 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Investigation of Quantum Deep Clustering Framework with Quantum Deep SVM & Convolutional Neural Network Feature Extractor
Sep 21, 2019In this paper, we have proposed a deep quantum SVM formulation, and further demonstrated a quantum-clustering framework based on the quantum deep SVM formulation, deep convolutional neural networks, and quantum K-Means clustering. We have investigated the run time computational complexity of the proposed quantum deep clustering framework and compared with the possible classical implementation. Our investigation shows that the proposed quantum version of deep clustering formulation demonstrates a significant performance gain (exponential speed up gains in many sections) against the possible classical implementation. The proposed theoretical quantum deep clustering framework is also interesting & novel research towards the quantum-classical machine learning formulation to articulate the maximum performance.
Sokoto Coventry Fingerprint Dataset
Jul 24, 2018

This paper presents the Sokoto Coventry Fingerprint Dataset (SOCOFing), a biometric fingerprint database designed for academic research purposes. SOCOFing is made up of 6,000 fingerprint images from 600 African subjects. SOCOFing contains unique attributes such as labels for gender, hand and finger name as well as synthetically altered versions with three different levels of alteration for obliteration, central rotation, and z-cut. The dataset is freely available for noncommercial research purposes at: https://www.kaggle.com/ruizgara/socofing
A Combined CNN and LSTM Model for Arabic Sentiment Analysis
Jul 22, 2018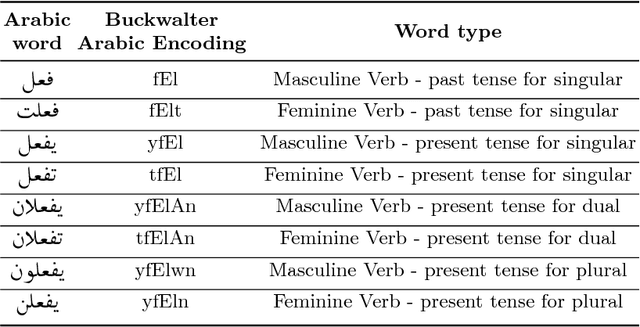
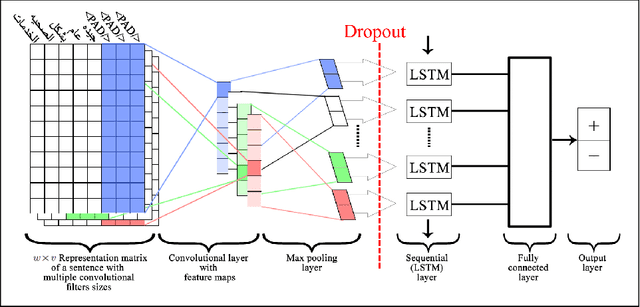
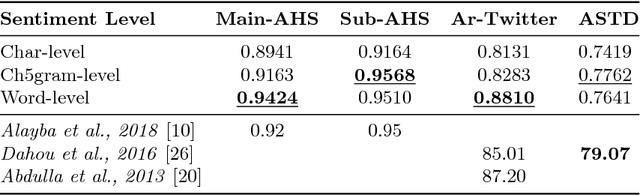
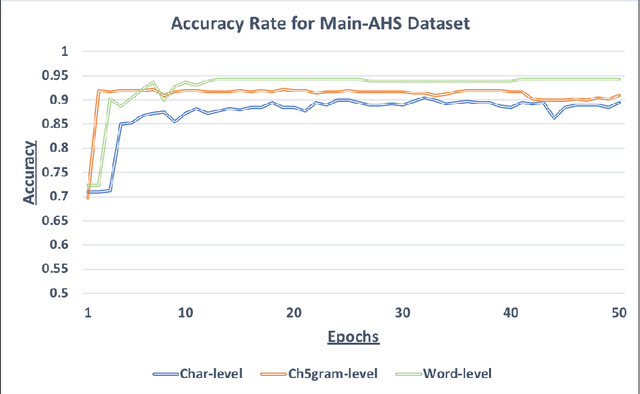
Deep neural networks have shown good data modelling capabilities when dealing with challenging and large datasets from a wide range of application areas. Convolutional Neural Networks (CNNs) offer advantages in selecting good features and Long Short-Term Memory (LSTM) networks have proven good abilities of learning sequential data. Both approaches have been reported to provide improved results in areas such image processing, voice recognition, language translation and other Natural Language Processing (NLP) tasks. Sentiment classification for short text messages from Twitter is a challenging task, and the complexity increases for Arabic language sentiment classification tasks because Arabic is a rich language in morphology. In addition, the availability of accurate pre-processing tools for Arabic is another current limitation, along with limited research available in this area. In this paper, we investigate the benefits of integrating CNNs and LSTMs and report obtained improved accuracy for Arabic sentiment analysis on different datasets. Additionally, we seek to consider the morphological diversity of particular Arabic words by using different sentiment classification levels.
