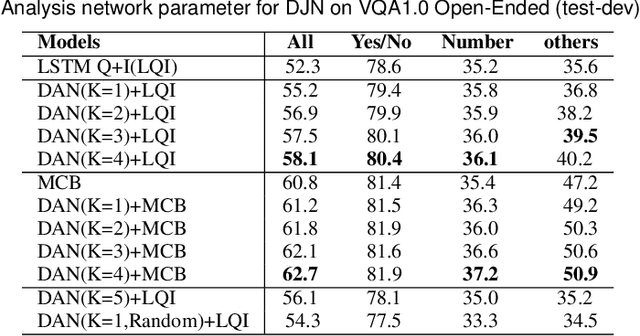
In this paper, we consider the problem of solving semantic tasks such as `Visual Question Answering' (VQA), where one aims to answers related to an image and `Visual Question Generation' (VQG), where one aims to generate a natural question pertaining to an image. Solutions for VQA and VQG tasks have been proposed using variants of encoder-decoder deep learning based frameworks that have shown impressive performance. Humans however often show generalization by relying on exemplar based approaches. For instance, the work by Tversky and Kahneman suggests that humans use exemplars when making categorizations and decisions. In this work, we propose the incorporation of exemplar based approaches towards solving these problems. Specifically, we incorporate exemplar based approaches and show that an exemplar based module can be incorporated in almost any of the deep learning architectures proposed in the literature and the addition of such a block results in improved performance for solving these tasks. Thus, just as the incorporation of attention is now considered de facto useful for solving these tasks, similarly, incorporating exemplars also can be considered to improve any proposed architecture for solving this task. We provide extensive empirical analysis for the same through various architectures, ablations, and state of the art comparisons.
Jointly Trained Image and Video Generation using Residual Vectors
Dec 17, 2019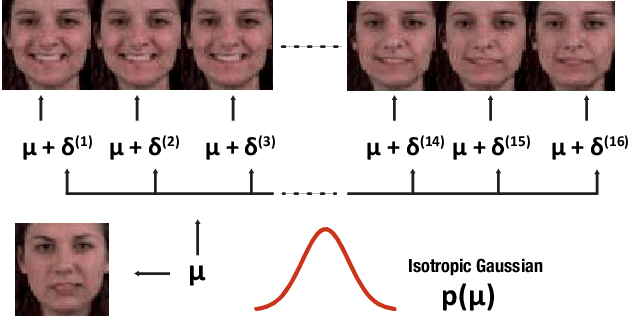
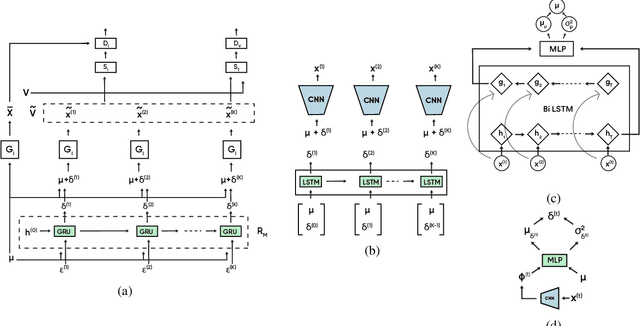
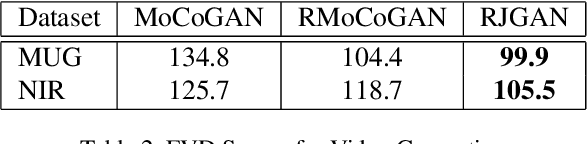

In this work, we propose a modeling technique for jointly training image and video generation models by simultaneously learning to map latent variables with a fixed prior onto real images and interpolate over images to generate videos. The proposed approach models the variations in representations using residual vectors encoding the change at each time step over a summary vector for the entire video. We utilize the technique to jointly train an image generation model with a fixed prior along with a video generation model lacking constraints such as disentanglement. The joint training enables the image generator to exploit temporal information while the video generation model learns to flexibly share information across frames. Moreover, experimental results verify our approach's compatibility with pre-training on videos or images and training on datasets containing a mixture of both. A comprehensive set of quantitative and qualitative evaluations reveal the improvements in sample quality and diversity over both video generation and image generation baselines. We further demonstrate the technique's capabilities of exploiting similarity in features across frames by applying it to a model based on decomposing the video into motion and content. The proposed model allows minor variations in content across frames while maintaining the temporal dependence through latent vectors encoding the pose or motion features.
