 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-RM at SemEval-2023 Task 2: Multilingual Complex NER using XLM-RoBERTa
May 05, 2023Named Entity Recognition(NER) is a task of recognizing entities at a token level in a sentence. This paper focuses on solving NER tasks in a multilingual setting for complex named entities. Our team, LLM-RM participated in the recently organized SemEval 2023 task, Task 2: MultiCoNER II,Multilingual Complex Named Entity Recognition. We approach the problem by leveraging cross-lingual representation provided by fine-tuning XLM-Roberta base model on datasets of all of the 12 languages provided -- Bangla, Chinese, English, Farsi, French, German, Hindi, Italian, Portuguese, Spanish, Swedish and Ukrainian
Summarizing Indian Languages using Multilingual Transformers based Models
Mar 29, 2023



With the advent of multilingual models like mBART, mT5, IndicBART etc., summarization in low resource Indian languages is getting a lot of attention now a days. But still the number of datasets is low in number. In this work, we (Team HakunaMatata) study how these multilingual models perform on the datasets which have Indian languages as source and target text while performing summarization. We experimented with IndicBART and mT5 models to perform the experiments and report the ROUGE-1, ROUGE-2, ROUGE-3 and ROUGE-4 scores as a performance metric.
XWikiGen: Cross-lingual Summarization for Encyclopedic Text Generation in Low Resource Languages
Mar 22, 2023



Lack of encyclopedic text contributors, especially on Wikipedia, makes automated text generation for \emph{low resource (LR) languages} a critical problem. Existing work on Wikipedia text generation has focused on \emph{English only} where English reference articles are summarized to generate English Wikipedia pages. But, for low-resource languages, the scarcity of reference articles makes monolingual summarization ineffective in solving this problem. Hence, in this work, we propose \task{}, which is the task of cross-lingual multi-document summarization of text from multiple reference articles, written in various languages, to generate Wikipedia-style text. Accordingly, we contribute a benchmark dataset, \data{}, spanning $\sim$69K Wikipedia articles covering five domains and eight languages. We harness this dataset to train a two-stage system where the input is a set of citations and a section title and the output is a section-specific LR summary. The proposed system is based on a novel idea of neural unsupervised extractive summarization to coarsely identify salient information followed by a neural abstractive model to generate the section-specific text. Extensive experiments show that multi-domain training is better than the multi-lingual setup on average.
GrapeQA: GRaph Augmentation and Pruning to Enhance Question-Answering
Mar 22, 2023



Commonsense question-answering (QA) methods combine the power of pre-trained Language Models (LM) with the reasoning provided by Knowledge Graphs (KG). A typical approach collects nodes relevant to the QA pair from a KG to form a Working Graph (WG) followed by reasoning using Graph Neural Networks(GNNs). This faces two major challenges: (i) it is difficult to capture all the information from the QA in the WG, and (ii) the WG contains some irrelevant nodes from the KG. To address these, we propose GrapeQA with two simple improvements on the WG: (i) Prominent Entities for Graph Augmentation identifies relevant text chunks from the QA pair and augments the WG with corresponding latent representations from the LM, and (ii) Context-Aware Node Pruning removes nodes that are less relevant to the QA pair. We evaluate our results on OpenBookQA, CommonsenseQA and MedQA-USMLE and see that GrapeQA shows consistent improvements over its LM + KG predecessor (QA-GNN in particular) and large improvements on OpenBookQA.
Massively Multilingual Language Models for Cross Lingual Fact Extraction from Low Resource Indian Languages
Feb 09, 2023Massive knowledge graphs like Wikidata attempt to capture world knowledge about multiple entities. Recent approaches concentrate on automatically enriching these KGs from text. However a lot of information present in the form of natural text in low resource languages is often missed out. Cross Lingual Information Extraction aims at extracting factual information in the form of English triples from low resource Indian Language text. Despite its massive potential, progress made on this task is lagging when compared to Monolingual Information Extraction. In this paper, we propose the task of Cross Lingual Fact Extraction(CLFE) from text and devise an end-to-end generative approach for the same which achieves an overall F1 score of 77.46.
Investigating Strategies for Clause Recommendation
Jan 21, 2023



