 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective and General Evaluation for Instruction Conditioned Navigation using Dynamic Time Warping
Jul 11, 2019

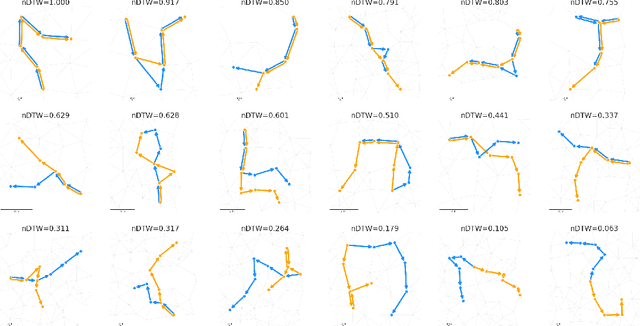

In instruction conditioned navigation, agents interpret natural language and their surroundings to navigate through an environment. Datasets for studying this task typically contain pairs of these instructions and reference trajectories. Yet, most evaluation metrics used thus far fail to properly account for the latter, relying instead on insufficient similarity comparisons. We address fundamental flaws in previously used metrics and show how Dynamic Time Warping (DTW), a long known method of measuring similarity between two time series, can be used for evaluation of navigation agents. For such, we define the normalized Dynamic Time Warping (nDTW) metric, that softly penalizes deviations from the reference path, is naturally sensitive to the order of the nodes composing each path, is suited for both continuous and graph-based evaluations, and can be efficiently calculated. Further, we define SDTW, which constrains nDTW to only successful paths. We collect human similarity judgments for simulated paths and find nDTW correlates better with human rankings than all other metrics. We also demonstrate that using nDTW as a reward signal for Reinforcement Learning navigation agents improves their performance on both the Room-to-Room (R2R) and Room-for-Room (R4R) datasets. The R4R results in particular highlight the superiority of SDTW over previous success-constrained metrics.
Stay on the Path: Instruction Fidelity in Vision-and-Language Navigation
Jun 04, 2019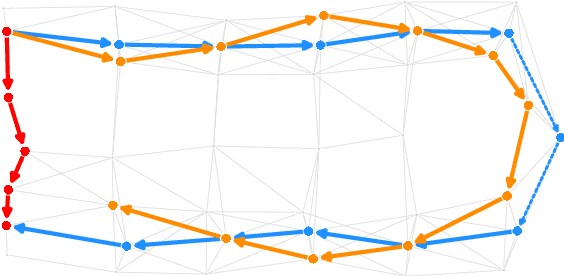
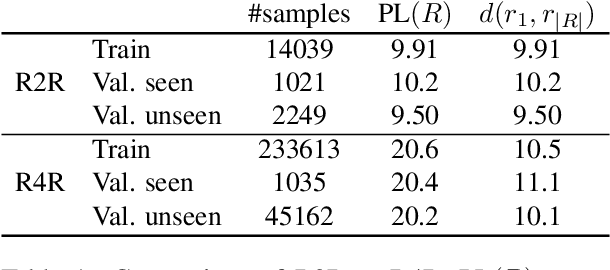


Advances in learning and representations have reinvigorated work that connects language to other modalities. A particularly exciting direction is Vision-and-Language Navigation(VLN), in which agents interpret natural language instructions and visual scenes to move through environments and reach goals. Despite recent progress, current research leaves unclear how much of a role language understanding plays in this task, especially because dominant evaluation metrics have focused on goal completion rather than the sequence of actions corresponding to the instructions. Here, we highlight shortcomings of current metrics for the Room-to-Room dataset (Anderson et al.,2018b) and propose a new metric, Coverage weighted by Length Score (CLS). We also show that the existing paths in the dataset are not ideal for evaluating instruction following because they are direct-to-goal shortest paths. We join existing short paths to form more challenging extended paths to create a new data set, Room-for-Room (R4R). Using R4R and CLS, we show that agents that receive rewards for instruction fidelity outperform agents that focus on goal completion.
