 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Zero-Shot Knowledge Distillation for Natural Language Processing
Dec 31, 2020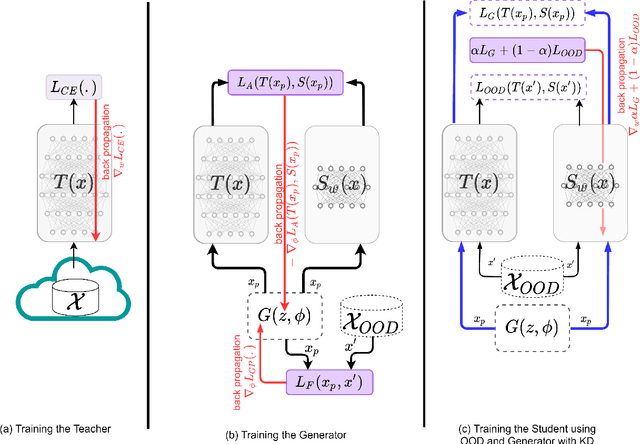
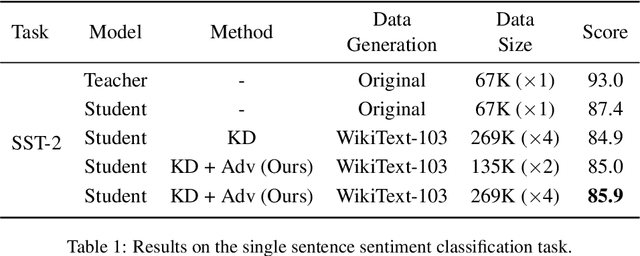
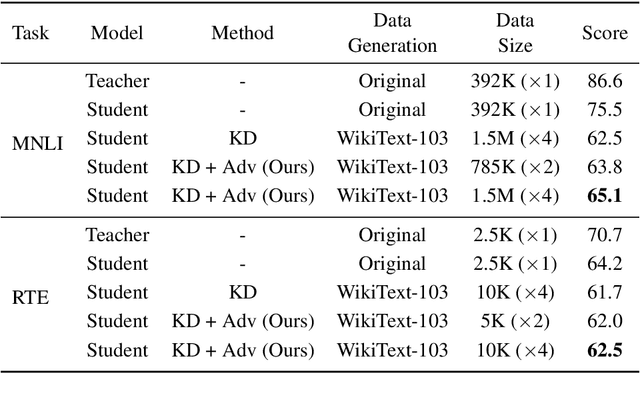
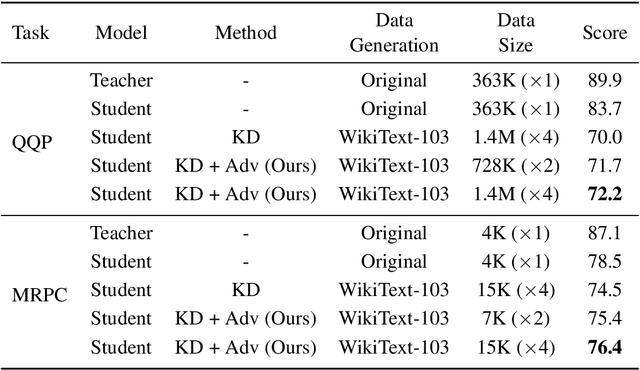
Knowledge Distillation (KD) is a common knowledge transfer algorithm used for model compression across a variety of deep learning based natural language processing (NLP) solutions. In its regular manifestations, KD requires access to the teacher's training data for knowledge transfer to the student network. However, privacy concerns, data regulations and proprietary reasons may prevent access to such data. We present, to the best of our knowledge, the first work on Zero-Shot Knowledge Distillation for NLP, where the student learns from the much larger teacher without any task specific data. Our solution combines out of domain data and adversarial training to learn the teacher's output distribution. We investigate six tasks from the GLUE benchmark and demonstrate that we can achieve between 75% and 92% of the teacher's classification score (accuracy or F1) while compressing the model 30 times.