* Authors accepted version of submission for CD-MAKE 2018
An All-Pair Quantum SVM Approach for Big Data Multiclass Classification
May 15, 2018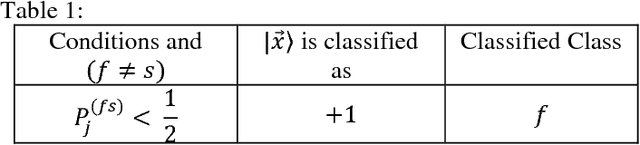
In this paper, we have discussed a quantum approach for the all-pair multiclass classification problem. We have shown that the multiclass support vector machine for big data classification with a quantum all-pair approach can be implemented in logarithm runtime complexity on a quantum computer. In an all-pair approach, there is one binary classification problem for each pair of classes, and so there are k (k-1)/2 classifiers for a k-class problem. As compared to the classical multiclass support vector machine that can be implemented with polynomial run time complexity, our approach exhibits exponential speed up in the quantum version. The quantum all-pair algorithm can be used with other classification algorithms, and a speed up gain can be achieved as compared to their classical counterparts.
Big Data Quantum Support Vector Clustering
Apr 29, 2018Clustering is a complex process in finding the relevant hidden patterns in unlabeled datasets, broadly known as unsupervised learning. Support vector clustering algorithm is a well-known clustering algorithm based on support vector machines and Gaussian kernels. In this paper, we have investigated the support vector clustering algorithm in quantum paradigm. We have developed a quantum algorithm which is based on quantum support vector machine and the quantum kernel (Gaussian kernel and polynomial kernel) formulation. The investigation exhibits approximately exponential speed up in the quantum version with respect to the classical counterpart.
Improving Sentiment Analysis in Arabic Using Word Representation
Mar 30, 2018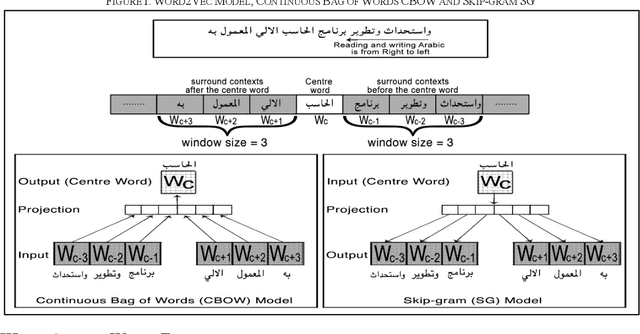
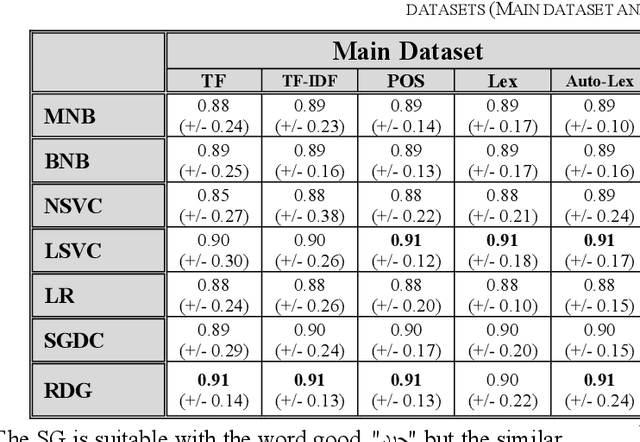
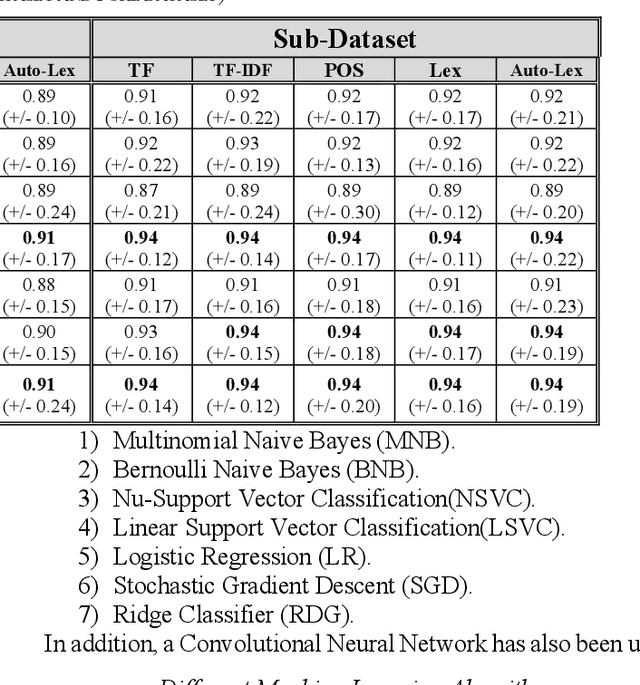
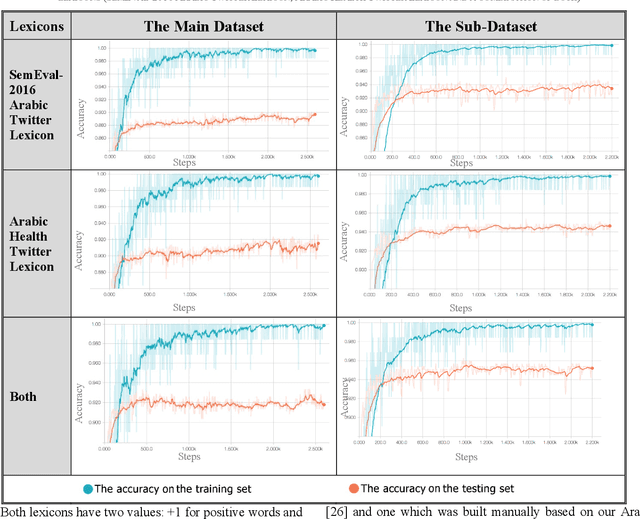