Reinforcement Learning for Slate-based Recommender Systems: A Tractable Decomposition and Practical Methodology
May 31, 2019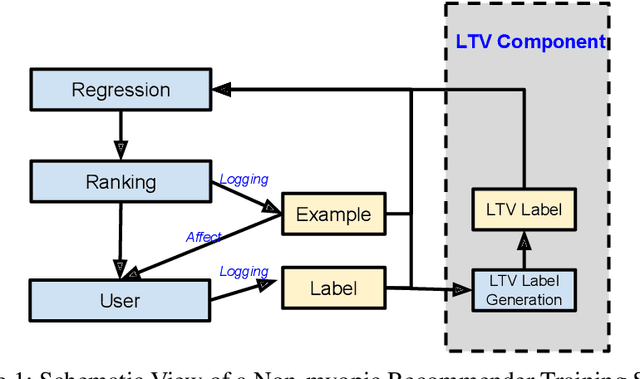
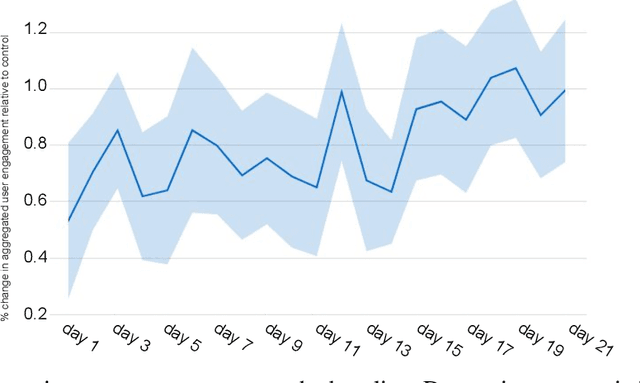
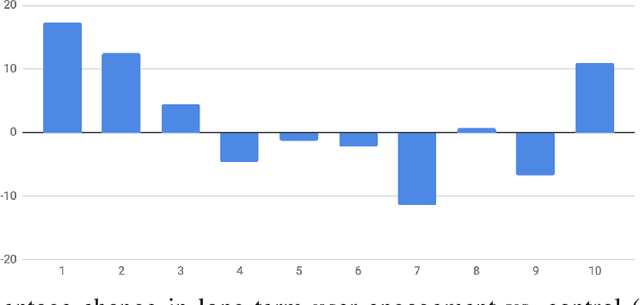
Most practical recommender systems focus on estimating immediate user engagement without considering the long-term effects of recommendations on user behavior. Reinforcement learning (RL) methods offer the potential to optimize recommendations for long-term user engagement. However, since users are often presented with slates of multiple items - which may have interacting effects on user choice - methods are required to deal with the combinatorics of the RL action space. In this work, we address the challenge of making slate-based recommendations to optimize long-term value using RL. Our contributions are three-fold. (i) We develop SLATEQ, a decomposition of value-based temporal-difference and Q-learning that renders RL tractable with slates. Under mild assumptions on user choice behavior, we show that the long-term value (LTV) of a slate can be decomposed into a tractable function of its component item-wise LTVs. (ii) We outline a methodology that leverages existing myopic learning-based recommenders to quickly develop a recommender that handles LTV. (iii) We demonstrate our methods in simulation, and validate the scalability of decomposed TD-learning using SLATEQ in live experiments on YouTube.
Multi-modal Discriminative Model for Vision-and-Language Navigation
May 31, 2019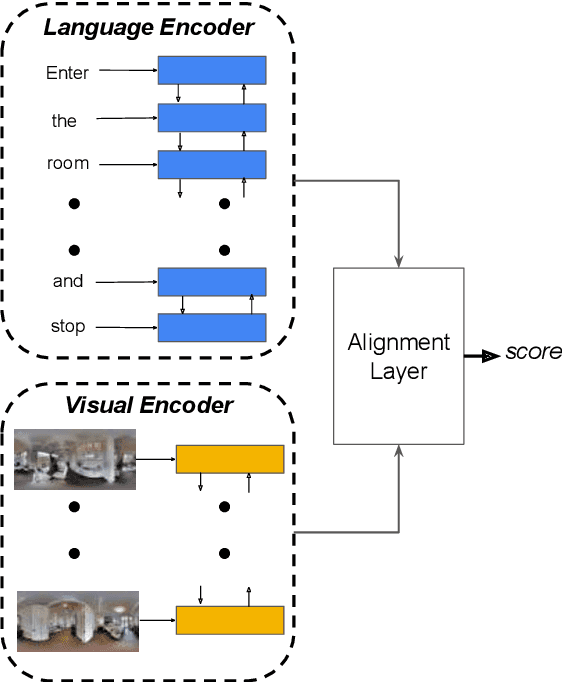
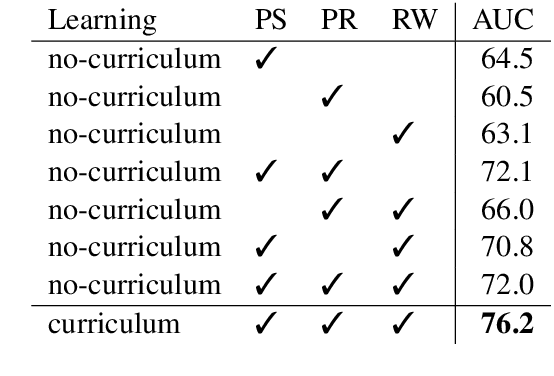
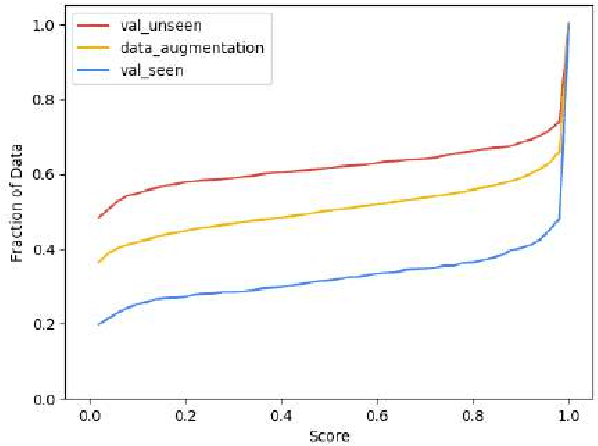
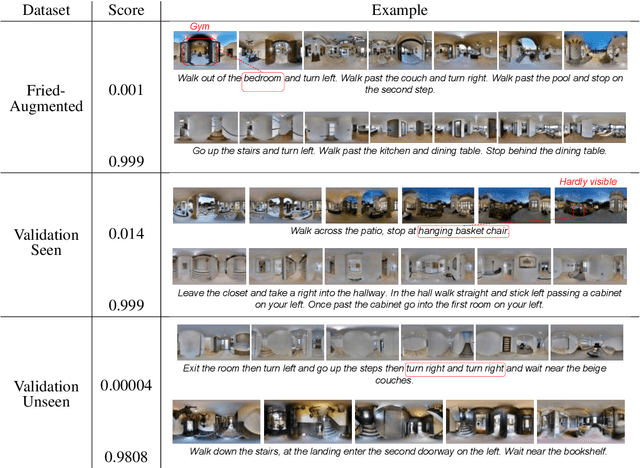
Vision-and-Language Navigation (VLN) is a natural language grounding task where agents have to interpret natural language instructions in the context of visual scenes in a dynamic environment to achieve prescribed navigation goals. Successful agents must have the ability to parse natural language of varying linguistic styles, ground them in potentially unfamiliar scenes, plan and react with ambiguous environmental