Mapping Low-Resolution Images To Multiple High-Resolution Images Using Non-Adversarial Mapping
Jun 30, 2020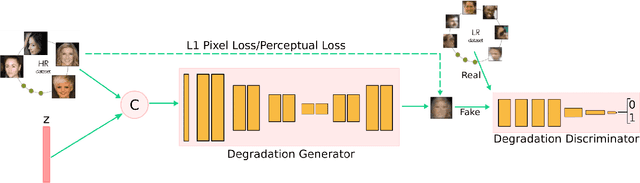
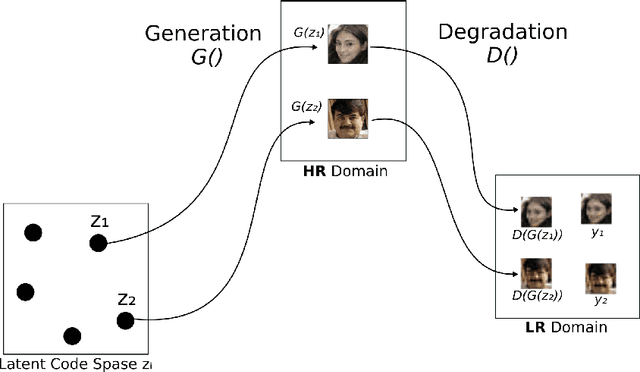

Several methods have recently been proposed for the Single Image Super-Resolution (SISR) problem. The current methods assume that a single low-resolution image can only yield a single high-resolution image. In addition, all of these methods use low-resolution images that were artificially generated through simple bilinear down-sampling. We argue that, first and foremost, the problem of SISR is an one-to-many mapping problem between the low-resolution and all possible candidate high-resolution images and we address the challenging task of learning how to realistically degrade and down-sample high-resolution images. To circumvent this problem, we propose SR-NAM which utilizes the Non-Adversarial Mapping (NAM) technique. Furthermore, we propose a degradation model that learns how to transform high-resolution images to low-resolution images that resemble realistically taken low-resolution photos. Finally, some qualitative results for the proposed method along with the weaknesses of SR-NAM are included.
Time-aware Large Kernel Convolutions
Feb 08, 2020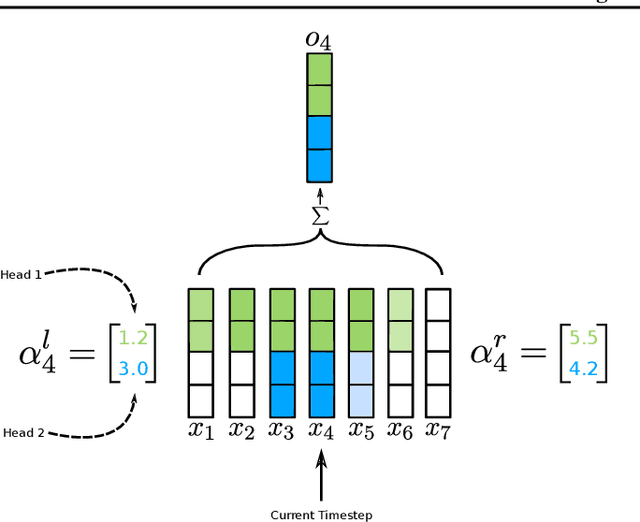

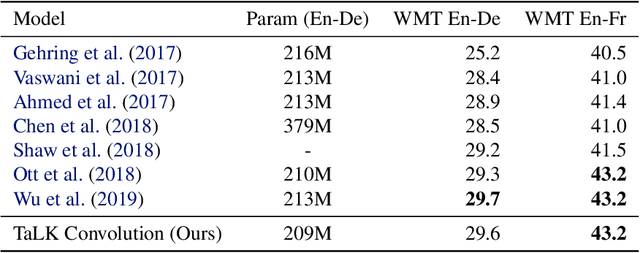
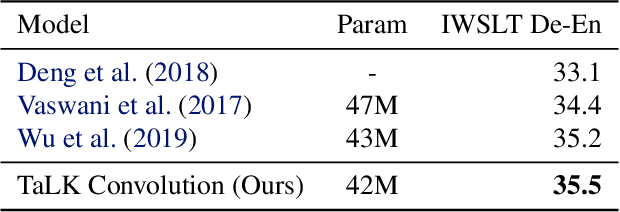
To date, most state-of-the-art sequence modelling architectures use attention to build generative models for language based tasks. Some of these models use all the available sequence tokens to generate an attention distribution which results in time complexity of $O(n^2)$. Alternatively, they utilize depthwise convolutions with softmax normalized kernels of size $k$ acting as a limited-window self-attention, resulting in time complexity of $O(k{\cdot}n)$. In this paper, we introduce Time-aware Large Kernel (TaLK) Convolutions, a novel adaptive convolution operation that learns to predict the size of a summation kernel instead of using the fixed-sized kernel matrix. This method yields a time complexity of $O(n)$, effectively making the sequence encoding process linear to the number of tokens. We evaluate the proposed method on large-scale standard machine translation and language modelling datasets and show that TaLK Convolutions constitute an efficient improvement over other attention/convolution based approaches.