Clause recommendation is the problem of recommending a clause to a legal contract, given the context of the contract in question and the clause type to which the clause should belong. With not much prior work being done toward the generation of legal contracts, this problem was proposed as a first step toward the bigger problem of contract generation. As an open-ended text generation problem, the distinguishing characteristics of this problem lie in the nature of legal language as a sublanguage and the considerable similarity of textual content within the clauses of a specific type. This similarity aspect in legal clauses drives us to investigate the importance of similar contracts' representation for recommending clauses. In our work, we experiment with generating clauses for 15 commonly occurring clause types in contracts expanding upon the previous work on this problem and analyzing clause recommendations in varying settings using information derived from similar contracts.
* Published in Legal Knowledge and Information Systems (JURIX) 2022. (10 pages, 4 figures)
Graph-based Keyword Planning for Legal Clause Generation from Topics
Jan 07, 2023



Generating domain-specific content such as legal clauses based on minimal user-provided information can be of significant benefit in automating legal contract generation. In this paper, we propose a controllable graph-based mechanism that can generate legal clauses using only the topic or type of the legal clauses. Our pipeline consists of two stages involving a graph-based planner followed by a clause generator. The planner outlines the content of a legal clause as a sequence of keywords in the order of generic to more specific clause information based on the input topic using a controllable graph-based mechanism. The generation stage takes in a given plan and generates a clause. The pipeline consists of a graph-based planner followed by text generation. We illustrate the effectiveness of our proposed two-stage approach on a broad set of clause topics in contracts.
Towards Proactively Forecasting Sentence-Specific Information Popularity within Online News Documents
Dec 31, 2022