Explanation vs Attention: A Two-Player Game to Obtain Attention for VQA
Nov 19, 2019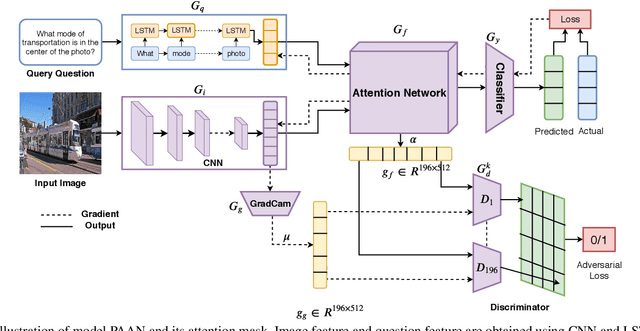
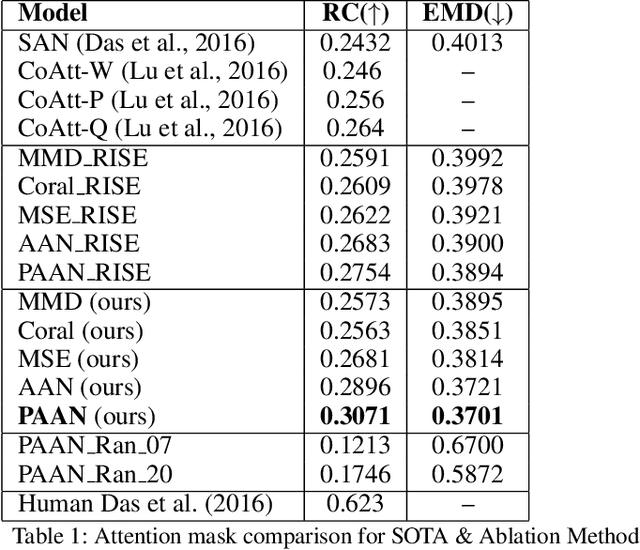
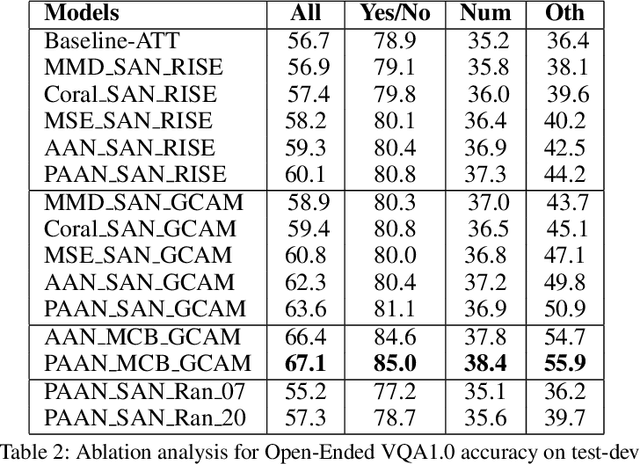
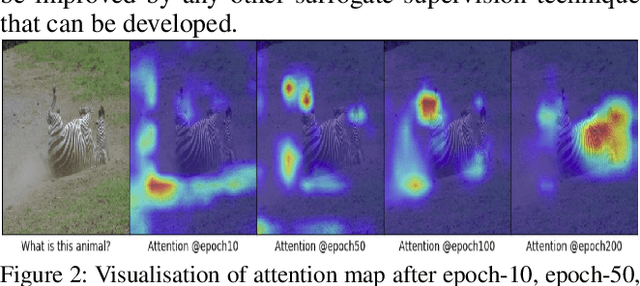
In this paper, we aim to obtain improved attention for a visual question answering (VQA) task. It is challenging to provide supervision for attention. An observation we make is that visual explanations as obtained through class activation mappings (specifically Grad-CAM) that are meant to explain the performance of various networks could form a means of supervision. However, as the distributions of attention maps and that of Grad-CAMs differ, it would not be suitable to directly use these as a form of supervision. Rather, we propose the use of a discriminator that aims to distinguish samples of visual explanation and attention maps. The use of adversarial training of the attention regions as a two-player game between attention and explanation serves to bring the distributions of attention maps and visual explanations closer. Significantly, we observe that providing such a means of supervision also results in attention maps that are more closely related to human attention resulting in a substantial improvement over baseline stacked attention network (SAN) models. It also results in a good improvement in rank correlation metric on the VQA task. This method can also be combined with recent MCB based methods and results in consistent improvement. We also provide comparisons with other means for learning distributions such as based on Correlation Alignment (Coral), Maximum Mean Discrepancy (MMD) and Mean Square Error (MSE) losses and observe that the adversarial loss outperforms the other forms of learning the attention maps. Visualization of the results also confirms our hypothesis that attention maps improve using this form of supervision.