The complexities of Arabic language in morphology, orthography and dialects makes sentiment analysis for Arabic more challenging. Also, text feature extraction from short messages like tweets, in order to gauge the sentiment, makes this task even more difficult. In recent years, deep neural networks were often employed and showed very good results in sentiment classification and natural language processing applications. Word embedding, or word distributing approach, is a current and powerful tool to capture together the closest words from a contextual text. In this paper, we describe how we construct Word2Vec models from a large Arabic corpus obtained from ten newspapers in different Arab countries. By applying different machine learning algorithms and convolutional neural networks with different text feature selections, we report improved accuracy of sentiment classification (91%-95%) on our publicly available Arabic language health sentiment dataset [1]
* Authors accepted version of submission for ASAR 2018
Gaussian Kernel in Quantum Paradigm
Nov 04, 2017Gaussian kernel is a very popular kernel function used in many machine learning algorithms, especially in support vector machines (SVM). For nonlinear training instances in machine learning, it often outperforms polynomial kernels in model accuracy. The Gaussian kernel is heavily used in formulating nonlinear classical SVM. A very elegant quantum version of least square support vector machine which is exponentially faster than the classical counterparts was discussed in literature with quantum polynomial kernel. In this paper, we have demonstrated a quantum version of the Gaussian kernel and analyzed its complexity, which is O(\epsilon^(-1)logN) with N-dimensional instances and an accuracy \epsilon. The Gaussian kernel is not only more efficient than polynomial kernel but also has broader application range than polynomial kernel.
