 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTGGLines: A Robust Topological Graph Guided Line Segment Detector for Low Quality Binary Images
Feb 27, 2020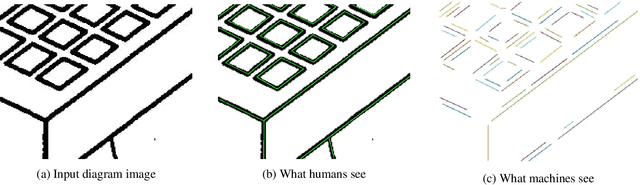
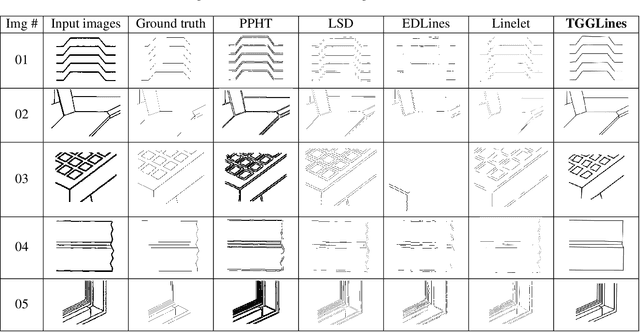

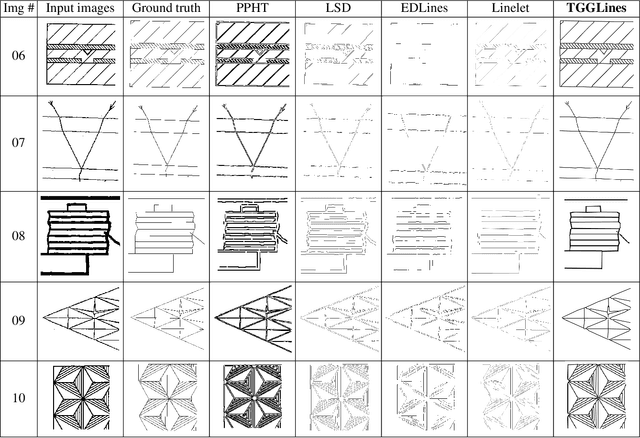
Line segment detection is an essential task in computer vision and image analysis, as it is the critical foundation for advanced tasks such as shape modeling and road lane line detection for autonomous driving. We present a robust topological graph guided approach for line segment detection in low quality binary images (hence, we call it TGGLines). Due to the graph-guided approach, TGGLines not only detects line segments, but also organizes the segments with a line segment connectivity graph, which means the topological relationships (e.g., intersection, an isolated line segment) of the detected line segments are captured and stored; whereas other line detectors only retain a collection of loose line segments. Our empirical results show that the TGGLines detector visually and quantitatively outperforms state-of-the-art line segment detection methods. In addition, our TGGLines approach has the following two competitive advantages: (1) our method only requires one parameter and it is adaptive, whereas almost all other line segment detection methods require multiple (non-adaptive) parameters, and (2) the line segments detected by TGGLines are organized by a line segment connectivity graph.