Can I teach a robot to replicate a line art
Oct 17, 2019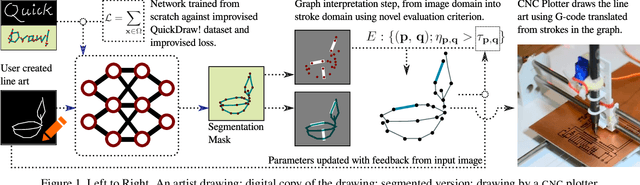

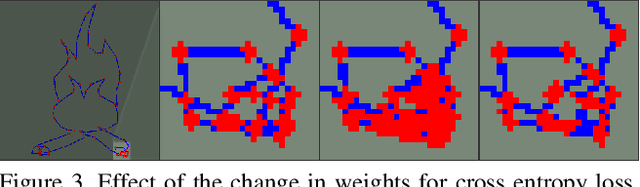
Line art is arguably one of the fundamental and versatile modes of expression. We propose a pipeline for a robot to look at a grayscale line art and redraw it. The key novel elements of our pipeline are: a) we propose a novel task of mimicking line drawings, b) to solve the pipeline we modify the Quick-draw dataset to obtain supervised training for converting a line drawing into a series of strokes c) we propose a multi-stage segmentation and graph interpretation pipeline for solving the problem. The resultant method has also been deployed on a CNC plotter as well as a robotic arm. We have trained several variations of the proposed methods and evaluate these on a dataset obtained from Quick-draw. Through the best methods we observe an accuracy of around 98% for this task, which is a significant improvement over the baseline architecture we adapted from. This therefore allows for deployment of the method on robots for replicating line art in a reliable manner. We also show that while the rule-based vectorization methods do suffice for simple drawings, it fails for more complicated sketches, unlike our method which generalizes well to more complicated distributions.
Probabilistic framework for solving Visual Dialog
Oct 17, 2019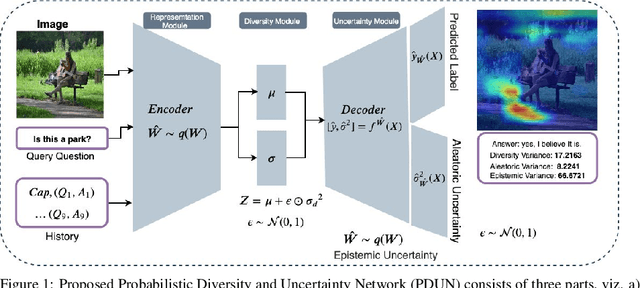
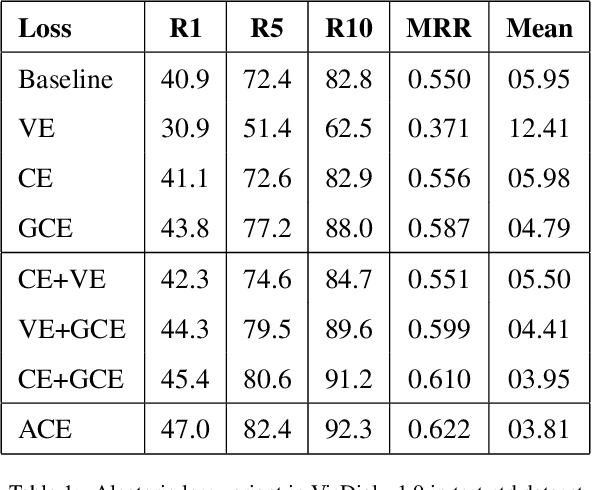

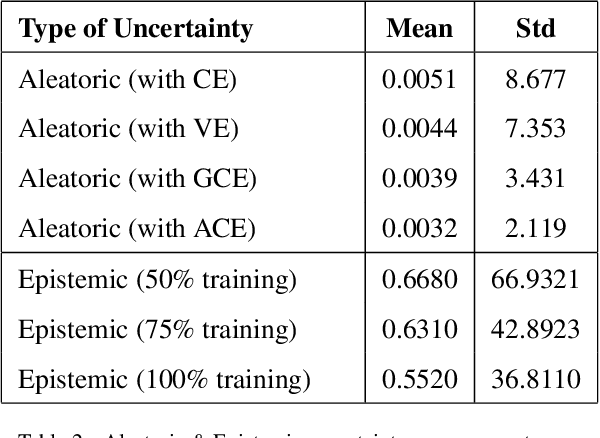
In this paper, we propose a probabilistic framework for solving the task of `Visual Dialog'. Solving this task requires reasoning and understanding of visual modality, language modality, and common sense knowledge to answer. Various architectures have been proposed to solve this task by variants of multi-modal deep learning techniques that combine visual and language representations. However, we believe that it is crucial to understand and analyze the sources of uncertainty for solving this task. Our approach allows for estimating uncertainty and also aids a diverse generation of answers. The proposed approach is obtained through a probabilistic representation module that provides us with representations for image, question and conversation history, a module that ensures that diverse latent representations for candidate answers are obtained given the probabilistic representations and an uncertainty representation module that chooses the appropriate answer that minimizes uncertainty. We thoroughly evaluate the model with a detailed ablation analysis, comparison with state of the art and visualization of the uncertainty that aids in the understanding of the method. Using the proposed probabilistic framework, we thus obtain an improved visual dialog system that is also more explainable.
