 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Closed-Form Learned Pooling for Deep Classification Networks
Jun 10, 2019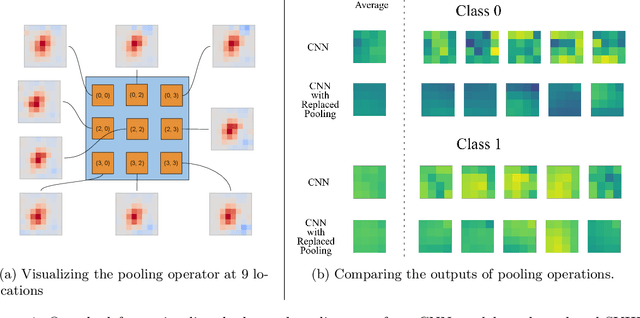
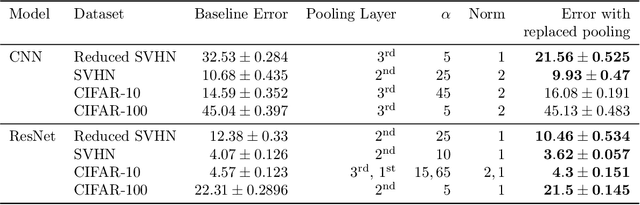
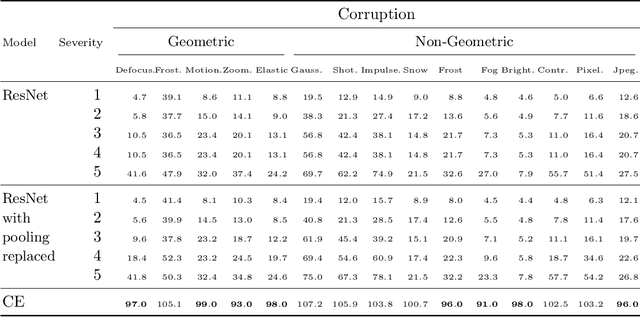
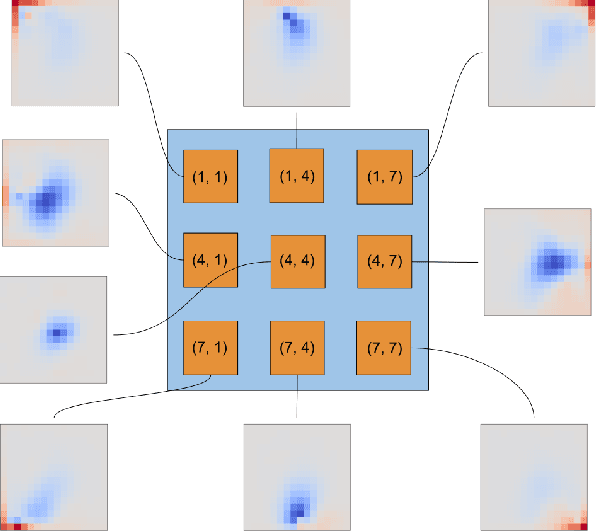
In modern computer vision tasks, convolutional neural networks (CNNs) are indispensable for image classification tasks due to their efficiency and effectiveness. Part of their superiority compared to other architectures, comes from the fact that a single, local filter is shared across the entire image. However, there are scenarios where we may need to treat spatial locations in non-uniform manner. We see this in nature when considering how humans have evolved foveation to process different areas in their field of vision with varying levels of detail. In this paper we propose a way to enable CNNs to learn different pooling weights for each pixel location. We do so by introducing an extended definition of a pooling operator. This operator can learn a strict super-set of what can be learned by average pooling or convolutions. It has the benefit of being shared across feature maps and can be encouraged to be local or diffuse depending on the data. We show that for fixed network weights, our pooling operator can be computed in closed-form by spectral decomposition of matrices associated with class separability. Through experiments, we show that this operator benefits generalization for ResNets and CNNs on the CIFAR-10, CIFAR-100 and SVHN datasets and improves robustness to geometric corruptions and perturbations on the CIFAR-10-C and CIFAR-10-P test sets.