feedback. Generalization ability is limited by the amount of human annotated data. In particular, \emph{paired} vision-language sequence data is expensive to collect. We develop a discriminator that evaluates how well an instruction explains a given path in VLN task using multi-modal alignment. Our study reveals that only a small fraction of the high-quality augmented data from \citet{Fried:2018:Speaker}, as scored by our discriminator, is useful for training VLN agents with similar performance on previously unseen environments. We also show that a VLN agent warm-started with pre-trained components from the discriminator outperforms the benchmark success rates of 35.5 by 10\% relative measure on previously unseen environments.
Wide & Deep Learning for Recommender Systems
Jun 24, 2016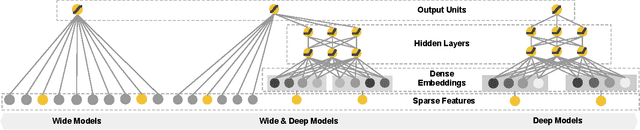
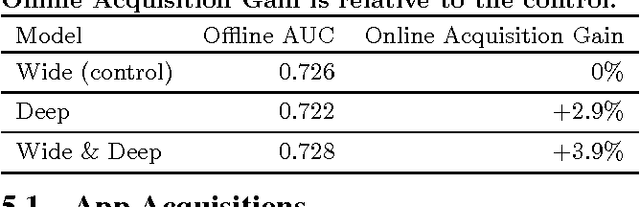
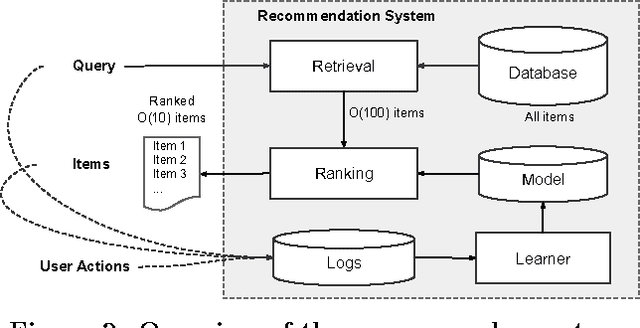

Generalized linear models with nonlinear feature transformations are widely used for large-scale regression and classification problems with sparse inputs. Memorization of feature interactions through a wide set of cross-product feature transformations are effective and interpretable, while generalization requires more feature engineering effort. With less feature engineering, deep neural networks can generalize better to unseen feature combinations through low-dimensional dense embeddings learned for the sparse features. However, deep neural networks with embeddings can over-generalize and recommend less relevant items when the user-item interactions are sparse and high-rank. In this paper, we present Wide & Deep learning---jointly trained wide linear models and deep neural networks---to combine the benefits of memorization and generalization for recommender systems. We productionized and evaluated the system on Google Play, a commercial mobile app store with over one billion active users and over one million apps. Online experiment results show that Wide & Deep significantly increased app acquisitions compared with wide-only and deep-only models. We have also open-sourced our implementation in TensorFlow.