 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Low Resource Status of Indian Languages in Machine Translation
Aug 11, 2020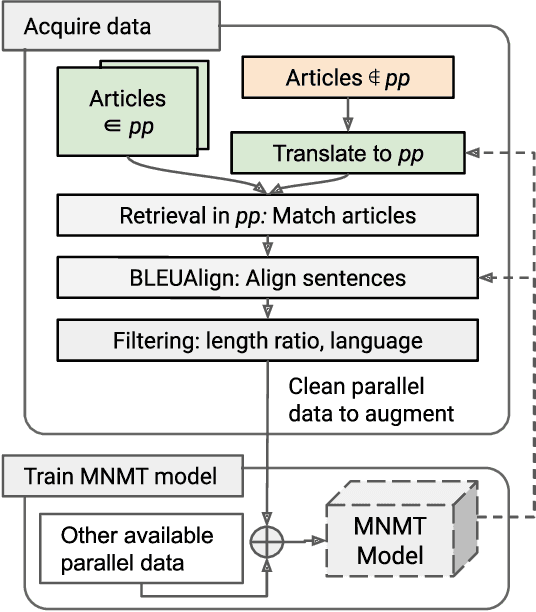
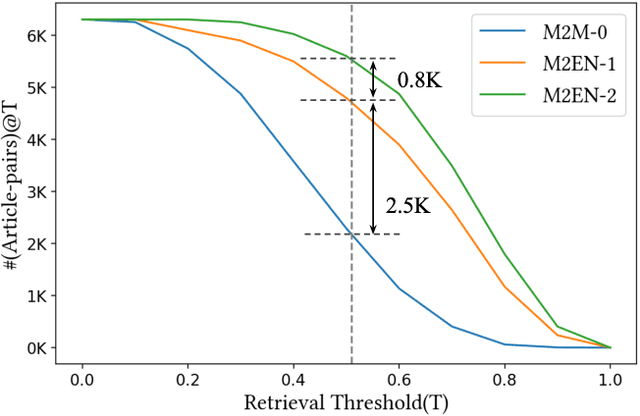
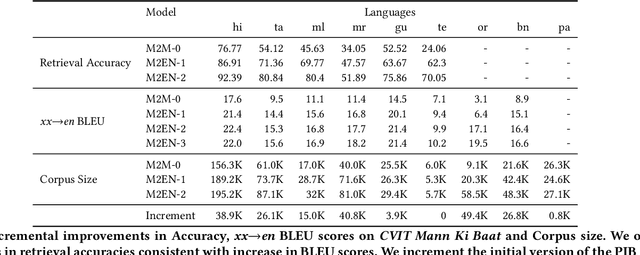
Indian language machine translation performance is hampered due to the lack of large scale multi-lingual sentence aligned corpora and robust benchmarks. Through this paper, we provide and analyse an automated framework to obtain such a corpus for Indian language neural machine translation (NMT) systems. Our pipeline consists of a baseline NMT system, a retrieval module, and an alignment module that is used to work with publicly available websites such as press releases by the government. The main contribution towards this effort is to obtain an incremental method that uses the above pipeline to iteratively improve the size of the corpus as well as improve each of the components of our system. Through our work, we also evaluate the design choices such as the choice of pivoting language and the effect of iterative incremental increase in corpus size. Our work in addition to providing an automated framework also results in generating a relatively larger corpus as compared to existing corpora that are available for Indian languages. This corpus helps us obtain substantially improved results on the publicly available WAT evaluation benchmark and other standard evaluation benchmarks.