Straight to the point: reinforcement learning for user guidance in ultrasound
Mar 02, 2019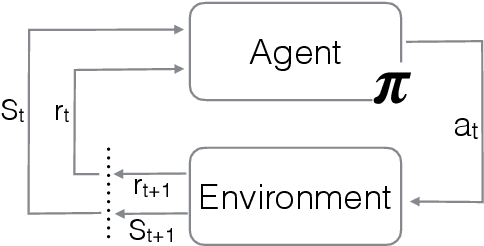
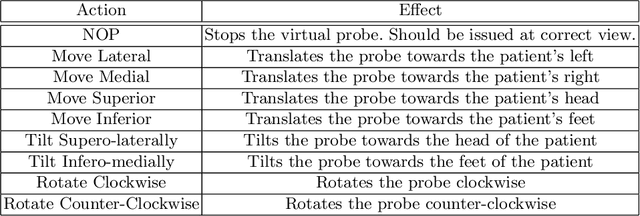
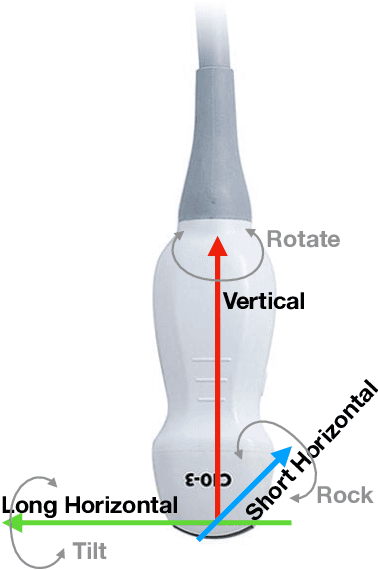
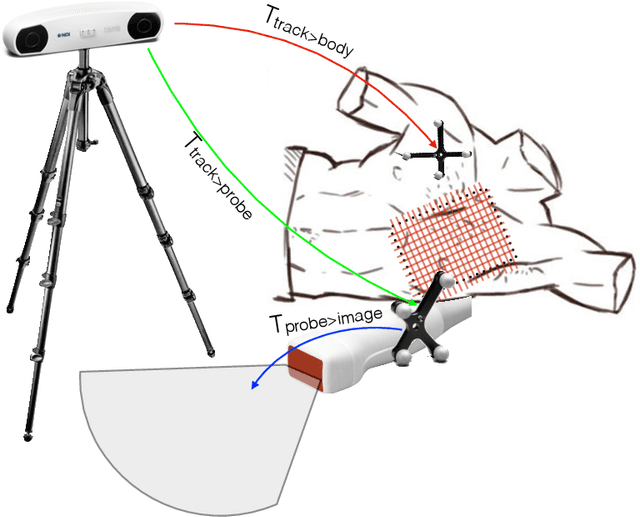
Point of care ultrasound (POCUS) consists in the use of ultrasound imaging in critical or emergency situations to support clinical decisions by healthcare professionals and first responders. In this setting it is essential to be able to provide means to obtain diagnostic data to potentially inexperienced users who did not receive an extensive medical training. Interpretation and acquisition of ultrasound images is not trivial. First, the user needs to find a suitable sound window which can be used to get a clear image, and then he needs to correctly interpret it to perform a diagnosis. Although many recent approaches focus on developing smart ultrasound devices that add interpretation capabilities to existing systems, our goal in this paper is to present a reinforcement learning (RL) strategy which is capable to guide novice users to the correct sonic window and enable them to obtain clinically relevant pictures of the anatomy of interest. We apply our approach to cardiac images acquired from the parasternal long axis (PLAx) view of the left ventricle of the heart.
