 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolutionarily-Curated Curriculum Learning for Deep Reinforcement Learning Agents
Jan 16, 2019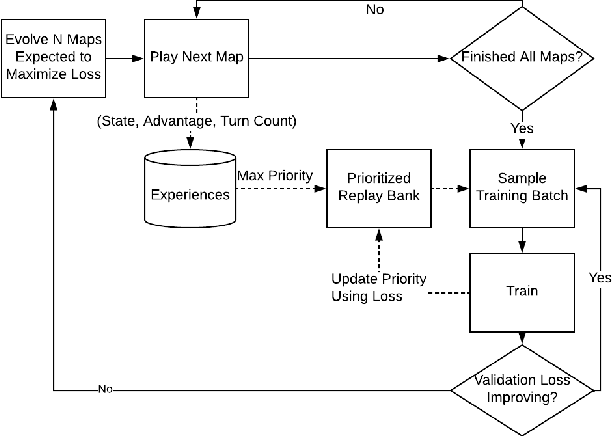

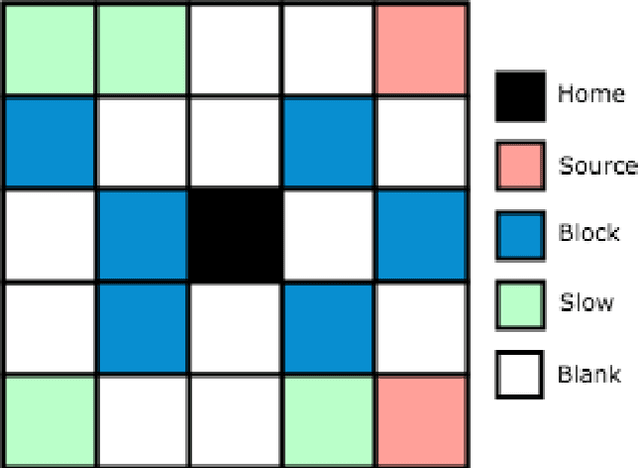

In this paper we propose a new training loop for deep reinforcement learning agents with an evolutionary generator. Evolutionary procedural content generation has been used in the creation of maps and levels for games before. Our system incorporates an evolutionary map generator to construct a training curriculum that is evolved to maximize loss within the state-of-the-art Double Dueling Deep Q Network architecture with prioritized replay. We present a case-study in which we prove the efficacy of our new method on a game with a discrete, large action space we made called Attackers and Defenders. Our results demonstrate that training on an evolutionarily-curated curriculum (directed sampling) of maps both expedites training and improves generalization when compared to a network trained on an undirected sampling of maps.
Prevalence and recoverability of syntactic parameters in sparse distributed memories
Oct 21, 2015
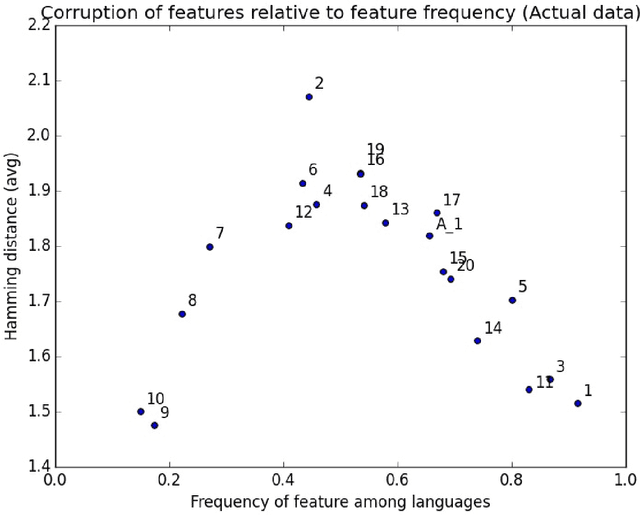
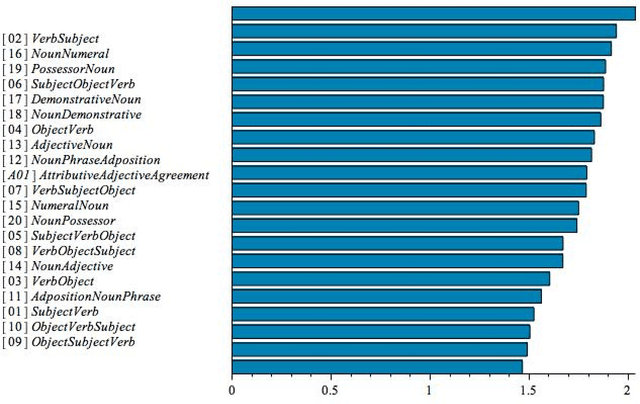
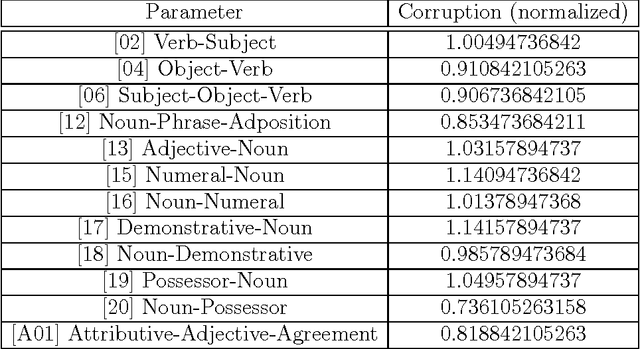
We propose a new method, based on Sparse Distributed Memory (Kanerva Networks), for studying dependency relations between different syntactic parameters in the Principles and Parameters model of Syntax. We store data of syntactic parameters of world languages in a Kanerva Network and we check the recoverability of corrupted parameter data from the network. We find that different syntactic parameters have different degrees of recoverability. We identify two different effects: an overall underlying relation between the prevalence of parameters across languages and their degree of recoverability, and a finer effect that makes some parameters more easily recoverable beyond what their prevalence would indicate. We interpret a higher recoverability for a syntactic parameter as an indication of the existence of a dependency relation, through which the given parameter can be determined using the remaining uncorrupted data.