A Multilingual Parallel Corpora Collection Effort for Indian Languages
Jul 15, 2020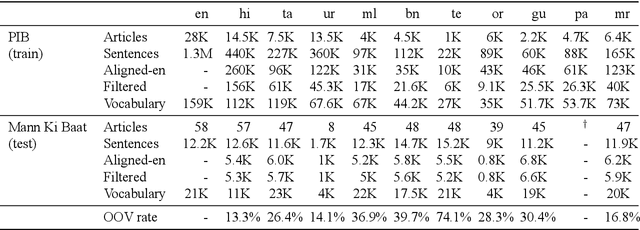


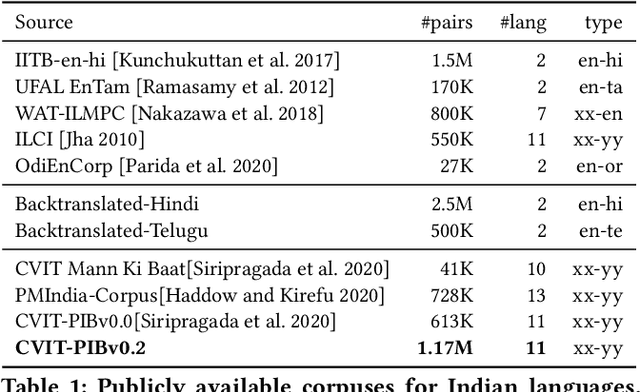
We present sentence aligned parallel corpora across 10 Indian Languages - Hindi, Telugu, Tamil, Malayalam, Gujarati, Urdu, Bengali, Oriya, Marathi, Punjabi, and English - many of which are categorized as low resource. The corpora are compiled from online sources which have content shared across languages. The corpora presented significantly extends present resources that are either not large enough or are restricted to a specific domain (such as health). We also provide a separate test corpus compiled from an independent online source that can be independently used for validating the performance in 10 Indian languages. Alongside, we report on the methods of constructing such corpora using tools enabled by recent advances in machine translation and cross-lingual retrieval using deep neural network based methods.
Learning to Switch CNNs with Model Agnostic Meta Learning for Fine Precision Visual Servoing
Jul 09, 2020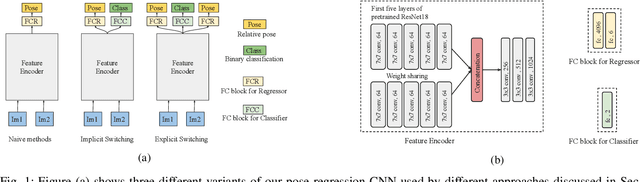

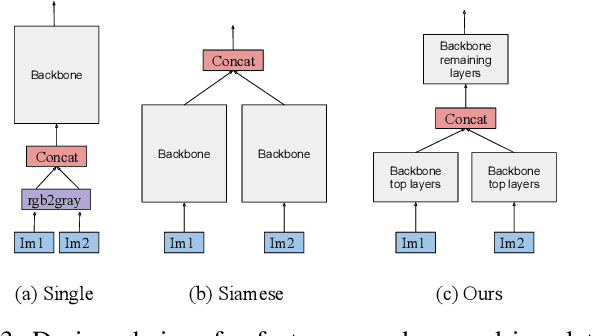
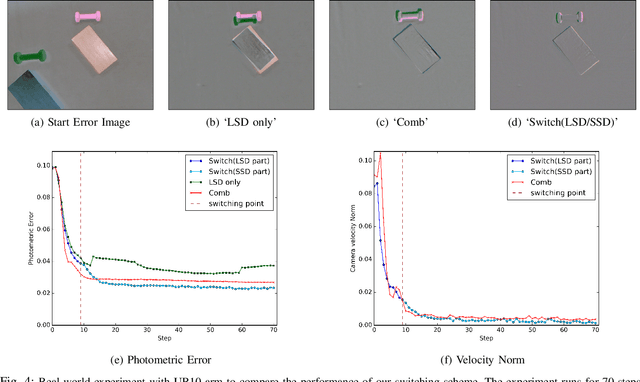
Convolutional Neural Networks (CNNs) have been successfully applied for relative camera pose estimation from labeled image-pair data, without requiring any hand-engineered features, camera intrinsic parameters or depth information. The trained CNN can be utilized for performing pose based visual servo control (PBVS). One of the ways to improve the quality of visual servo output is to improve the accuracy of the CNN for estimating the relative pose estimation. With a given state-of-the-art CNN for relative pose regression, how can we achieve an improved performance for visual servo control? In this paper, we explore switching of CNNs to improve the precision of visual servo control. The idea of switching a CNN is due to the fact that the dataset for training a relative camera pose regressor for visual servo control must contain variations in relative pose ranging from a very small scale to eventually a larger scale. We found that, training two different instances of the CNN, one for large-scale-displacements (LSD) and another for small-scale-displacements (SSD) and switching them during the visual servo execution yields better results than training a single CNN with the combined LSD+SSD data. However, it causes extra storage overhead and switching decision is taken by a manually set threshold which may not be optimal for all the scenes. To eliminate these drawbacks, we propose an efficient switching strategy based on model agnostic meta learning (MAML) algorithm. In this, a single model is trained to learn parameters which are simultaneously good for multiple tasks, namely a binary classification for switching decision, a 6DOF pose regression for LSD data and also a 6DOF pose regression for SSD data. The proposed approach performs far better than the naive approach, while storage and run-time overheads are almost negligible.