Multiple studies have focused on predicting the prospective popularity of an online document as a whole, without paying attention to the contributions of its individual parts. We introduce the task of proactively forecasting popularities of sentences within online news documents solely utilizing their natural language content. We model sentence-specific popularity forecasting as a sequence regression task. For training our models, we curate InfoPop, the first dataset containing popularity labels for over 1.7 million sentences from over 50,000 online news documents. To the best of our knowledge, this is the first dataset automatically created using streams of incoming search engine queries to generate sentence-level popularity annotations. We propose a novel transfer learning approach involving sentence salience prediction as an auxiliary task. Our proposed technique coupled with a BERT-based neural model exceeds nDCG values of 0.8 for proactive sentence-specific popularity forecasting. Notably, our study presents a non-trivial takeaway: though popularity and salience are different concepts, transfer learning from salience prediction enhances popularity forecasting. We release InfoPop and make our code publicly available: https://github.com/sayarghoshroy/InfoPopularity
* In 33rd ACM Conference on Hypertext and Social Media [HT '22] (Main Track), Link: https://dl.acm.org/doi/10.1145/3511095.3531268
XF2T: Cross-lingual Fact-to-Text Generation for Low-Resource Languages
Sep 22, 2022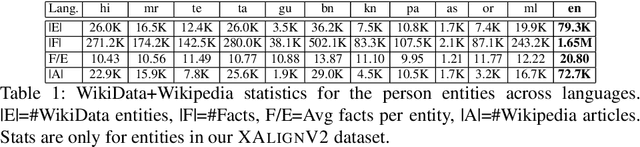
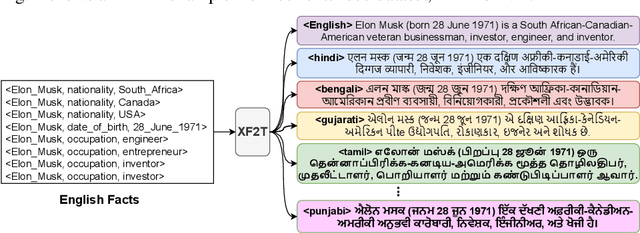
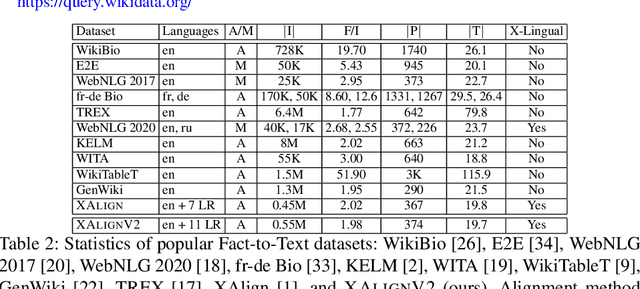
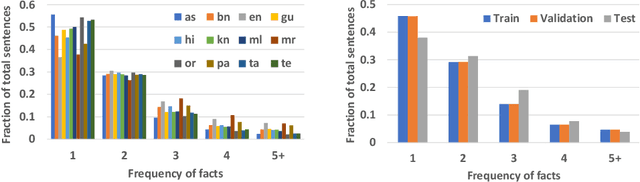
Multiple business scenarios require an automated generation of descriptive human-readable text from structured input data. Hence, fact-to-text generation systems have been developed for various downstream tasks like generating soccer reports, weather and financial reports, medical reports, person biographies, etc. Unfortunately, previous work on fact-to-text (F2T) generation has focused primarily on English mainly due to the high availability of relevant datasets. Only recently, the problem of cross-lingual fact-to-text (XF2T) was proposed for generation across multiple languages alongwith a dataset, XALIGN for eight languages. However, there has been no rigorous work on the actual XF2T generation problem. We extend XALIGN dataset with annotated data for four more languages: Punjabi, Malayalam, Assamese and Oriya. We conduct an extensive study using popular Transformer-based text generation models on our extended multi-lingual dataset, which we call XALIGNV2. Further, we investigate the performance of different text generation strategies: multiple variations of pretraining, fact-aware embeddings and structure-aware input encoding. Our extensive experiments show that a multi-lingual mT5 model which uses fact-aware embeddings with structure-aware input encoding leads to best results on average across the twelve languages. We make our code, dataset and model publicly available, and hope that this will help advance further research in this critical area.
XAlign: Cross-lingual Fact-to-Text Alignment and Generation for Low-Resource Languages
Feb 01, 2022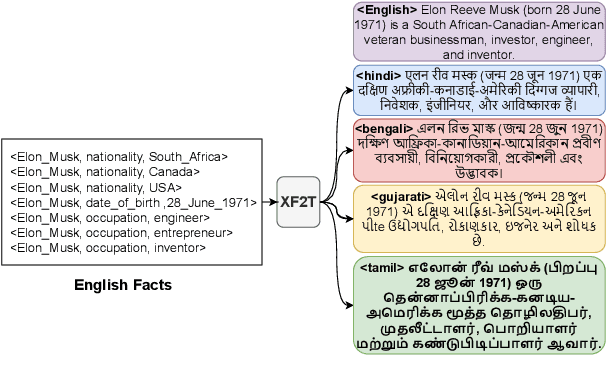
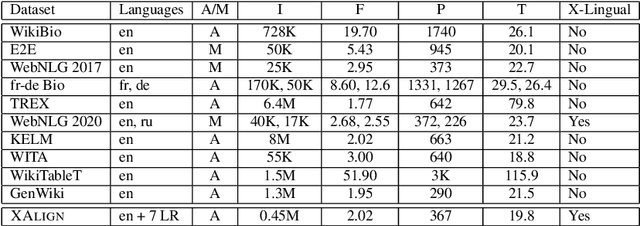
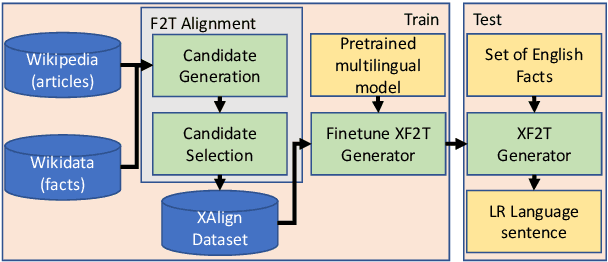
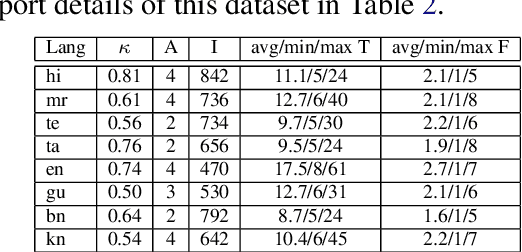
Multiple critical scenarios (like Wikipedia text generation given English Infoboxes) need automated generation of descriptive text in low resource (LR) languages from English fact triples. Previous work has focused on English fact-to-text (F2T) generation. To the best of our knowledge, there has been no previous attempt on cross-lingual alignment or generation for LR languages. Building an effective cross-lingual F2T (XF2T) system requires alignment between English structured facts and LR sentences. We propose two unsupervised methods for cross-lingual alignment. We contribute XALIGN, an XF2T dataset with 0.45M pairs across 8 languages, of which 5402 pairs have been manually annotated. We also train strong baseline XF2T generation models on the XAlign dataset.