 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom nuclear safety to LLM security: Applying non-probabilistic risk management strategies to build safe and secure LLM-powered systems
May 20, 2025Large language models (LLMs) offer unprecedented and growing capabilities, but also introduce complex safety and security challenges that resist conventional risk management. While conventional probabilistic risk analysis (PRA) requires exhaustive risk enumeration and quantification, the novelty and complexity of these systems make PRA impractical, particularly against adaptive adversaries. Previous research found that risk management in various fields of engineering such as nuclear or civil engineering is often solved by generic (i.e. field-agnostic) strategies such as event tree analysis or robust designs. Here we show how emerging risks in LLM-powered systems could be met with 100+ of these non-probabilistic strategies to risk management, including risks from adaptive adversaries. The strategies are divided into five categories and are mapped to LLM security (and AI safety more broadly). We also present an LLM-powered workflow for applying these strategies and other workflows suitable for solution architects. Overall, these strategies could contribute (despite some limitations) to security, safety and other dimensions of responsible AI.
Comparing Reinforcement Learning and Human Learning using the Game of Hidden Rules
Jun 30, 2023



Reliable real-world deployment of reinforcement learning (RL) methods requires a nuanced understanding of their strengths and weaknesses and how they compare to those of humans. Human-machine systems are becoming more prevalent and the design of these systems relies on a task-oriented understanding of both human learning (HL) and RL. Thus, an important line of research is characterizing how the structure of a learning task affects learning performance. While increasingly complex benchmark environments have led to improved RL capabilities, such environments are difficult to use for the dedicated study of task structure. To address this challenge we present a learning environment built to support rigorous study of the impact of task structure on HL and RL. We demonstrate the environment's utility for such study through example experiments in task structure that show performance differences between humans and RL algorithms.
Can We Distinguish Machine Learning from Human Learning?
Oct 08, 2019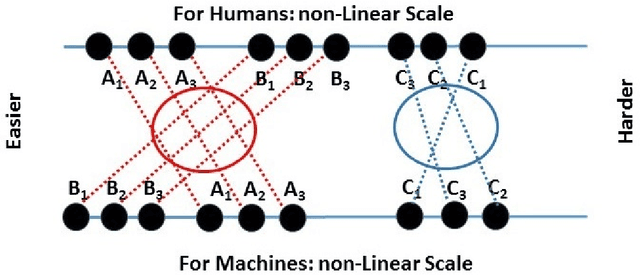
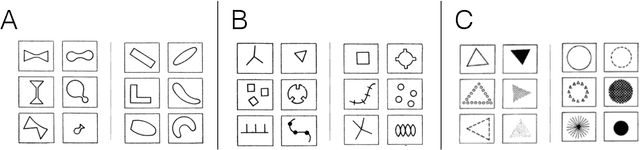


What makes a task relatively more or less difficult for a machine compared to a human? Much AI/ML research has focused on expanding the range of tasks that machines can do, with a focus on whether machines can beat humans. Allowing for differences in scale, we can seek interesting (anomalous) pairs of tasks T, T'. We define interesting in this way: The "harder to learn" relation is reversed when comparing human intelligence (HI) to AI. While humans seems to be able to understand problems by formulating rules, ML using neural networks does not rely on constructing rules. We discuss a novel approach where the challenge is to "perform well under rules that have been created by human beings." We suggest that this provides a rigorous and precise pathway for understanding the difference between the two kinds of learning. Specifically, we suggest a large and extensible class of learning tasks, formulated as learning under rules. With these tasks, both the AI and HI will be studied with rigor and precision. The immediate goal is to find interesting groundtruth rule pairs. In the long term, the goal will be to understand, in a generalizable way, what distinguishes interesting pairs from ordinary pairs, and to define saliency behind interesting pairs. This may open new ways of thinking about AI, and provide unexpected insights into human learning.