Improving Few-Shot Learning using Composite Rotation based Auxiliary Task
Jun 29, 2020
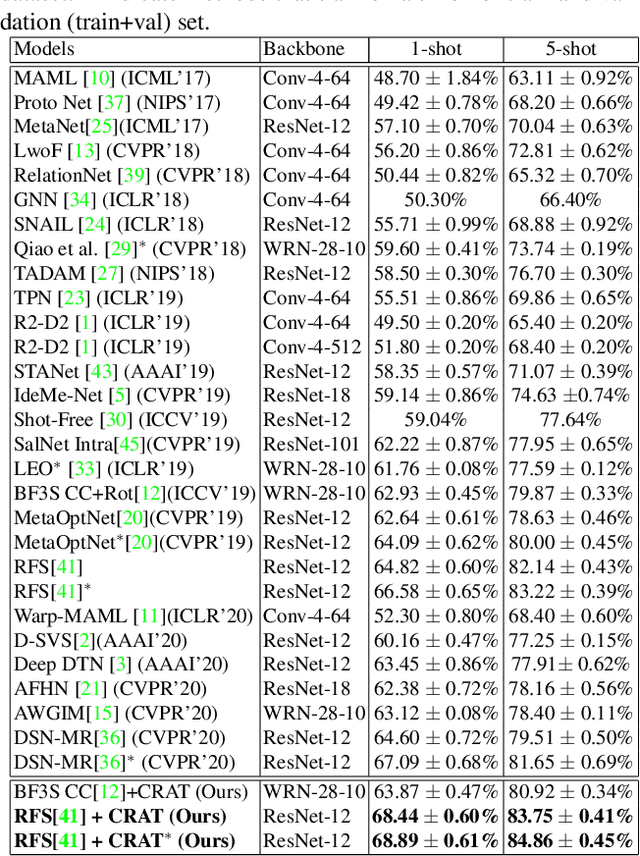
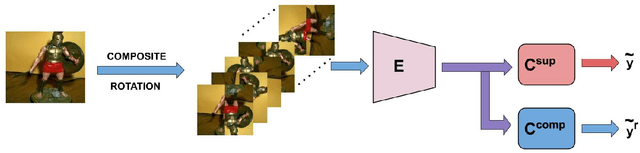
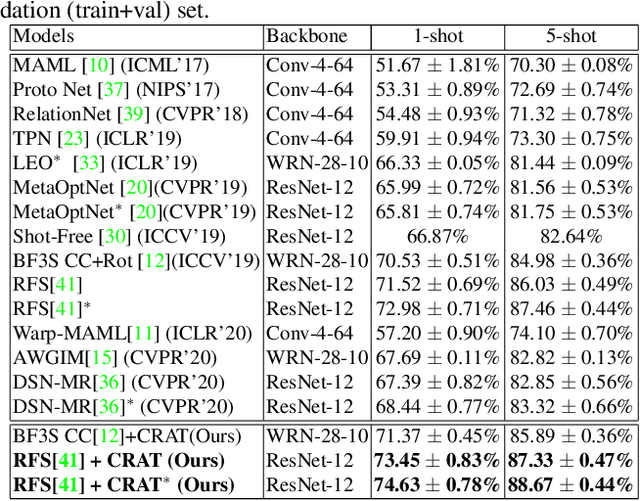
In this paper, we propose an approach to improve few-shot classification performance using a composite rotation based auxiliary task. Few-shot classification methods aim to produce neural networks that perform well for classes with a large number of training samples and classes with less number of training samples. They employ techniques to enable the network to produce highly discriminative features that are also very generic. Generally, the better the quality and generic-nature of the features produced by the network, the better is the performance of the network on few-shot learning. Our approach aims to train networks to produce such features by using a self-supervised auxiliary task. Our proposed composite rotation based auxiliary task performs rotation at two levels, i.e., rotation of patches inside the image (inner rotation) and rotation of the whole image (outer rotation) and assigns one out of 16 rotation classes to the modified image. We then simultaneously train for the composite rotation prediction task along with the original classification task, which forces the network to learn high-quality generic features that help improve the few-shot classification performance. We experimentally show that our approach performs better than existing few-shot learning methods on multiple benchmark datasets.
