 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-SENSE: A Knowledge-Guided Self-Augmented Encoder for Neuro-Semantic Evaluation of Mental Health Conditions on Social Media
Apr 28, 2026Early detection of mental health conditions, particularly stress and depression, from social media text remains a challenging open problem in computational psychiatry and natural language processing. Automated systems must contend with figurative language, implicit emotional expression, and the high noise inherent in user-generated content. Existing approaches either leverage external commonsense knowledge to model mental states explicitly, or apply self-augmentation and contrastive training to improve generalization, but seldom do both in a principled, unified framework. We propose K-SENSE (Knowledge-guided Self-augmented Encoder for Neuro-Semantic Evaluation of Mental Health), a framework that jointly exploits external psychological reasoning and internal representation robustness. K-SENSE adopts a three-stage encoding pipeline: (1) inferential commonsense knowledge is extracted from the COMET model across five mental state dimensions; (2) a semantic anchor is constructed by combining hidden representations from two parallel encoding streams, projected into a shared space before fusion; and (3) a supervised contrastive learning objective aligns same-class representations while encouraging the attention mechanism to suppress irrelevant knowledge noise. We evaluate K-SENSE on Dreaddit (stress detection) and Depression_Mixed (depression detection), achieving mean F1-scores of 86.1 (0.6%) and 94.3 (0.8%), respectively, over five independent runs. These represent improvements of approximately 2.6 and 1.5 percentage points over the strongest prior baselines. Ablation experiments confirm the contribution of each architectural component, including the temporal knowledge integration strategy and the choice to keep the knowledge encoder frozen during fine-tuning.
LLM-based speaker diarization correction: A generalizable approach
Jun 07, 2024



Speaker diarization is necessary for interpreting conversations transcribed using automated speech recognition (ASR) tools. Despite significant developments in diarization methods, diarization accuracy remains an issue. Here, we investigate the use of large language models (LLMs) for diarization correction as a post-processing step. LLMs were fine-tuned using the Fisher corpus, a large dataset of transcribed conversations. The ability of the models to improve diarization accuracy in a holdout dataset was measured. We report that fine-tuned LLMs can markedly improve diarization accuracy. However, model performance is constrained to transcripts produced using the same ASR tool as the transcripts used for fine-tuning, limiting generalizability. To address this constraint, an ensemble model was developed by combining weights from three separate models, each fine-tuned using transcripts from a different ASR tool. The ensemble model demonstrated better overall performance than each of the ASR-specific models, suggesting that a generalizable and ASR-agnostic approach may be achievable. We hope to make these models accessible through public-facing APIs for use by third-party applications.
Can Foundational Large Language Models Assist with Conducting Pharmaceuticals Manufacturing Investigations?
Apr 24, 2024



General purpose Large Language Models (LLM) such as the Generative Pretrained Transformer (GPT) and Large Language Model Meta AI (LLaMA) have attracted much attention in recent years. There is strong evidence that these models can perform remarkably well in various natural language processing tasks. However, how to leverage them to approach domain-specific use cases and drive value remains an open question. In this work, we focus on a specific use case, pharmaceutical manufacturing investigations, and propose that leveraging historical records of manufacturing incidents and deviations in an organization can be beneficial for addressing and closing new cases, or de-risking new manufacturing campaigns. Using a small but diverse dataset of real manufacturing deviations selected from different product lines, we evaluate and quantify the power of three general purpose LLMs (GPT-3.5, GPT-4, and Claude-2) in performing tasks related to the above goal. In particular, (1) the ability of LLMs in automating the process of extracting specific information such as root cause of a case from unstructured data, as well as (2) the possibility of identifying similar or related deviations by performing semantic search on the database of historical records are examined. While our results point to the high accuracy of GPT-4 and Claude-2 in the information extraction task, we discuss cases of complex interplay between the apparent reasoning and hallucination behavior of LLMs as a risk factor. Furthermore, we show that semantic search on vector embedding of deviation descriptions can be used to identify similar records, such as those with a similar type of defect, with a high level of accuracy. We discuss further improvements to enhance the accuracy of similar record identification.
Prediction of clinical tremor severity using Rank Consistent Ordinal Regression
May 03, 2021
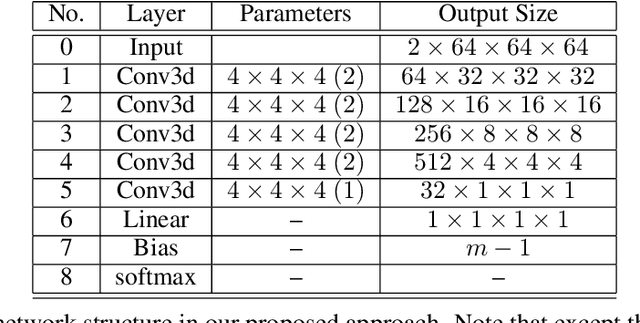
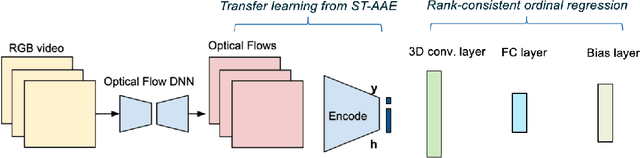

Tremor is a key diagnostic feature of Parkinson's Disease (PD), Essential Tremor (ET), and other central nervous system (CNS) disorders. Clinicians or trained raters assess tremor severity with TETRAS scores by observing patients. Lacking quantitative measures, inter- or intra- observer variabilities are almost inevitable as the distinction between adjacent tremor scores is subtle. Moreover, clinician assessments also require patient visits, which limits the frequency of disease progress evaluation. Therefore it is beneficial to develop an automated assessment that can be performed remotely and repeatably at patients' convenience for continuous monitoring. In this work, we proposed to train a deep neural network (DNN) with rank-consistent ordinal regression using 276 clinical videos from 36 essential tremor patients. The videos are coupled with clinician assessed TETRAS scores, which are used as ground truth labels to train the DNN. To tackle the challenge of limited training data, optical flows are used to eliminate irrelevant background and statistic objects from RGB frames. In addition to optical flows, transfer learning is also applied to leverage pre-trained network weights from a related task of tremor frequency estimate. The approach was evaluated by splitting the clinical videos into training (67%) and testing sets (0.33%). The mean absolute error on TETRAS score of the testing results is 0.45, indicating that most of the errors were from the mismatch of adjacent labels, which is expected and acceptable. The model predications also agree well with clinical ratings. This model is further applied to smart phone videos collected from a PD patient who has an implanted device to turn "On" or "Off" tremor. The model outputs were consistent with the patient tremor states. The results demonstrate that our trained model can be used as a means to assess and track tremor severity.