Skin Cancer Segmentation and Classification with NABLA-N and Inception Recurrent Residual Convolutional Networks
Apr 25, 2019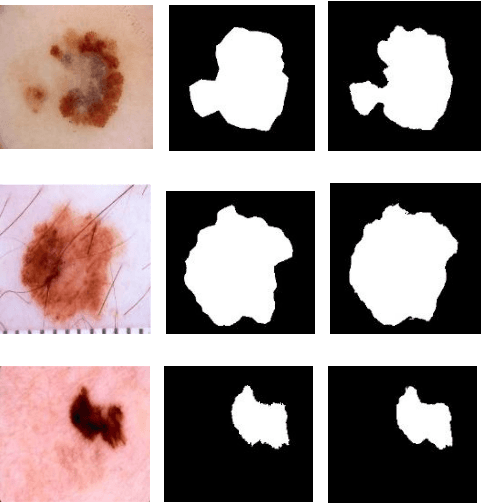
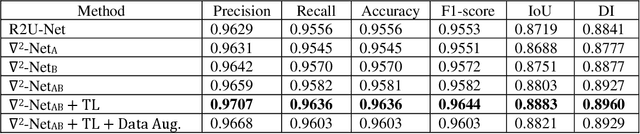
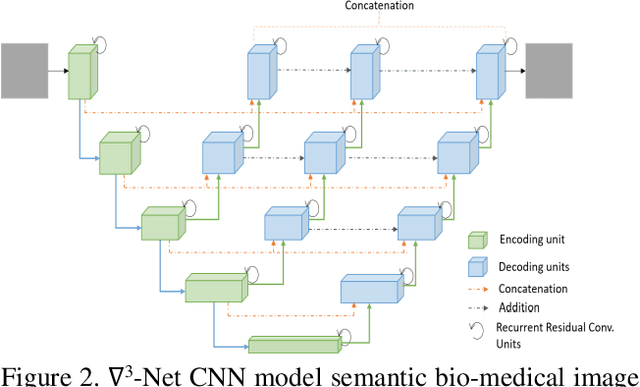
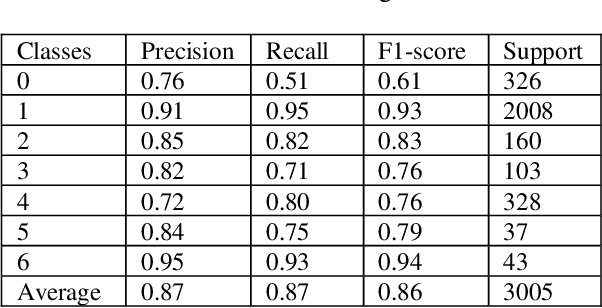
In the last few years, Deep Learning (DL) has been showing superior performance in different modalities of biomedical image analysis. Several DL architectures have been proposed for classification, segmentation, and detection tasks in medical imaging and computational pathology. In this paper, we propose a new DL architecture, the NABLA-N network, with better feature fusion techniques in decoding units for dermoscopic image segmentation tasks. The NABLA-N network has several advances for segmentation tasks. First, this model ensures better feature representation for semantic segmentation with a combination of low to high-level feature maps. Second, this network shows better quantitative and qualitative results with the same or fewer network parameters compared to other methods. In addition, the Inception Recurrent Residual Convolutional Neural Network (IRRCNN) model is used for skin cancer classification. The proposed NABLA-N network and IRRCNN models are evaluated for skin cancer segmentation and classification on the benchmark datasets from the International Skin Imaging Collaboration 2018 (ISIC-2018). The experimental results show superior performance on segmentation tasks compared to the Recurrent Residual U-Net (R2U-Net). The classification model shows around 87% testing accuracy for dermoscopic skin cancer classification on ISIC2018 dataset.
Advanced Deep Convolutional Neural Network Approaches for Digital Pathology Image Analysis: a comprehensive evaluation with different use cases
Apr 19, 2019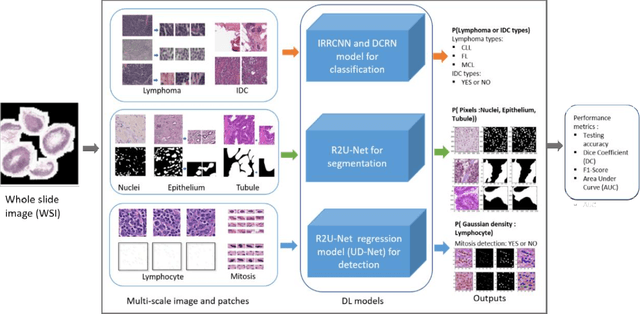

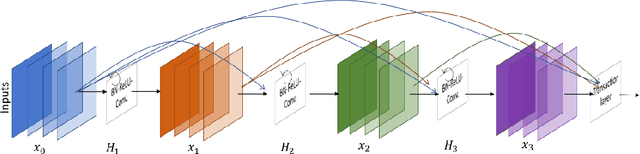

Deep Learning (DL) approaches have been providing state-of-the-art performance in different modalities in the field of medical imagining including Digital Pathology Image Analysis (DPIA). Out of many different DL approaches, Deep Convolutional Neural Network (DCNN) technique provides superior performance for classification, segmentation, and detection tasks. Most of the task in DPIA problems are somehow possible to solve with classification, segmentation, and detection approaches. In addition, sometimes pre and post-processing methods are applied for solving some specific type of problems. Recently, different DCNN models including Inception residual recurrent CNN (IRRCNN), Densely Connected Recurrent Convolution Network (DCRCN), Recurrent Residual U-Net (R2U-Net), and R2U-Net based regression model (UD-Net) have proposed and provide state-of-the-art performance for different computer vision and medical image analysis tasks. However, these advanced DCNN models have not been explored for solving different problems related to DPIA. In this study, we have applied these DCNN techniques for solving different DPIA problems and evaluated on different publicly available benchmark datasets for seven different tasks in digital pathology including lymphoma classification, Invasive Ductal Carcinoma (IDC) detection, nuclei segmentation, epithelium segmentation, tubule segmentation, lymphocyte detection, and mitosis detection. The experimental results are evaluated with different performance metrics such as sensitivity, specificity, accuracy, F1-score, Receiver Operating Characteristics (ROC) curve, dice coefficient (DC), and Means Squired Errors (MSE). The results demonstrate superior performance for classification, segmentation, and detection tasks compared to existing machine learning and DCNN based approaches.