Passive Batch Injection Training Technique: Boosting Network Performance by Injecting Mini-Batches from a different Data Distribution
Jun 08, 2020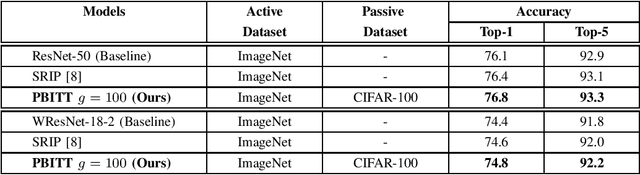
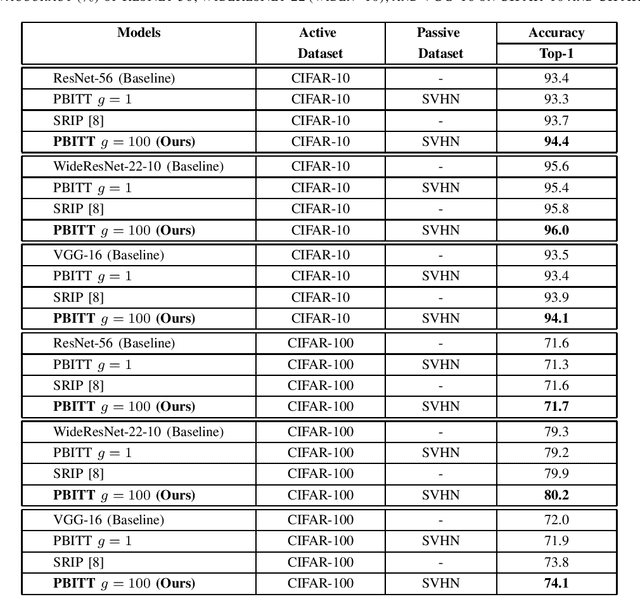

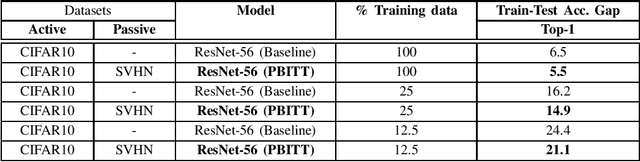
This work presents a novel training technique for deep neural networks that makes use of additional data from a distribution that is different from that of the original input data. This technique aims to reduce overfitting and improve the generalization performance of the network. Our proposed technique, namely Passive Batch Injection Training Technique (PBITT), even reduces the level of overfitting in networks that already use the standard techniques for reducing overfitting such as $L_2$ regularization and batch normalization, resulting in significant accuracy improvements. Passive Batch Injection Training Technique (PBITT) introduces a few passive mini-batches into the training process that contain data from a distribution that is different from the input data distribution. This technique does not increase the number of parameters in the final model and also does not increase the inference (test) time but still improves the performance of deep CNNs. To the best of our knowledge, this is the first work that makes use of different data distribution to aid the training of convolutional neural networks (CNNs). We thoroughly evaluate the proposed approach on standard architectures: VGG, ResNet, and WideResNet, and on several popular datasets: CIFAR-10, CIFAR-100, SVHN, and ImageNet. We observe consistent accuracy improvement by using the proposed technique. We also show experimentally that the model trained by our technique generalizes well to other tasks such as object detection on the MS-COCO dataset using Faster R-CNN. We present extensive ablations to validate the proposed approach. Our approach improves the accuracy of VGG-16 by a significant margin of 2.1% over the CIFAR-100 dataset.