A glass-box interactive machine learning approach for solving NP-hard problems with the human-in-the-loop
Aug 03, 2017

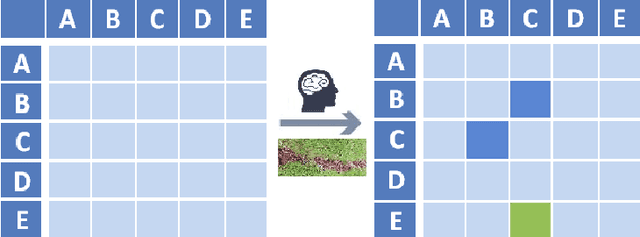
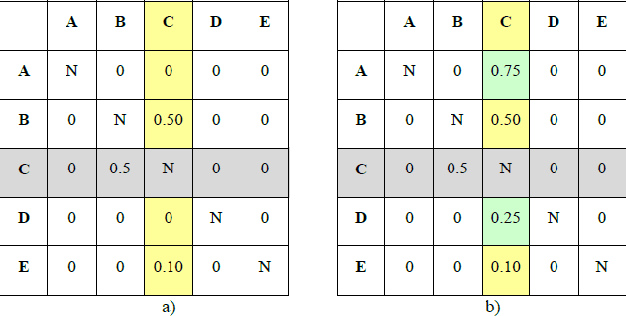
The goal of Machine Learning to automatically learn from data, extract knowledge and to make decisions without any human intervention. Such automatic (aML) approaches show impressive success. Recent results even demonstrate intriguingly that deep learning applied for automatic classification of skin lesions is on par with the performance of dermatologists, yet outperforms the average. As human perception is inherently limited, such approaches can discover patterns, e.g. that two objects are similar, in arbitrarily high-dimensional spaces what no human is able to do. Humans can deal only with limited amounts of data, whilst big data is beneficial for aML; however, in health informatics, we are often confronted with a small number of data sets, where aML suffer of insufficient training samples and many problems are computationally hard. Here, interactive machine learning (iML) may be of help, where a human-in-the-loop contributes to reduce the complexity of NP-hard problems. A further motivation for iML is that standard black-box approaches lack transparency, hence do not foster trust and acceptance of ML among end-users. Rising legal and privacy aspects, e.g. with the new European General Data Protection Regulations, make black-box approaches difficult to use, because they often are not able to explain why a decision has been made. In this paper, we present some experiments to demonstrate the effectiveness of the human-in-the-loop approach, particularly in opening the black-box to a glass-box and thus enabling a human directly to interact with an learning algorithm. We selected the Ant Colony Optimization framework, and applied it on the Traveling Salesman Problem, which is a good example, due to its relevance for health informatics, e.g. for the study of protein folding. From studies of how humans extract so much from so little data, fundamental ML-research also may benefit.