Semantic Redundancies in Image-Classification Datasets: The 10% You Don't Need
Jan 29, 2019
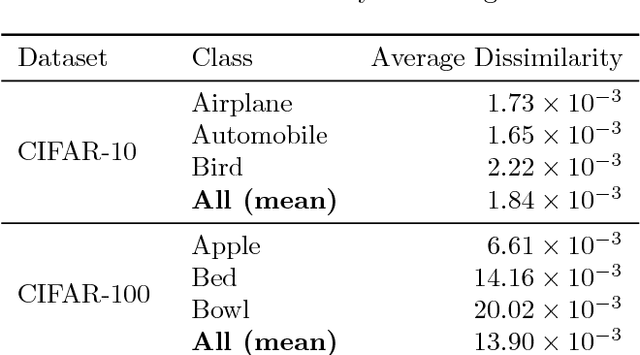
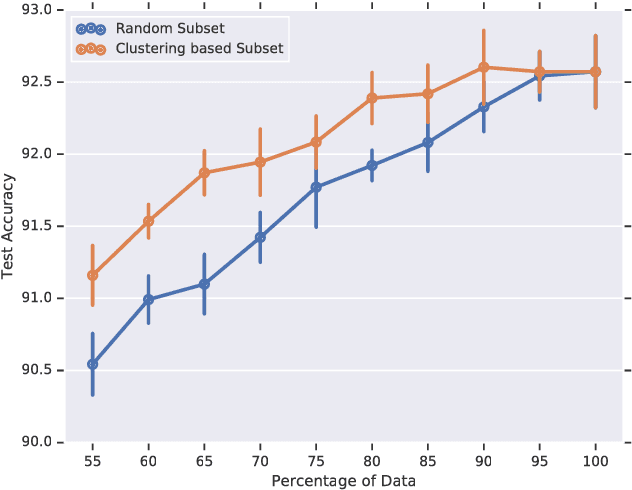

Large datasets have been crucial to the success of deep learning models in the recent years, which keep performing better as they are trained with more labelled data. While there have been sustained efforts to make these models more data-efficient, the potential benefit of understanding the data itself, is largely untapped. Specifically, focusing on object recognition tasks, we wonder if for common benchmark datasets we can do better than random subsets of the data and find a subset that can generalize on par with the full dataset when trained on. To our knowledge, this is the first result that can find notable redundancies in CIFAR-10 and ImageNet datasets (at least 10%). Interestingly, we observe semantic correlations between required and redundant images. We hope that our findings can motivate further research into identifying additional redundancies and exploiting them for more efficient training or data-collection.
Unsupervised Learning of Disentangled Representations from Video
May 31, 2017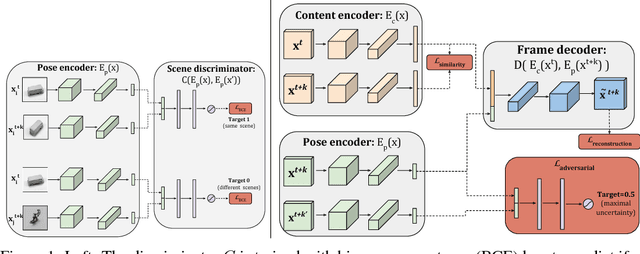
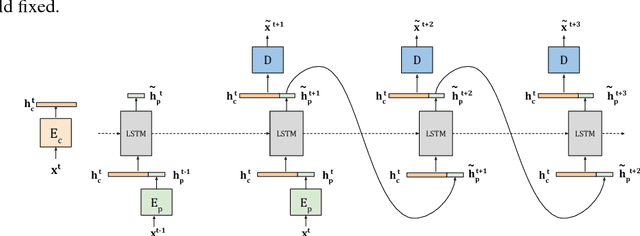
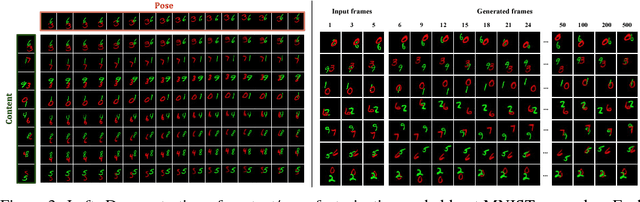

We present a new model DrNET that learns disentangled image representations from video. Our approach leverages the temporal coherence of video and a novel adversarial loss to learn a representation that factorizes each frame into a stationary part and a temporally varying component. The disentangled representation can be used for a range of tasks. For example, applying a standard LSTM to the time-vary components enables prediction of future frames. We evaluate our approach on a range of synthetic and real videos, demonstrating the ability to coherently generate hundreds of steps into the future.