AVGZSLNet: Audio-Visual Generalized Zero-Shot Learning by Reconstructing Label Features from Multi-Modal Embeddings
May 27, 2020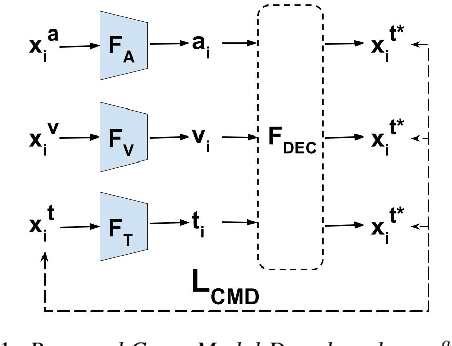
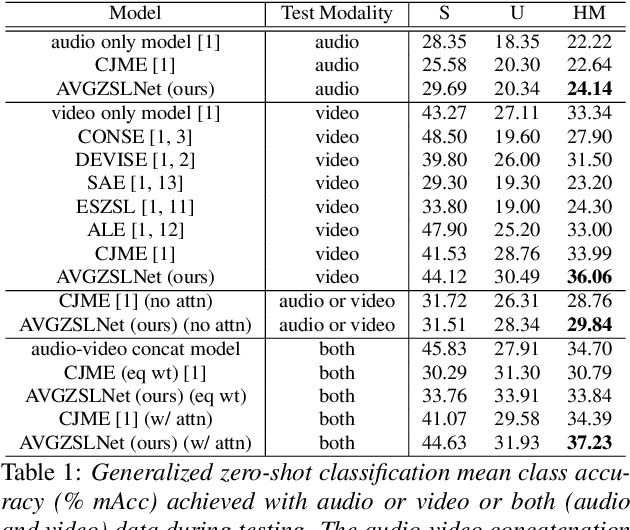
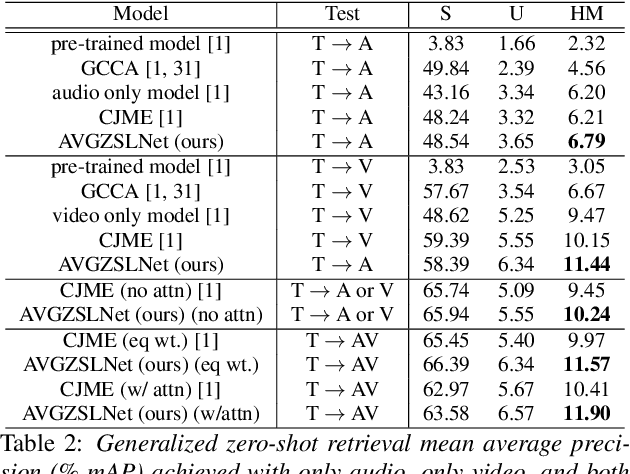

In this paper, we solve for the problem of generalized zero-shot learning in a multi-modal setting, where we have novel classes of audio/video during testing that were not seen during training. We demonstrate that projecting the audio and video embeddings to the class label text feature space allows us to use the semantic relatedness of text embeddings as a means for zero-shot learning. Importantly, our multi-modal zero-shot learning approach works even if a modality is missing at test time. Our approach makes use of a cross-modal decoder which enforces the constraint that the class label text features can be reconstructed from the audio and video embeddings of data points in order to perform better on the multi-modal zero-shot learning task. We further minimize the gap between audio and video embedding distributions using KL-Divergence loss. We test our approach on the zero-shot classification and retrieval tasks, and it performs better than other models in the presence of a single modality as well as in the presence of multiple modalities.