Proposal for the creation of a research facility for the development of the SP machine
Aug 19, 2015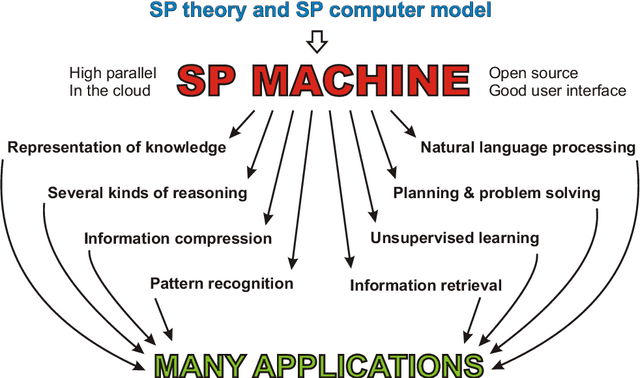
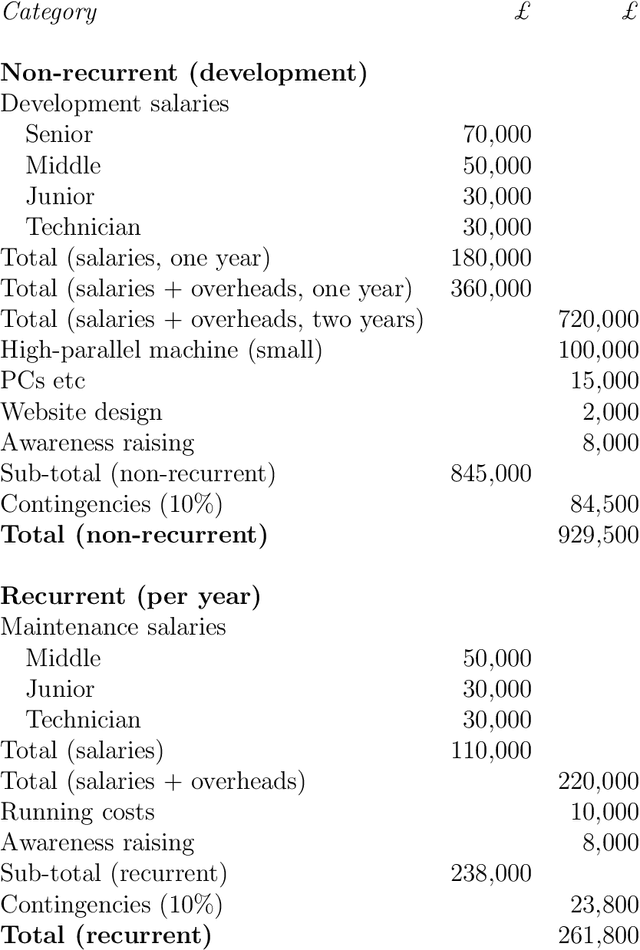

This is a proposal to create a research facility for the development of a high-parallel version of the "SP machine", based on the "SP theory of intelligence". We envisage that the new version of the SP machine will be an open-source software virtual machine, derived from the existing "SP computer model", and hosted on an existing high-performance computer. It will be a means for researchers everywhere to explore what can be done with the system and to create new versions of it. The SP system is a unique attempt to simplify and integrate observations and concepts across artificial intelligence, mainstream computing, mathematics, and human perception and cognition, with information compression as a unifying theme. Potential benefits and applications include helping to solve problems associated with big data; facilitating the development of autonomous robots; unsupervised learning, natural language processing, several kinds of reasoning, fuzzy pattern recognition at multiple levels of abstraction, computer vision, best-match and semantic forms of information retrieval, software engineering, medical diagnosis, simplification of computing systems, and the seamless integration of diverse kinds of knowledge and diverse aspects of intelligence. Additional motivations include the potential of the SP system to help solve problems in defence, security, and the detection and prevention of crime; potential in terms of economic, social, environmental, and academic criteria, and in terms of publicity; and the potential for international influence in research. The main elements of the proposed facility are described, including support for the development of "SP-neural", a neural version of the SP machine. The facility should be permanent in the sense that it should be available for the foreseeable future, and it should be designed to facilitate its use by researchers anywhere in the world.