Breast Cancer Classification from Histopathological Images with Inception Recurrent Residual Convolutional Neural Network
Nov 10, 2018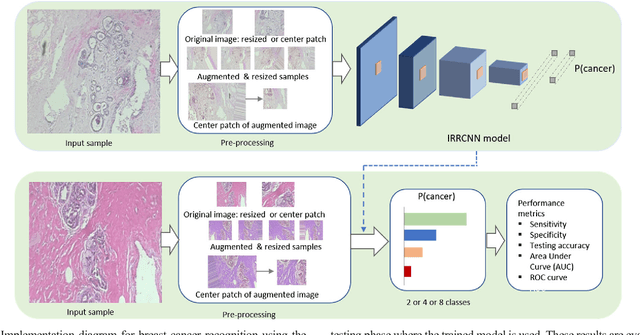
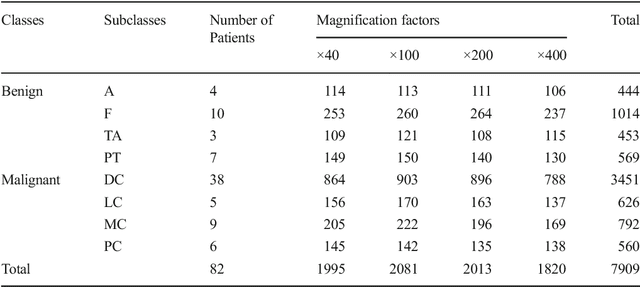
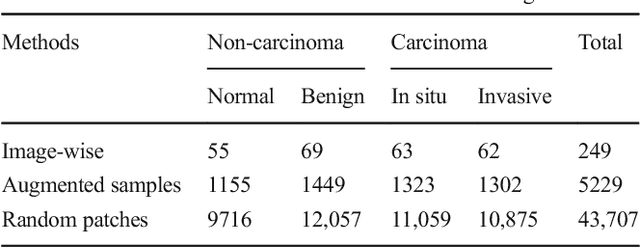
The Deep Convolutional Neural Network (DCNN) is one of the most powerful and successful deep learning approaches. DCNNs have already provided superior performance in different modalities of medical imaging including breast cancer classification, segmentation, and detection. Breast cancer is one of the most common and dangerous cancers impacting women worldwide. In this paper, we have proposed a method for breast cancer classification with the Inception Recurrent Residual Convolutional Neural Network (IRRCNN) model. The IRRCNN is a powerful DCNN model that combines the strength of the Inception Network (Inception-v4), the Residual Network (ResNet), and the Recurrent Convolutional Neural Network (RCNN). The IRRCNN shows superior performance against equivalent Inception Networks, Residual Networks, and RCNNs for object recognition tasks. In this paper, the IRRCNN approach is applied for breast cancer classification on two publicly available datasets including BreakHis and Breast Cancer Classification Challenge 2015. The experimental results are compared against the existing machine learning and deep learning-based approaches with respect to image-based, patch-based, image-level, and patient-level classification. The IRRCNN model provides superior classification performance in terms of sensitivity, Area Under the Curve (AUC), the ROC curve, and global accuracy compared to existing approaches for both datasets.