A convolutional approach to reflection symmetry
Sep 17, 2016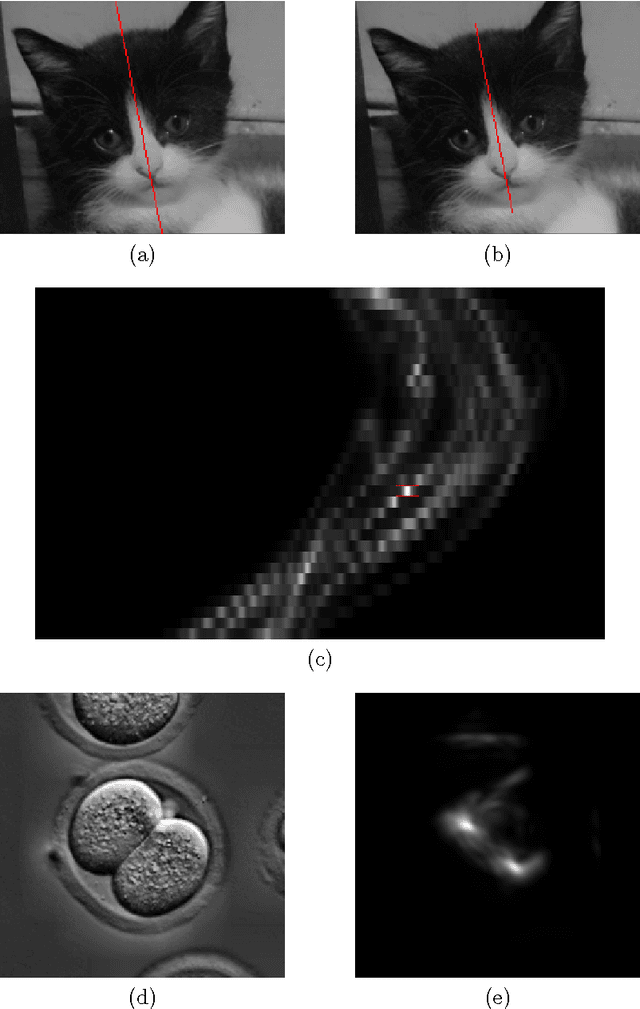
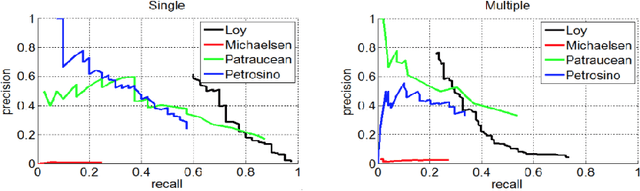
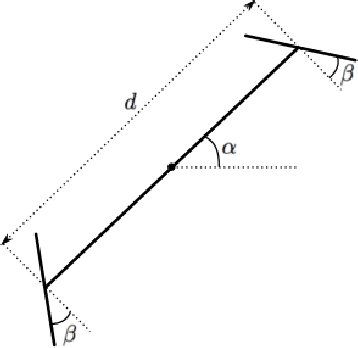

We present a convolutional approach to reflection symmetry detection in 2D. Our model, built on the products of complex-valued wavelet convolutions, simplifies previous edge-based pairwise methods. Being parameter-centered, as opposed to feature-centered, it has certain computational advantages when the object sizes are known a priori, as demonstrated in an ellipse detection application. The method outperforms the best-performing algorithm on the CVPR 2013 Symmetry Detection Competition Database in the single-symmetry case. Code and a new database for 2D symmetry detection is available.