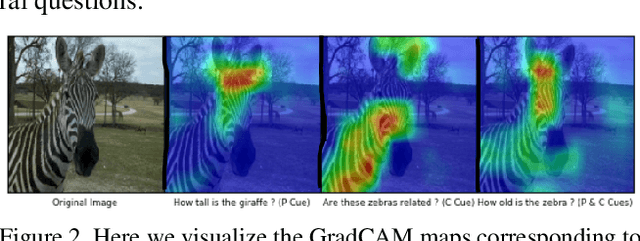
Uncertainty based Class Activation Maps for Visual Question Answering
Jan 23, 2020
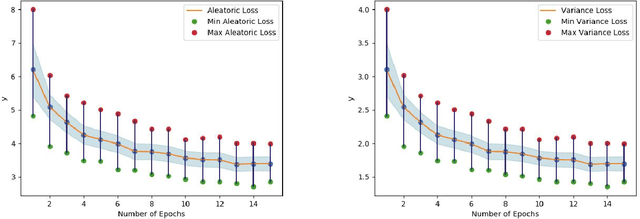
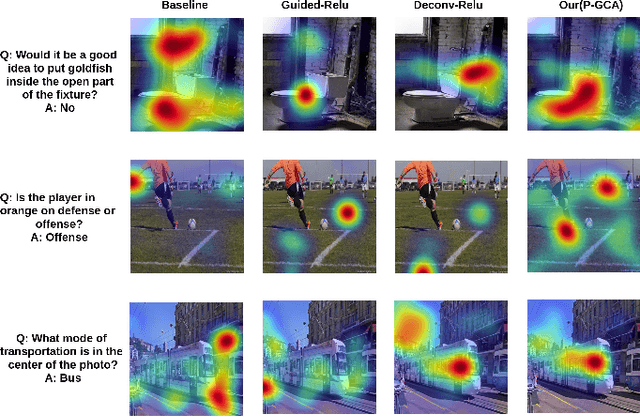
Understanding and explaining deep learning models is an imperative task. Towards this, we propose a method that obtains gradient-based certainty estimates that also provide visual attention maps. Particularly, we solve for visual question answering task. We incorporate modern probabilistic deep learning methods that we further improve by using the gradients for these estimates. These have two-fold benefits: a) improvement in obtaining the certainty estimates that correlate better with misclassified samples and b) improved attention maps that provide state-of-the-art results in terms of correlation with human attention regions. The improved attention maps result in consistent improvement for various methods for visual question answering. Therefore, the proposed technique can be thought of as a recipe for obtaining improved certainty estimates and explanations for deep learning models. We provide detailed empirical analysis for the visual question answering task on all standard benchmarks and comparison with state of the art methods.
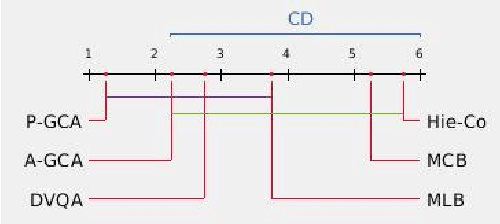
Deep Bayesian Network for Visual Question Generation
Jan 23, 2020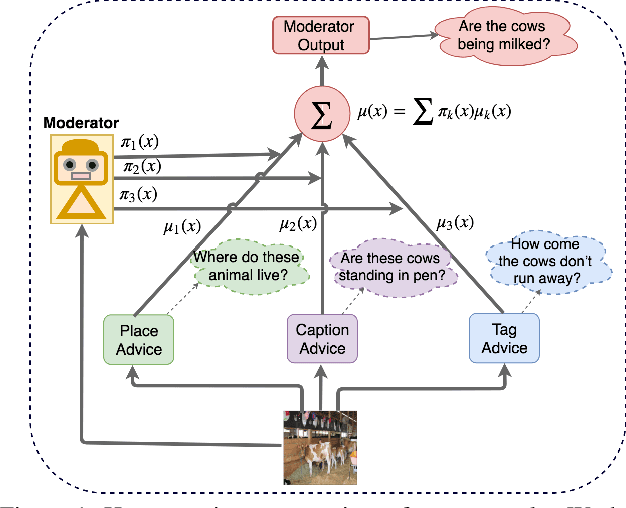
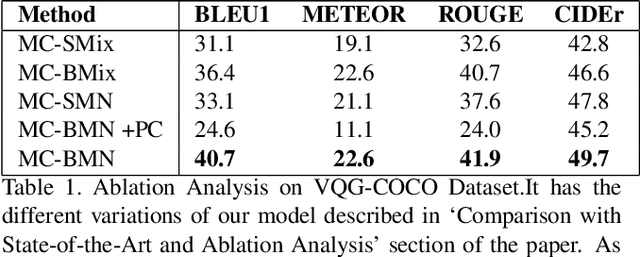
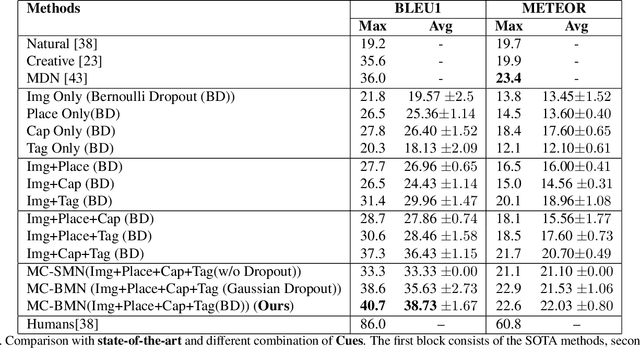
Generating natural questions from an image is a semantic task that requires using vision and language modalities to learn multimodal representations. Images can have multiple visual and language cues such as places, captions, and tags. In this paper, we propose a principled deep Bayesian learning framework that combines these cues to produce natural questions. We observe that with the addition of more cues and by minimizing uncertainty in the among cues, the Bayesian network becomes more confident. We propose a Minimizing Uncertainty of Mixture of Cues (MUMC), that minimizes uncertainty present in a mixture of cues experts for generating probabilistic questions. This is a Bayesian framework and