 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocQAC: Adaptive Trie-Guided Decoding for Effective In-Document Query Auto-Completion
Apr 20, 2026Query auto-completion (QAC) has been widely studied in the context of web search, yet remains underexplored for in-document search, which we term DocQAC. DocQAC aims to enhance search productivity within long documents by helping users craft faster, more precise queries, even for complex or hard-to-spell terms. While global historical queries are available to both WebQAC and DocQAC, DocQAC uniquely accesses document-specific context, including the current document's content and its specific history of user query interactions. To address this setting, we propose a novel adaptive trie-guided decoding framework that uses user query prefixes to softly steer language models toward high-quality completions. Our approach introduces an adaptive penalty mechanism with tunable hyperparameters, enabling a principled trade-off between model confidence and trie-based guidance. To efficiently incorporate document context, we explore retrieval-augmented generation (RAG) and lightweight contextual document signals such as titles, keyphrases, and summaries. When applied to encoder-decoder models like T5 and BART, our trie-guided framework outperforms strong baselines and even surpasses much larger instruction-tuned models such as LLaMA-3 and Phi-3 on seen queries across both seen and unseen documents. This demonstrates its practicality for real-world DocQAC deployments, where efficiency and scalability are critical. We evaluate our method on a newly introduced DocQAC benchmark derived from ORCAS, enriched with query-document pairs. We make both the DocQAC dataset (https://bit.ly/3IGEkbH) and code (https://github.com/rahcode7/DocQAC) publicly available.
Multilingual Bias Detection and Mitigation for Indian Languages
Dec 23, 2023Lack of diverse perspectives causes neutrality bias in Wikipedia content leading to millions of worldwide readers getting exposed by potentially inaccurate information. Hence, neutrality bias detection and mitigation is a critical problem. Although previous studies have proposed effective solutions for English, no work exists for Indian languages. First, we contribute two large datasets, mWikiBias and mWNC, covering 8 languages, for the bias detection and mitigation tasks respectively. Next, we investigate the effectiveness of popular multilingual Transformer-based models for the two tasks by modeling detection as a binary classification problem and mitigation as a style transfer problem. We make the code and data publicly available.
XF2T: Cross-lingual Fact-to-Text Generation for Low-Resource Languages
Sep 22, 2022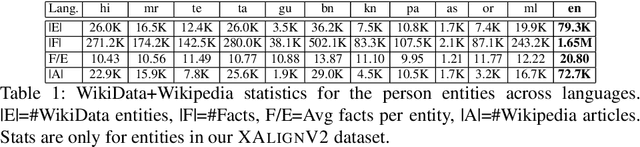
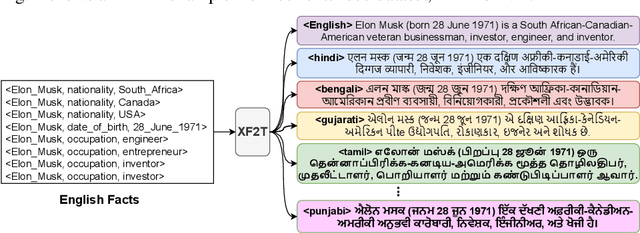
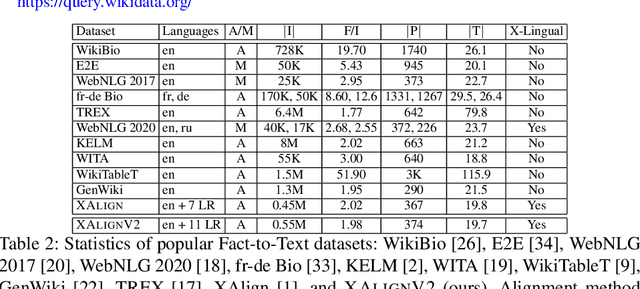
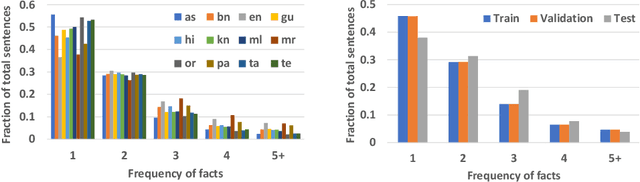
Multiple business scenarios require an automated generation of descriptive human-readable text from structured input data. Hence, fact-to-text generation systems have been developed for various downstream tasks like generating soccer reports, weather and financial reports, medical reports, person biographies, etc. Unfortunately, previous work on fact-to-text (F2T) generation has focused primarily on English mainly due to the high availability of relevant datasets. Only recently, the problem of cross-lingual fact-to-text (XF2T) was proposed for generation across multiple languages alongwith a dataset, XALIGN for eight languages. However, there has been no rigorous work on the actual XF2T generation problem. We extend XALIGN dataset with annotated data for four more languages: Punjabi, Malayalam, Assamese and Oriya. We conduct an extensive study using popular Transformer-based text generation models on our extended multi-lingual dataset, which we call XALIGNV2. Further, we investigate the performance of different text generation strategies: multiple variations of pretraining, fact-aware embeddings and structure-aware input encoding. Our extensive experiments show that a multi-lingual mT5 model which uses fact-aware embeddings with structure-aware input encoding leads to best results on average across the twelve languages. We make our code, dataset and model publicly available, and hope that this will help advance further research in this critical area.
