 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdge-Efficient Image Restoration: Transformer Distillation into State-Space Models
May 04, 2026We propose a modular framework for hybrid image restoration that integrates transformer and state-space model (SSM) blocks with a focus on improving runtime efficiency on edge hardware. While transformers provide strong global modeling through self-attention, their attention kernels incur substantial latency on mobile devices, especially for high-resolution inputs. In contrast, SSMs such as Mamba offer lineartime sequence modeling with lower runtime overhead but may underperform on fine grained restoration tasks. To balance accuracy and efficiency, we train lightweight SSM blocks as feature-distilled surrogates of transformer blocks and use them to construct hybrid U-Net-style architectures. To automatically discover effective block combinations, we introduce Efficient Network Search (ENS), a multi-objective search strategy that selects task-specific hybrid configurations from pre-aligned components. ENS optimizes restoration quality while penalizing transformer usage, serving as a lightweight proxy for latency and enabling architecture discovery without repeated hardware profiling. On a Snapdragon 8 Elite CPU, the Restormer baseline requires 10119.52 ms for inference. In contrast, ENS-discovered hybrids significantly reduce runtime: ENS-Deblurring runs in 2973 ms (3.4x faster), ENS-Deraining in 5816 ms (1.74x faster), and ENS-Denoising in 8666 ms (1.17x faster), while maintaining competitive restoration quality.
Unlocking the Edge deployment and ondevice acceleration of multi-LoRA enabled one-for-all foundational LLM
Apr 20, 2026Deploying large language models (LLMs) on smartphones poses significant engineering challenges due to stringent constraints on memory, latency, and runtime flexibility. In this work, we present a hardware-aware framework for efficient on-device inference of a LLaMA-based multilingual foundation model supporting multiple use cases on Samsung Galaxy S24 and S25 devices with SM8650 and SM8750 Qualcomm chipsets respectively. Our approach integrates application-specific LoRAs as runtime inputs to a single frozen inference graph, enabling dynamic task switching without recompilation or memory overhead. We further introduce a multi-stream decoding mechanism that concurrently generates stylistic variations - such as formal, polite, or jovial responses - within a single forward pass, reducing latency by up to 6x. To accelerate token generation, we apply Dynamic Self-Speculative Decoding (DS2D), a tree-based strategy that predicts future tokens without requiring a draft model, yielding up to 2.3x speedup in decode time. Combined with quantization to INT4 and architecture-level optimizations, our system achieves 4-6x overall improvements in memory and latency while maintaining accuracy across 9 languages and 8 tasks. These results demonstrate practical feasibility of deploying multi-use-case LLMs on edge devices, advancing the commercial viability of Generative AI in mobile platforms.
A Generalized Zero-Shot Quantization of Deep Convolutional Neural Networks via Learned Weights Statistics
Dec 11, 2021
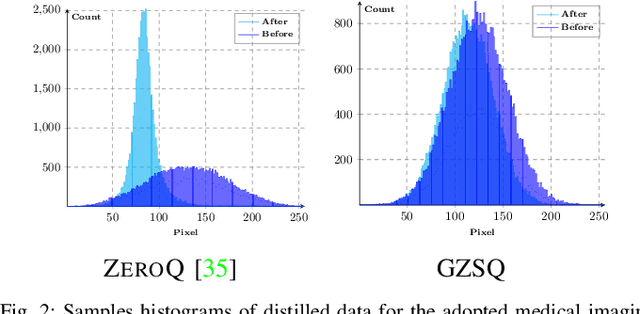
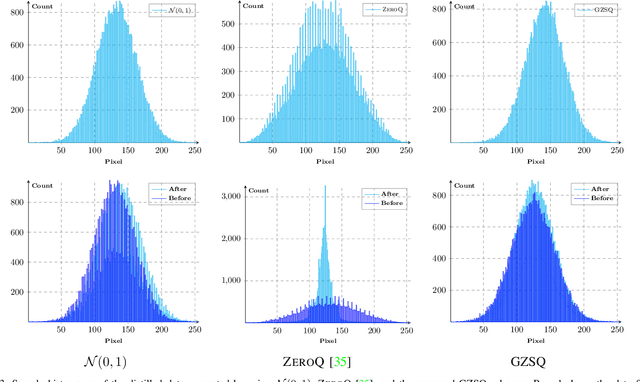
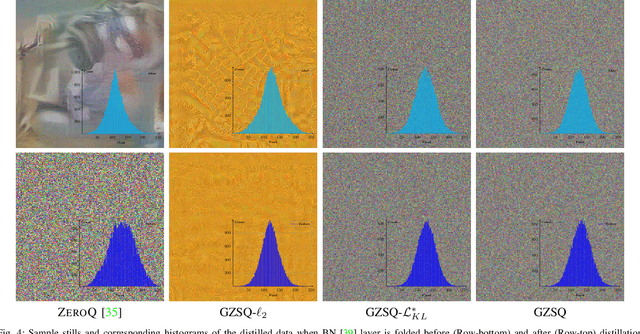
Quantizing the floating-point weights and activations of deep convolutional neural networks to fixed-point representation yields reduced memory footprints and inference time. Recently, efforts have been afoot towards zero-shot quantization that does not require original unlabelled training samples of a given task. These best-published works heavily rely on the learned batch normalization (BN) parameters to infer the range of the activations for quantization. In particular, these methods are built upon either empirical estimation framework or the data distillation approach, for computing the range of the activations. However, the performance of such schemes severely degrades when presented with a network that does not accommodate BN layers. In this line of thought, we propose a generalized zero-shot quantization (GZSQ) framework that neither requires original data nor relies on BN layer statistics. We have utilized the data distillation approach and leveraged only the pre-trained weights of the model to estimate enriched data for range calibration of the activations. To the best of our knowledge, this is the first work that utilizes the distribution of the pretrained weights to assist the process of zero-shot quantization. The proposed scheme has significantly outperformed the existing zero-shot works, e.g., an improvement of ~ 33% in classification accuracy for MobileNetV2 and several other models that are w & w/o BN layers, for a variety of tasks. We have also demonstrated the efficacy of the proposed work across multiple open-source quantization frameworks. Importantly, our work is the first attempt towards the post-training zero-shot quantization of futuristic unnormalized deep neural networks.