the results show a remarkable similarity to natural questions as validated by a human study. We observe that with the addition of more cues and by minimizing uncertainty among the cues, the Bayesian framework becomes more confident. Ablation studies of our model indicate that a subset of cues is inferior at this task and hence the principled fusion of cues is preferred. Further, we observe that the proposed approach substantially improves over state-of-the-art benchmarks on the quantitative metrics (BLEU-n, METEOR, ROUGE, and CIDEr). Here we provide project link for Deep Bayesian VQG \url{https://delta-lab-iitk.github.io/BVQG/}
Robust Explanations for Visual Question Answering
Jan 23, 2020
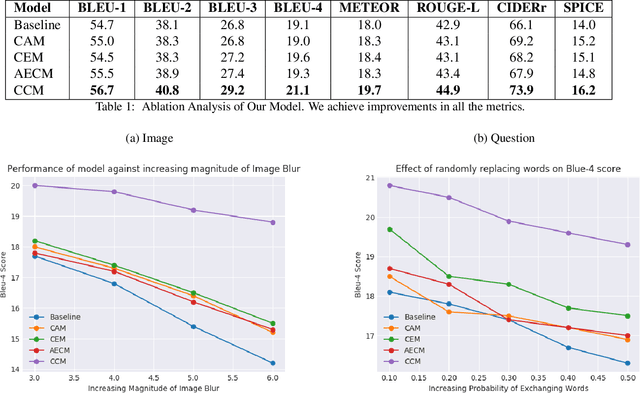
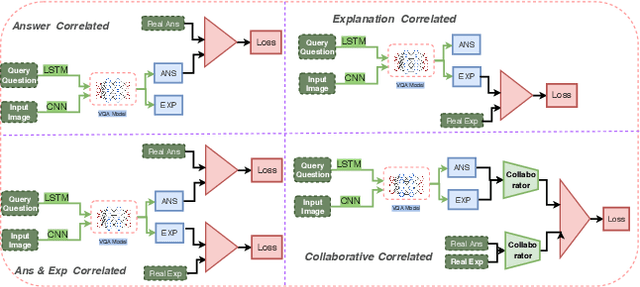
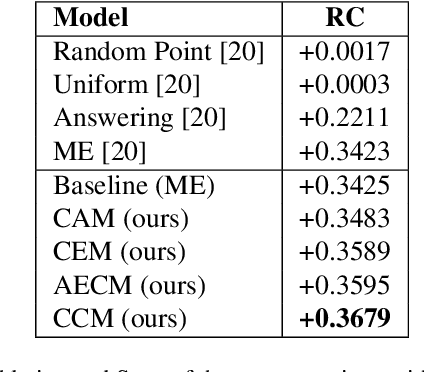
In this paper, we propose a method to obtain robust explanations for visual question answering(VQA) that correlate well with the answers. Our model explains the answers obtained through a VQA model by providing visual and textual explanations. The main challenges that we address are i) Answers and textual explanations obtained by current methods are not well correlated and ii) Current methods for visual explanation do not focus on the right location for explaining the answer. We address both these challenges by using a collaborative correlated module which ensures that even if we do not train for noise based attacks, the enhanced correlation ensures that the right explanation and answer can be generated. We further show that this also aids in improving the generated visual and textual explanations. The use of the correlated module can be thought of as a robust method to verify if the answer and explanations are coherent. We evaluate this model using VQA-X dataset. We observe that the proposed method yields better textual and visual justification that supports the decision. We showcase the robustness of the model against a noise-based perturbation attack using corresponding visual and textual explanations. A detailed empirical analysis is shown. Here we provide source code link for our model \url{https://github.com/DelTA-Lab-IITK/CCM-WACV}.