Microscopic Nuclei Classification, Segmentation and Detection with improved Deep Convolutional Neural Network (DCNN) Approaches
Nov 08, 2018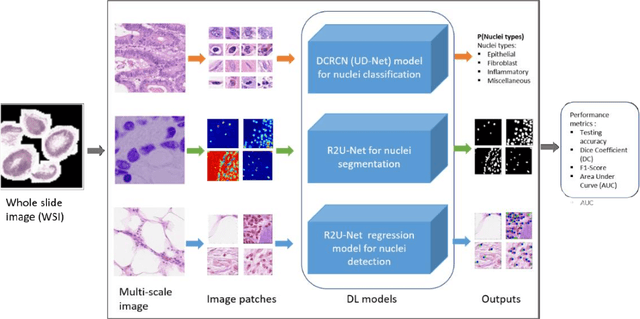
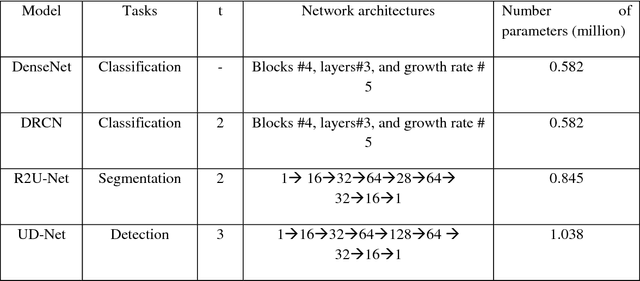
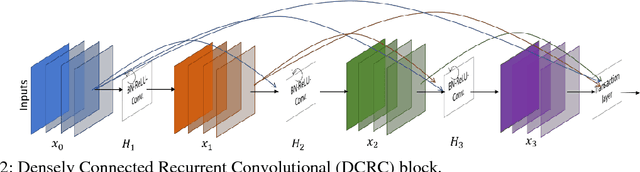
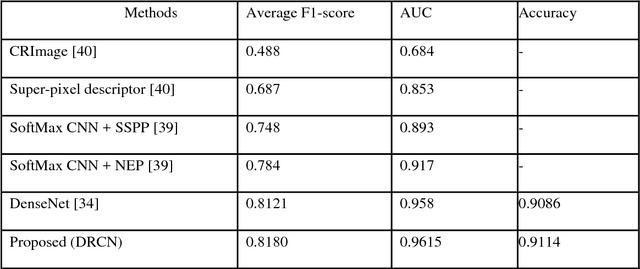
Due to cellular heterogeneity, cell nuclei classification, segmentation, and detection from pathological images are challenging tasks. In the last few years, Deep Convolutional Neural Networks (DCNN) approaches have been shown state-of-the-art (SOTA) performance on histopathological imaging in different studies. In this work, we have proposed different advanced DCNN models and evaluated for nuclei classification, segmentation, and detection. First, the Densely Connected Recurrent Convolutional Network (DCRN) model is used for nuclei classification. Second, Recurrent Residual U-Net (R2U-Net) is applied for nuclei segmentation. Third, the R2U-Net regression model which is named UD-Net is used for nuclei detection from pathological images. The experiments are conducted with different datasets including Routine Colon Cancer(RCC) classification and detection dataset, and Nuclei Segmentation Challenge 2018 dataset. The experimental results show that the proposed DCNN models provide superior performance compared to the existing approaches for nuclei classification, segmentation, and detection tasks. The results are evaluated with different performance metrics including precision, recall, Dice Coefficient (DC), Means Squared Errors (MSE), F1-score, and overall accuracy. We have achieved around 3.4% and 4.5% better F-1 score for nuclei classification and detection tasks compared to recently published DCNN based method. In addition, R2U-Net shows around 92.15% testing accuracy in term of DC. These improved methods will help for pathological practices for better quantitative analysis of nuclei in Whole Slide Images(WSI) which ultimately will help for better understanding of different types of cancer in clinical workflow.