Distilled embedding: non-linear embedding factorization using knowledge distillation
Oct 02, 2019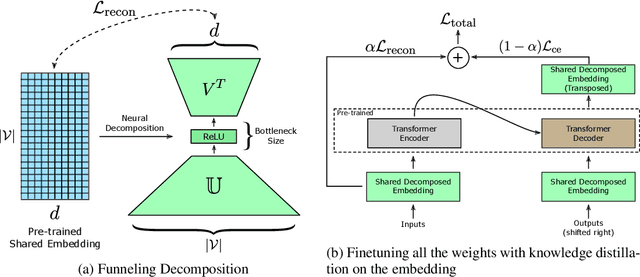
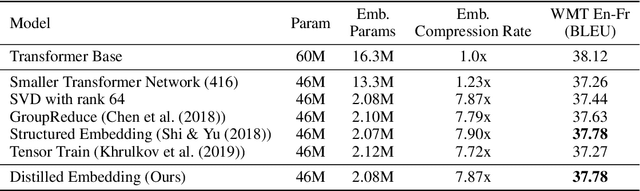
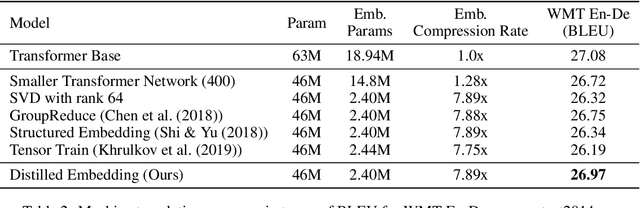
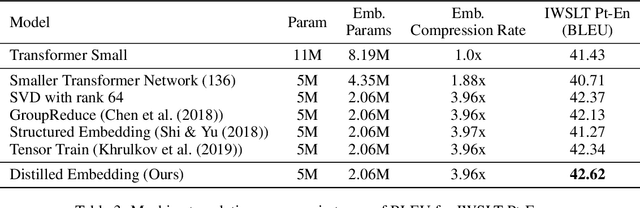
Word-embeddings are a vital component of Natural Language Processing (NLP) systems and have been extensively researched. Better representations of words have come at the cost of huge memory footprints, which has made deploying NLP models on edge-devices challenging due to memory limitations. Compressing embedding matrices without sacrificing model performance is essential for successful commercial edge deployment. In this paper, we propose Distilled Embedding, an (input/output) embedding compression method based on low-rank matrix decomposition with an added non-linearity. First, we initialize the weights of our decomposition by learning to reconstruct the full word-embedding and then fine-tune on the downstream task employing knowledge distillation on the factorized embedding. We conduct extensive experimentation with various compression rates on machine translation, using different data-sets with a shared word-embedding matrix for both embedding and vocabulary projection matrices. We show that the proposed technique outperforms conventional low-rank matrix factorization, and other recently proposed word-embedding matrix compression methods.
