 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmentation techniques for video surveillance in the visible and thermal spectral range
Jun 11, 2026In intelligent video surveillance, cameras record image sequences during day and night. Commonly, this demands different sensors. To achieve a better performance it is not unusual to combine them. We focus on the case that a long-wave infrared camera records continuously and in addition to this, another camera records in the visible spectral range during daytime and an intelligent algorithm supervises the picked up imagery. More accurate, our task is multispectral CNN-based object detection. At first glance, images originating from the visible spectral range differ between thermal infrared ones in the presence of color and distinct texture information on the one hand and in not containing information about thermal radiation that emits from objects on the other hand. Although color can provide valuable information for classification tasks, effects such as varying illumination and specialties of different sensors still represent significant problems. Anyway, obtaining sufficient and practical thermal infrared datasets for training a deep neural network poses still a challenge. That is the reason why training with the help of data from the visible spectral range could be advantageous, particularly if the data, which has to be evaluated contains both visible and infrared data. However, there is no clear evidence of how strongly variations in thermal radiation, shape, or color information influence classification accuracy. To gain deeper insight into how Convolutional Neural Networks make decisions and what they learn from different sensor input data, we investigate the suitability and robustness of different augmentation techniques...
* 8 pages
Evaluating Explainability in Safety-Critical ATR Systems: Limitations of Post-Hoc Methods and Paths Toward Robust XAI
May 07, 2026Explainable Artificial Intelligence (XAI) is increasingly rec ognized as essential for deploying machine learning systems in safety critical environments. In Automatic Target Recognition (ATR), where models operate on image, video, radar, and multisensor data, high pre dictive performance alone is insufficient. Model decisions must also be interpretable, reliable, and suitable for validation. This paper presents a structured evaluation of explainability methods in the context of safety-critical ATR systems: We identify major XAI paradigms, including saliency-based, attention-based, and surrogate ap proaches, as well as recent detection-aware extensions. Based on this, we formalize explainability as an assurance-oriented assessment problem, introduce a taxonomy, and assess these methods with respect to four key dimensions: interpretability, robustness, vulnerability to manipula tion, and suitability for validation and verification. The analysis identifies systematic limitations of current post-hoc explanation methods. In par ticular, we derive critical failure modes such as spurious explanations, instability under perturbations, and overtrust induced by visually con vincing outputs. These findings indicate that widely used XAI techniques may be insufficient for safety-critical deployment. Finally, we discuss implications for ATR systems and outline directions toward more robust, causally grounded, and physically informed explain ability methods. Our results emphasize the need to move beyond visually plausible explanations toward approaches that support reliable decision making and system-level assurance.
Analysis of Explainers of Black Box Deep Neural Networks for Computer Vision: A Survey
Nov 27, 2019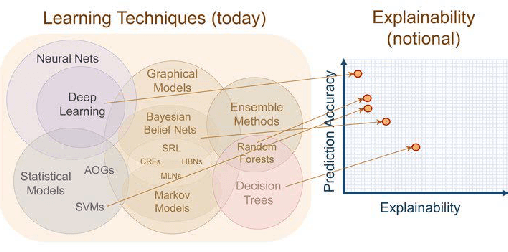



Deep Learning is a state-of-the-art technique to make inference on extensive or complex data. As a black box model due to their multilayer nonlinear structure, Deep Neural Networks are often criticized to be non-transparent and their predictions not traceable by humans. Furthermore, the models learn from artificial datasets, often with bias or contaminated discriminating content. Through their increased distribution, decision-making algorithms can contribute promoting prejudge and unfairness which is not easy to notice due to lack of transparency. Hence, scientists developed several so-called explanators or explainers which try to point out the connection between input and output to represent in a simplified way the inner structure of machine learning black boxes. In this survey we differ the mechanisms and properties of explaining systems for Deep Neural Networks for Computer Vision tasks. We give a comprehensive overview about taxonomy of related studies and compare several survey papers that deal with explainability in general. We work out the drawbacks and gaps and summarize further research ideas.