The History Began from AlexNet: A Comprehensive Survey on Deep Learning Approaches
Sep 12, 2018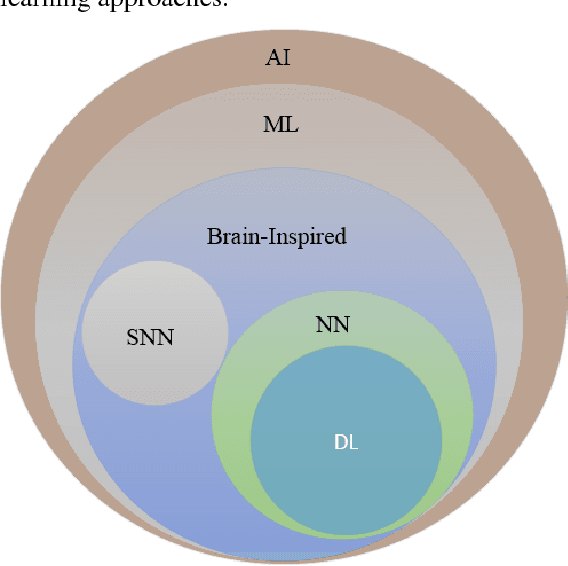
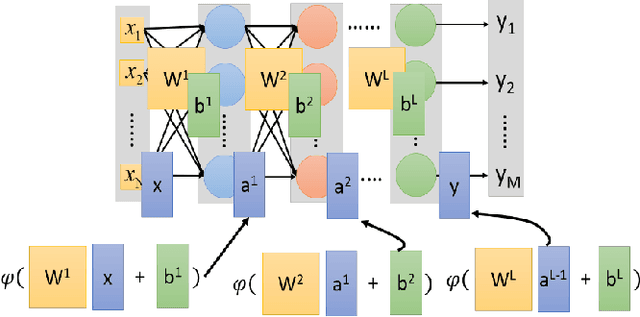
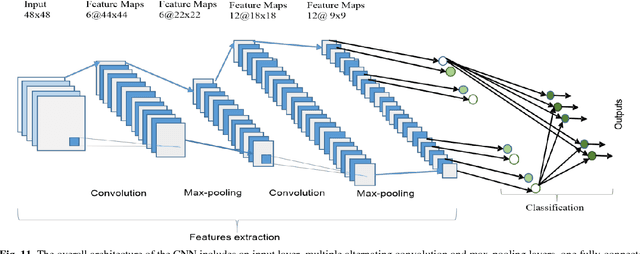
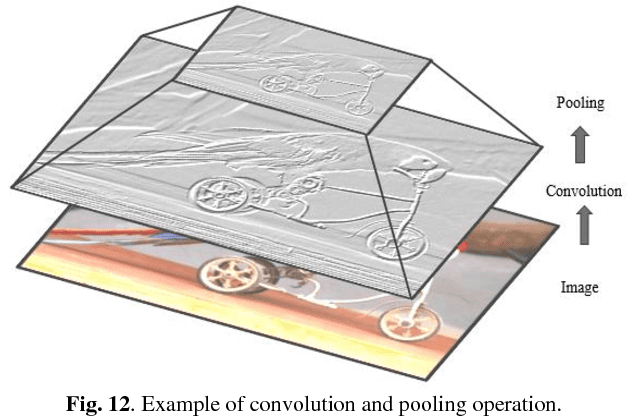
Deep learning has demonstrated tremendous success in variety of application domains in the past few years. This new field of machine learning has been growing rapidly and applied in most of the application domains with some new modalities of applications, which helps to open new opportunity. There are different methods have been proposed on different category of learning approaches, which includes supervised, semi-supervised and un-supervised learning. The experimental results show state-of-the-art performance of deep learning over traditional machine learning approaches in the field of Image Processing, Computer Vision, Speech Recognition, Machine Translation, Art, Medical imaging, Medical information processing, Robotics and control, Bio-informatics, Natural Language Processing (NLP), Cyber security, and many more. This report presents a brief survey on development of DL approaches, including Deep Neural Network (DNN), Convolutional Neural Network (CNN), Recurrent Neural Network (RNN) including Long Short Term Memory (LSTM) and Gated Recurrent Units (GRU), Auto-Encoder (AE), Deep Belief Network (DBN), Generative Adversarial Network (GAN), and Deep Reinforcement Learning (DRL). In addition, we have included recent development of proposed advanced variant DL techniques based on the mentioned DL approaches. Furthermore, DL approaches have explored and evaluated in different application domains are also included in this survey. We have also comprised recently developed frameworks, SDKs, and benchmark datasets that are used for implementing and evaluating deep learning approaches. There are some surveys have published on Deep Learning in Neural Networks [1, 38] and a survey on RL [234]. However, those papers have not discussed the individual advanced techniques for training large scale deep learning models and the recently developed method of generative models [1].