Random Drift Particle Swarm Optimization
Jun 12, 2013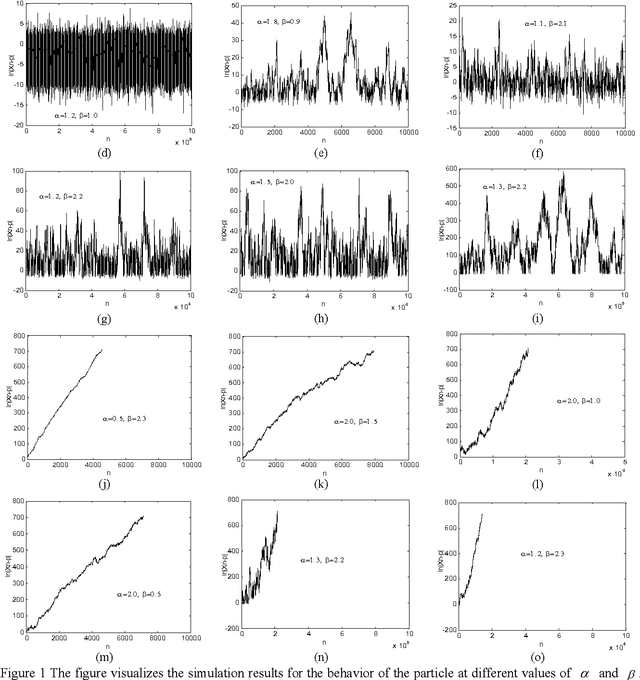
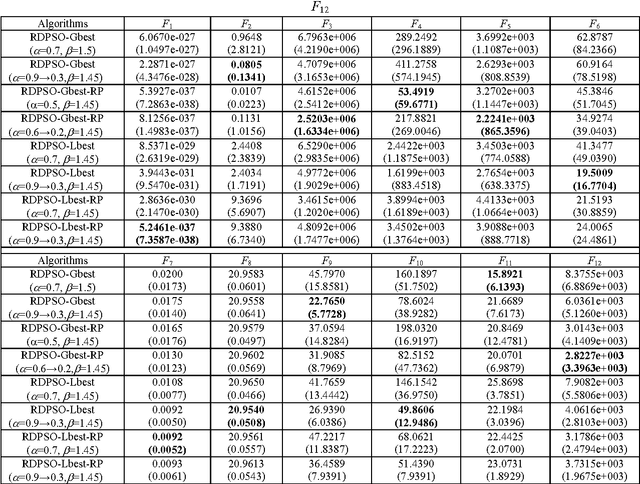
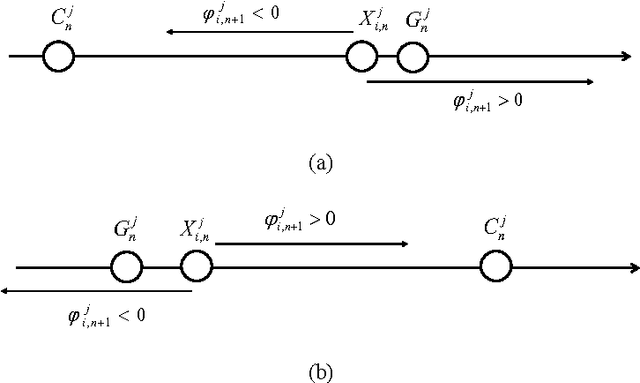
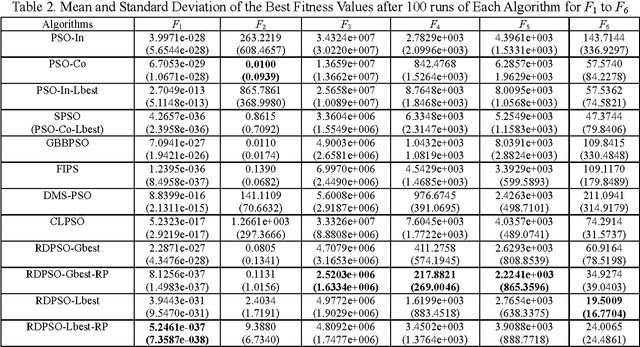
The random drift particle swarm optimization (RDPSO) algorithm, inspired by the free electron model in metal conductors placed in an external electric field, is presented, systematically analyzed and empirically studied in this paper. The free electron model considers that electrons have both a thermal and a drift motion in a conductor that is placed in an external electric field. The motivation of the RDPSO algorithm is described first, and the velocity equation of the particle is designed by simulating the thermal motion as well as the drift motion of the electrons, both of which lead the electrons to a location with minimum potential energy in the external electric field. Then, a comprehensive analysis of the algorithm is made, in order to provide a deep insight into how the RDPSO algorithm works. It involves a theoretical analysis and the simulation of the stochastic dynamical behavior of a single particle in the RDPSO algorithm. The search behavior of the algorithm itself is also investigated in detail, by analyzing the interaction between the particles. Some variants of the RDPSO algorithm are proposed by incorporating different random velocity components with different neighborhood topologies. Finally, empirical studies on the RDPSO algorithm are performed by using a set of benchmark functions from the CEC2005 benchmark suite. Based on the theoretical analysis of the particle's behavior, two methods of controlling the algorithmic parameters are employed, followed by an experimental analysis on how to select the parameter values, in order to obtain a good overall performance of the RDPSO algorithm and its variants in real-world applications. A further performance comparison between the RDPSO algorithms and other variants of PSO is made to prove the efficiency of the RDPSO algorithms.