Copy this Sentence
May 23, 2019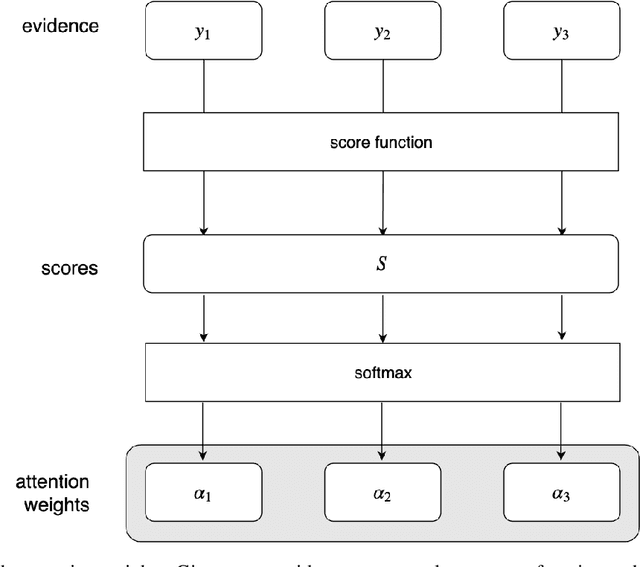

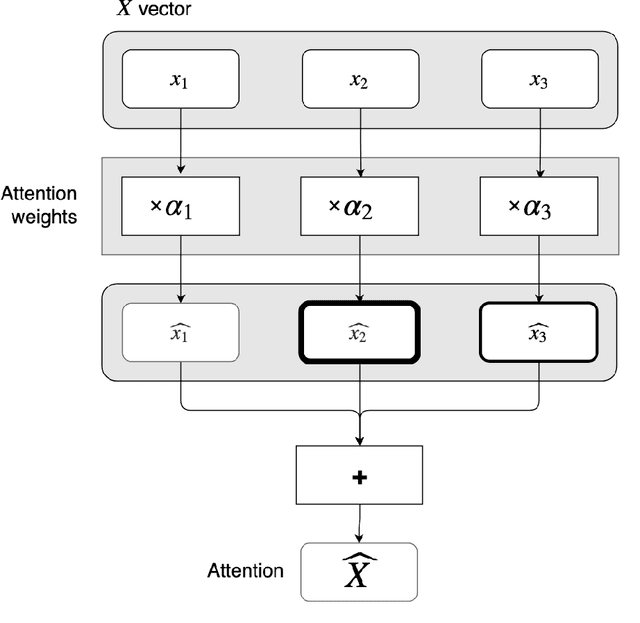
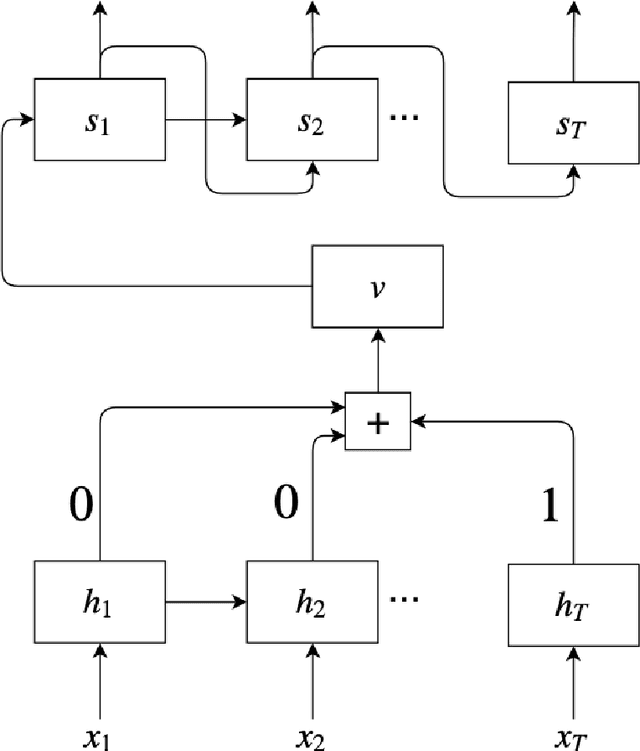
Attention is an operation that selects some largest element from some set, where the notion of largest is defined elsewhere. Applying this operation to sequence to sequence mapping results in significant improvements to the task at hand. In this paper we provide the mathematical definition of attention and examine its application to sequence to sequence models. We highlight the exact correspondences between machine learning implementations of attention and our mathematical definition. We provide clear evidence of effectiveness of attention mechanisms evaluating models with varying degrees of attention on a very simple task: copying a sentence. We find that models that make greater use of attention perform much better on sequence to sequence mapping tasks, converge faster and are more stable.