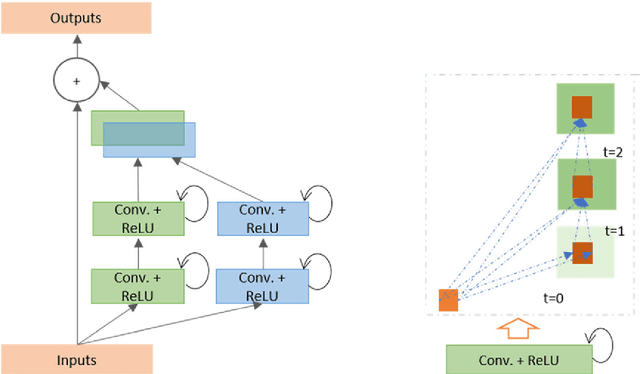
Recurrent Residual Convolutional Neural Network based on U-Net (R2U-Net) for Medical Image Segmentation
May 29, 2018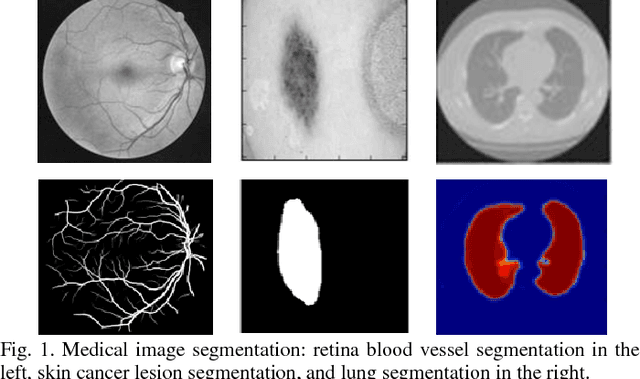
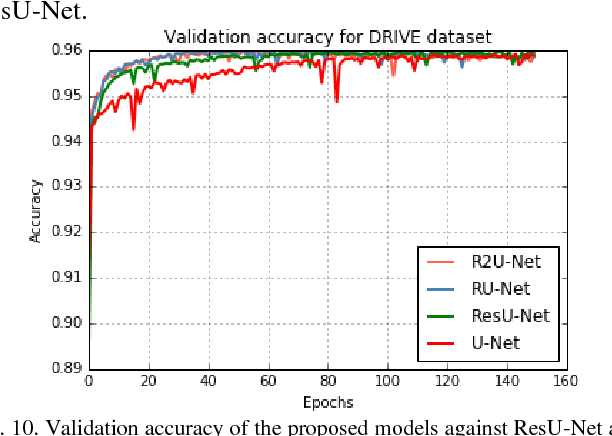
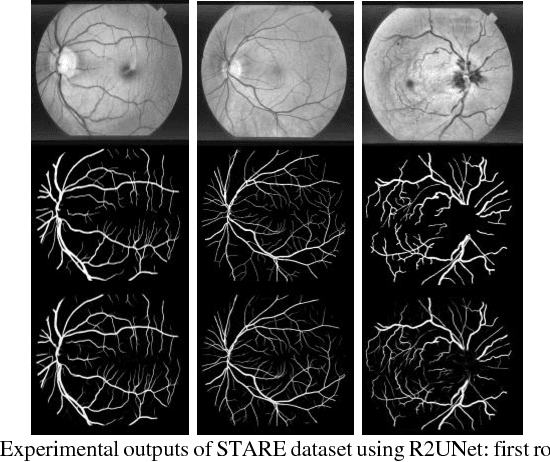
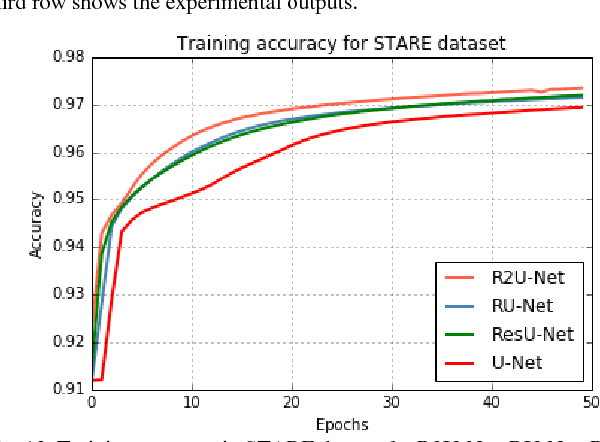
Deep learning (DL) based semantic segmentation methods have been providing state-of-the-art performance in the last few years. More specifically, these techniques have been successfully applied to medical image classification, segmentation, and detection tasks. One deep learning technique, U-Net, has become one of the most popular for these applications. In this paper, we propose a Recurrent Convolutional Neural Network (RCNN) based on U-Net as well as a Recurrent Residual Convolutional Neural Network (RRCNN) based on U-Net models, which are named RU-Net and R2U-Net respectively. The proposed models utilize the power of U-Net, Residual Network, as well as RCNN. There are several advantages of these proposed architectures for segmentation tasks. First, a residual unit helps when training deep architecture. Second, feature accumulation with recurrent residual convolutional layers ensures better feature representation for segmentation tasks. Third, it allows us to design better U-Net architecture with same number of network parameters with better performance for medical image segmentation. The proposed models are tested on three benchmark datasets such as blood vessel segmentation in retina images, skin cancer segmentation, and lung lesion segmentation. The experimental results show superior performance on segmentation tasks compared to equivalent models including U-Net and residual U-Net (ResU-Net).