XAlign: Cross-lingual Fact-to-Text Alignment and Generation for Low-Resource Languages
Feb 01, 2022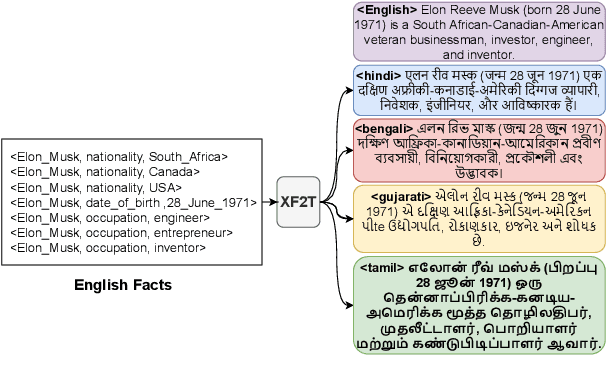
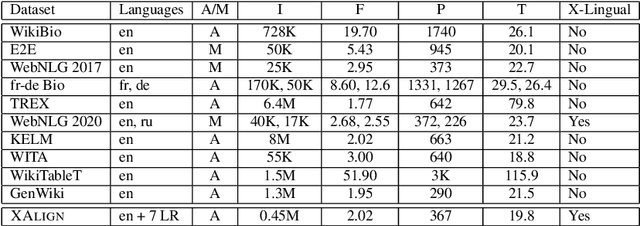
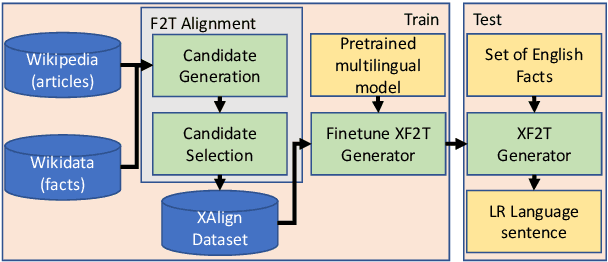
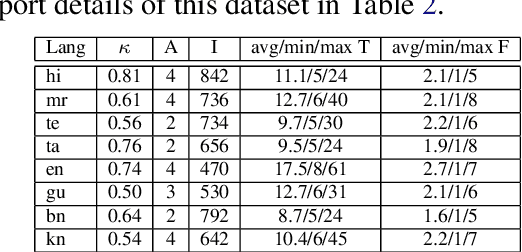
Multiple critical scenarios (like Wikipedia text generation given English Infoboxes) need automated generation of descriptive text in low resource (LR) languages from English fact triples. Previous work has focused on English fact-to-text (F2T) generation. To the best of our knowledge, there has been no previous attempt on cross-lingual alignment or generation for LR languages. Building an effective cross-lingual F2T (XF2T) system requires alignment between English structured facts and LR sentences. We propose two unsupervised methods for cross-lingual alignment. We contribute XALIGN, an XF2T dataset with 0.45M pairs across 8 languages, of which 5402 pairs have been manually annotated. We also train strong baseline XF2T generation models on the XAlign dataset.
Transformer Models for Text Coherence Assessment
Sep 05, 2021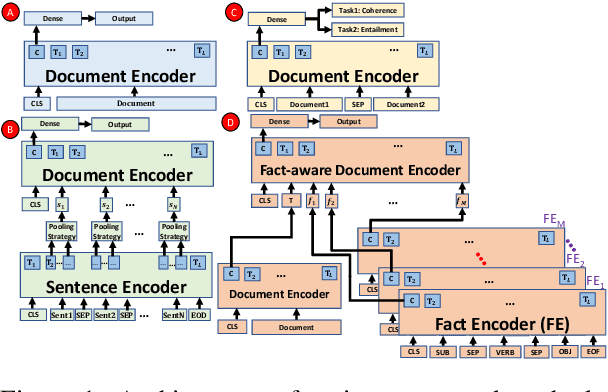

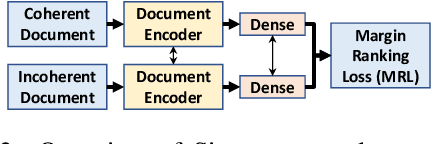
Coherence is an important aspect of text quality and is crucial for ensuring its readability. It is essential desirable for outputs from text generation systems like summarization, question answering, machine translation, question generation, table-to-text, etc. An automated coherence scoring model is also helpful in essay scoring or providing writing feedback. A large body of previous work has leveraged entity-based methods, syntactic patterns, discourse relations, and more recently traditional deep learning architectures for text coherence assessment. Previous work suffers from drawbacks like the inability to handle long-range dependencies, out-of-vocabulary words, or model sequence information. We hypothesize that coherence assessment is a cognitively complex task that requires deeper models and can benefit from other related tasks. Accordingly, in this paper, we propose four different Transformer-based architectures for the task: vanilla Transformer, hierarchical Transformer, multi-task learning-based model, and a model with fact-based input representation. Our experiments with popular benchmark datasets across multiple domains on four different coherence assessment tasks demonstrate that our models achieve state-of-the-art results outperforming existing models by a good margin.