Dynamic Attention Networks for Task Oriented Grounding
Oct 14, 2019

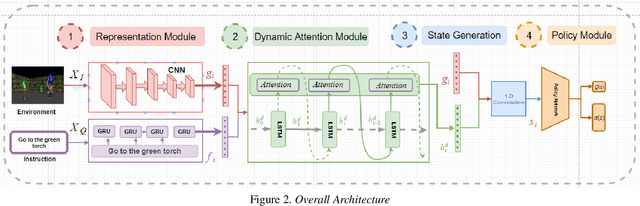
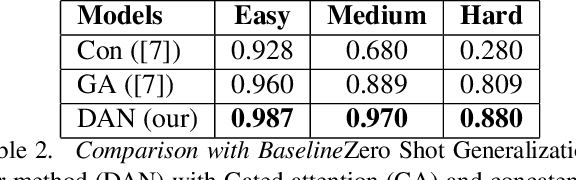
In order to successfully perform tasks specified by natural language instructions, an artificial agent operating in a visual world needs to map words, concepts, and actions from the instruction to visual elements in its environment. This association is termed as Task-Oriented Grounding. In this work, we propose a novel Dynamic Attention Network architecture for the efficient multi-modal fusion of text and visual representations which can generate a robust definition of state for the policy learner. Our model assumes no prior knowledge from visual and textual domains and is an end to end trainable. For a 3D visual world where the observation changes continuously, the attention on the visual elements tends to be highly co-related from a one-time step to the next. We term this as "Dynamic Attention". In this work, we show that Dynamic Attention helps in achieving grounding and also aids in the policy learning objective. Since most practical robotic applications take place in the real world where the observation space is continuous, our framework can be used as a generalized multi-modal fusion unit for robotic control through natural language. We show the effectiveness of using 1D convolution over Gated Attention Hadamard product on the rate of convergence of the network. We demonstrate that the cell-state of a Long Short Term Memory (LSTM) is a natural choice for modeling Dynamic Attention and shows through visualization that the generated attention is very close to how humans tend to focus on the environment.
Granular Multimodal Attention Networks for Visual Dialog
Oct 13, 2019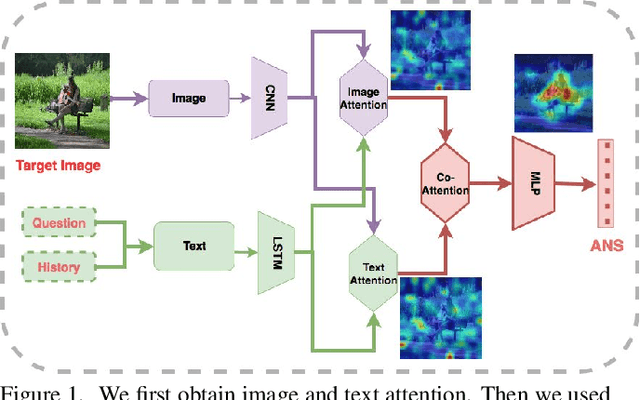
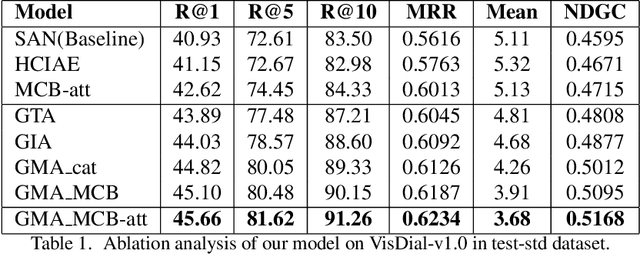
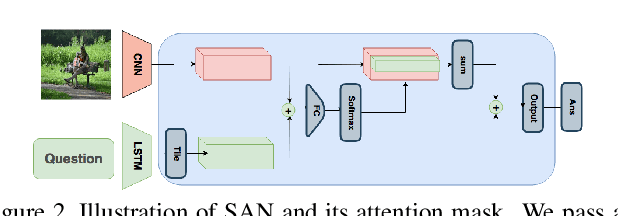
Vision and language tasks have benefited from attention. There have been a number of different attention models proposed. However, the scale at which attention needs to be applied has not been well examined. Particularly, in this work, we propose a new method Granular Multi-modal Attention, where we aim to particularly address the question of the right granularity at which one needs to attend while solving the Visual Dialog task. The proposed method shows improvement in both image and text attention networks. We then propose a granular Multi-modal Attention network that jointly attends on the image and text granules and shows the best performance. With this work, we observe that obtaining granular attention and doing exhaustive Multi-modal Attention appears to be the best way to attend while solving visual dialog.