Handwritten Bangla Character Recognition Using The State-of-Art Deep Convolutional Neural Networks
Feb 10, 2018
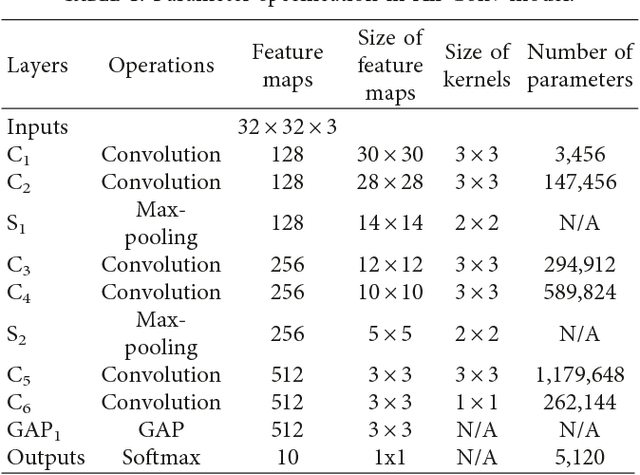
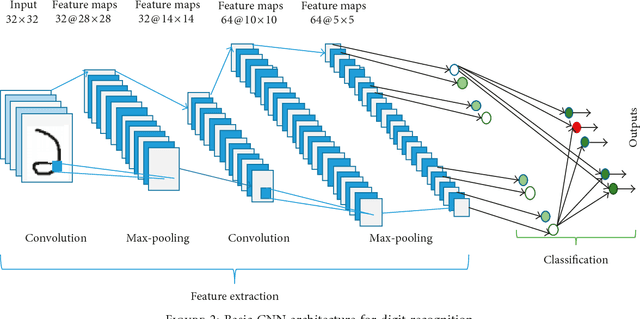
In spite of advances in object recognition technology, Handwritten Bangla Character Recognition (HBCR) remains largely unsolved due to the presence of many ambiguous handwritten characters and excessively cursive Bangla handwritings. Even the best existing recognizers do not lead to satisfactory performance for practical applications related to Bangla character recognition and have much lower performance than those developed for English alpha-numeric characters. To improve the performance of HBCR, we herein present the application of the state-of-the-art Deep Convolutional Neural Networks (DCNN) including VGG Network, All Convolution Network (All-Conv Net), Network in Network (NiN), Residual Network, FractalNet, and DenseNet for HBCR. The deep learning approaches have the advantage of extracting and using feature information, improving the recognition of 2D shapes with a high degree of invariance to translation, scaling and other distortions. We systematically evaluated the performance of DCNN models on publicly available Bangla handwritten character dataset called CMATERdb and achieved the superior recognition accuracy when using DCNN models. This improvement would help in building an automatic HBCR system for practical applications.