A "Network Pruning Network" Approach to Deep Model Compression
Jan 15, 2020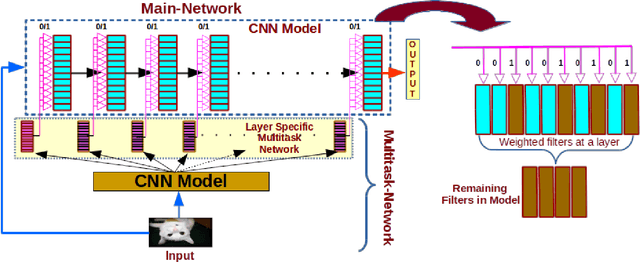
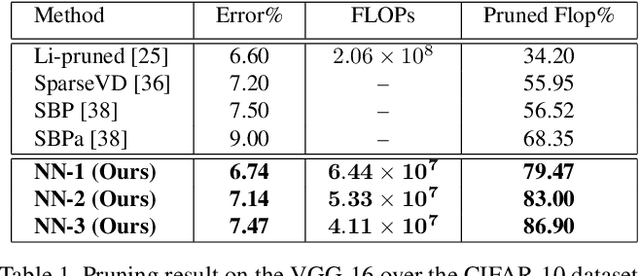
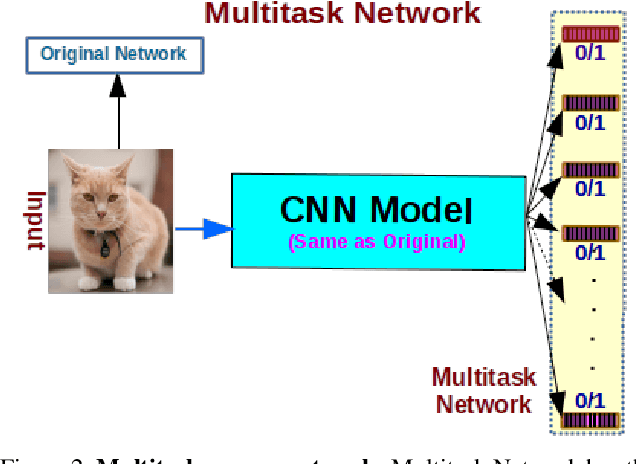
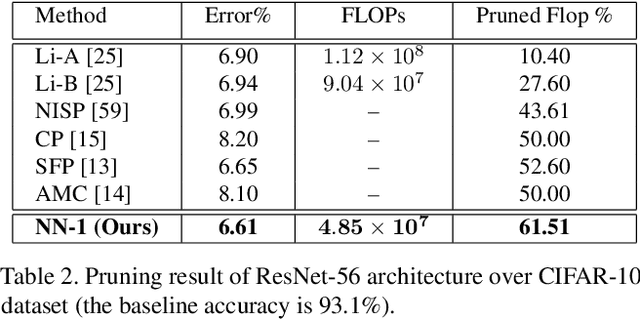
We present a filter pruning approach for deep model compression, using a multitask network. Our approach is based on learning a a pruner network to prune a pre-trained target network. The pruner is essentially a multitask deep neural network with binary outputs that help identify the filters from each layer of the original network that do not have any significant contribution to the model and can therefore be pruned. The pruner network has the same architecture as the original network except that it has a multitask/multi-output last layer containing binary-valued outputs (one per filter), which indicate which filters have to be pruned. The pruner's goal is to minimize the number of filters from the original network by assigning zero weights to the corresponding output feature-maps. In contrast to most of the existing methods, instead of relying on iterative pruning, our approach can prune the network (original network) in one go and, moreover, does not require specifying the degree of pruning for each layer (and can learn it instead). The compressed model produced by our approach is generic and does not need any special hardware/software support. Moreover, augmenting with other methods such as knowledge distillation, quantization, and connection pruning can increase the degree of compression for the proposed approach. We show the efficacy of our proposed approach for classification and object detection tasks.