U-CAM: Visual Explanation using Uncertainty based Class Activation Maps
Sep 16, 2019
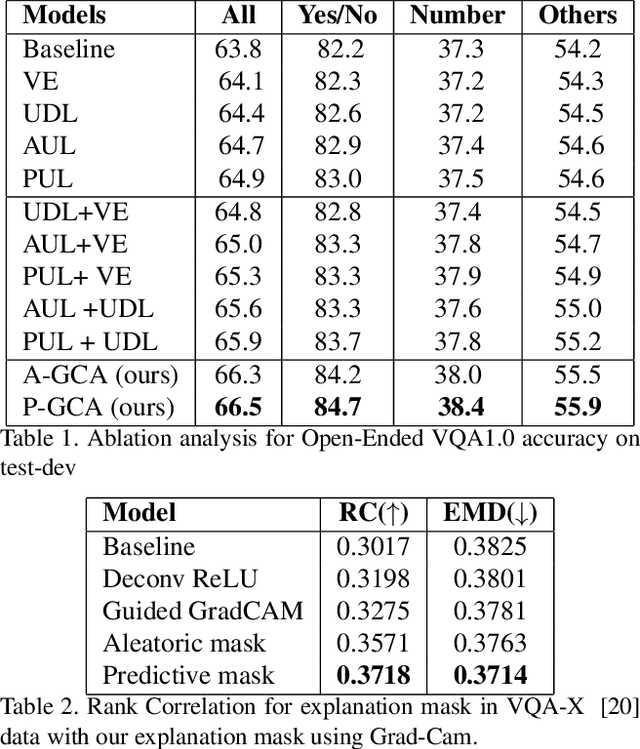
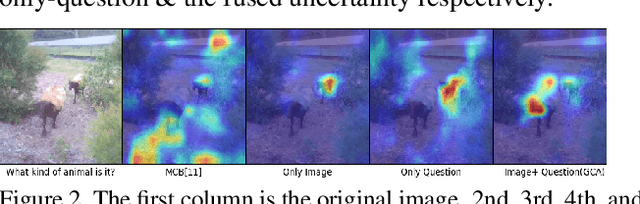
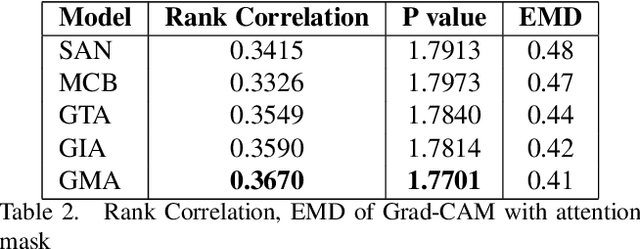
Understanding and explaining deep learning models is an imperative task. Towards this, we propose a method that obtains gradient-based certainty estimates that also provide visual attention maps. Particularly, we solve for visual question answering task. We incorporate modern probabilistic deep learning methods that we further improve by using the gradients for these estimates. These have two-fold benefits: a) improvement in obtaining the certainty estimates that correlate better with misclassified samples and b) improved attention maps that provide state-of-the-art results in terms of correlation with human attention regions. The improved attention maps result in consistent improvement for various methods for visual question answering. Therefore, the proposed technique can be thought of as a recipe for obtaining improved certainty estimates and explanation for deep learning models. We provide detailed empirical analysis for the visual question answering task on all standard benchmarks and comparison with state of the art methods.