Improved Inception-Residual Convolutional Neural Network for Object Recognition
Dec 28, 2017
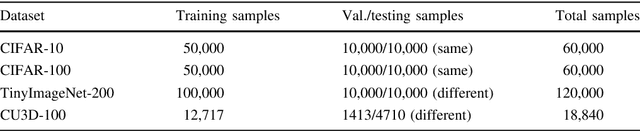
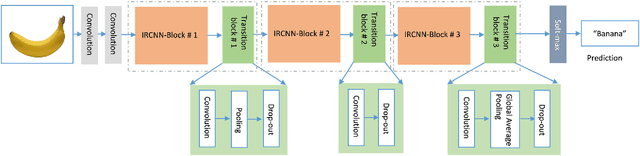
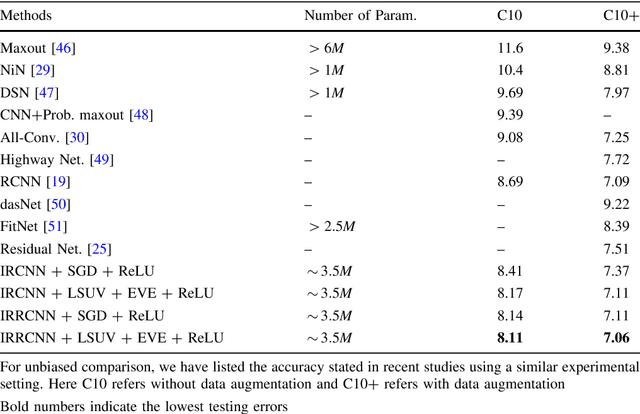
Machine learning and computer vision have driven many of the greatest advances in the modeling of Deep Convolutional Neural Networks (DCNNs). Nowadays, most of the research has been focused on improving recognition accuracy with better DCNN models and learning approaches. The recurrent convolutional approach is not applied very much, other than in a few DCNN architectures. On the other hand, Inception-v4 and Residual networks have promptly become popular among computer the vision community. In this paper, we introduce a new DCNN model called the Inception Recurrent Residual Convolutional Neural Network (IRRCNN), which utilizes the power of the Recurrent Convolutional Neural Network (RCNN), the Inception network, and the Residual network. This approach improves the recognition accuracy of the Inception-residual network with same number of network parameters. In addition, this proposed architecture generalizes the Inception network, the RCNN, and the Residual network with significantly improved training accuracy. We have empirically evaluated the performance of the IRRCNN model on different benchmarks including CIFAR-10, CIFAR-100, TinyImageNet-200, and CU3D-100. The experimental results show higher recognition accuracy against most of the popular DCNN models including the RCNN. We have also investigated the performance of the IRRCNN approach against the Equivalent Inception Network (EIN) and the Equivalent Inception Residual Network (EIRN) counterpart on the CIFAR-100 dataset. We report around 4.53%, 4.49% and 3.56% improvement in classification accuracy compared with the RCNN, EIN, and EIRN on the CIFAR-100 dataset respectively. Furthermore, the experiment has been conducted on the TinyImageNet-200 and CU3D-100 datasets where the IRRCNN provides better testing accuracy compared to the Inception Recurrent CNN (IRCNN), the EIN, and the EIRN.
Handwritten Bangla Digit Recognition Using Deep Learning
May 07, 2017

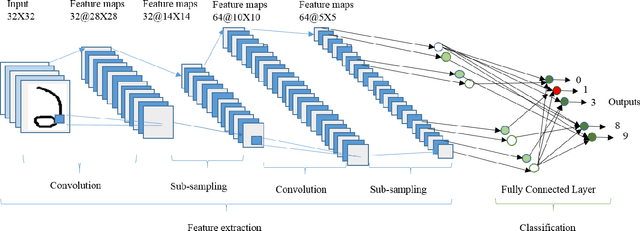

In spite of the advances in pattern recognition technology, Handwritten Bangla Character Recognition (HBCR) (such as alpha-numeric and special characters) remains largely unsolved due to the presence of many perplexing characters and excessive cursive in Bangla handwriting. Even the best existing recognizers do not lead to satisfactory performance for practical applications. To improve the performance of Handwritten Bangla Digit Recognition (HBDR), we herein present a new approach based on deep neural networks which have recently shown excellent performance in many pattern recognition and machine learning applications, but has not been throughly attempted for HBDR. We introduce Bangla digit recognition techniques based on Deep Belief Network (DBN), Convolutional Neural Networks (CNN), CNN with dropout, CNN with dropout and Gaussian filters, and CNN with dropout and Gabor filters. These networks have the advantage of extracting and using feature information, improving the recognition of two dimensional shapes with a high degree of invariance to translation, scaling and other pattern distortions. We systematically evaluated the performance of our method on publicly available Bangla numeral image database named CMATERdb 3.1.1. From experiments, we achieved 98.78% recognition rate using the proposed method: CNN with Gabor features and dropout, which outperforms the state-of-the-art algorithms for HDBR.