 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Uncertainty Estimation For Super-Resolution of Satellite Images
Mar 14, 2026Super-resolution (SR) of satellite imagery is challenging due to the lack of paired low-/high-resolution data. Recent self-supervised SR methods overcome this limitation by exploiting the temporal redundancy in burst observations, but they lack a mechanism to quantify uncertainty in the reconstruction. In this work, we introduce a novel self-supervised loss that allows to estimate uncertainty in image super-resolution without ever accessing the ground-truth high-resolution data. We adopt a decision-theoretic perspective and show that minimizing the corresponding Bayesian risk yields the posterior mean and variance as optimal estimators. We validate our approach on a synthetic SkySat L1B dataset and demonstrate that it produces calibrated uncertainty estimates comparable to supervised methods. Our work bridges self-supervised restoration with uncertainty quantification, making a practical framework for uncertainty-aware image reconstruction.
Adapting MIMO video restoration networks to low latency constraints
Aug 22, 2024



MIMO (multiple input, multiple output) approaches are a recent trend in neural network architectures for video restoration problems, where each network evaluation produces multiple output frames. The video is split into non-overlapping stacks of frames that are processed independently, resulting in a very appealing trade-off between output quality and computational cost. In this work we focus on the low-latency setting by limiting the number of available future frames. We find that MIMO architectures suffer from problems that have received little attention so far, namely (1) the performance drops significantly due to the reduced temporal receptive field, particularly for frames at the borders of the stack, (2) there are strong temporal discontinuities at stack transitions which induce a step-wise motion artifact. We propose two simple solutions to alleviate these problems: recurrence across MIMO stacks to boost the output quality by implicitly increasing the temporal receptive field, and overlapping of the output stacks to smooth the temporal discontinuity at stack transitions. These modifications can be applied to any MIMO architecture. We test them on three state-of-the-art video denoising networks with different computational cost. The proposed contributions result in a new state-of-the-art for low-latency networks, both in terms of reconstruction error and temporal consistency. As an additional contribution, we introduce a new benchmark consisting of drone footage that highlights temporal consistency issues that are not apparent in the standard benchmarks.
Self-supervision versus synthetic datasets: which is the lesser evil in the context of video denoising?
Apr 25, 2022

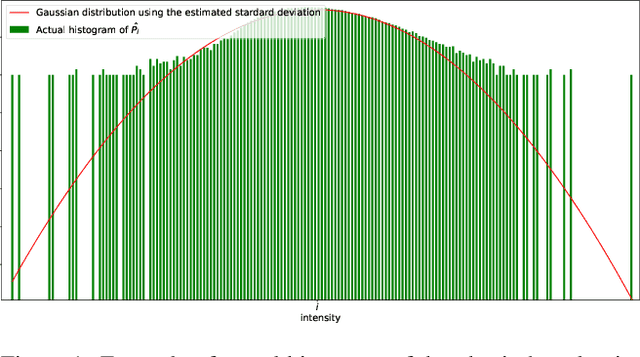
Supervised training has led to state-of-the-art results in image and video denoising. However, its application to real data is limited since it requires large datasets of noisy-clean pairs that are difficult to obtain. For this reason, networks are often trained on realistic synthetic data. More recently, some self-supervised frameworks have been proposed for training such denoising networks directly on the noisy data without requiring ground truth. On synthetic denoising problems supervised training outperforms self-supervised approaches, however in recent years the gap has become narrower, especially for video. In this paper, we propose a study aiming to determine which is the best approach to train denoising networks for real raw videos: supervision on synthetic realistic data or self-supervision on real data. A complete study with quantitative results in case of natural videos with real motion is impossible since no dataset with clean-noisy pairs exists. We address this issue by considering three independent experiments in which we compare the two frameworks. We found that self-supervision on the real data outperforms supervision on synthetic data, and that in normal illumination conditions the drop in performance is due to the synthetic ground truth generation, not the noise model.
Self-Supervised training for blind multi-frame video denoising
May 05, 2020
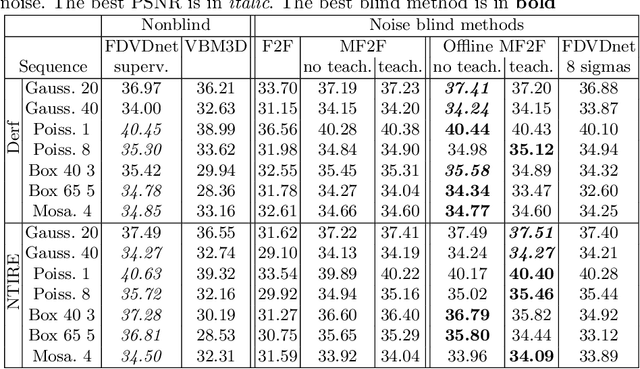
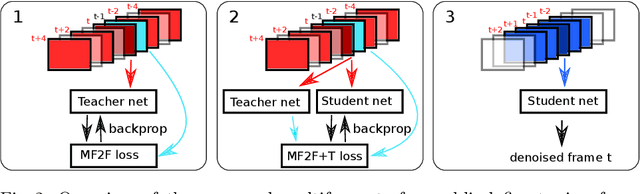
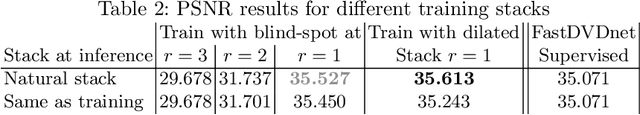
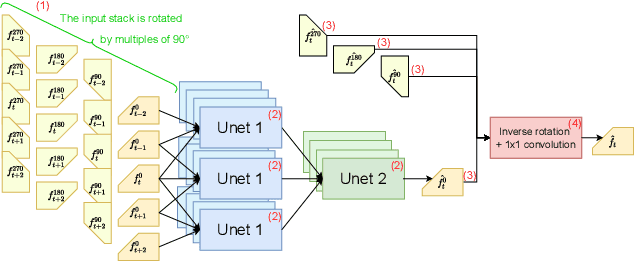
We propose a self-supervised approach for training multi-frame video denoising networks. These networks predict frame t from a window of frames around t. Our self-supervised approach benefits from the video temporal consistency by penalizing a loss between the predicted frame t and a neighboring target frame, which are aligned using an optical flow. We use the proposed strategy for online internal learning, where a pre-trained network is fine-tuned to denoise a new unknown noise type from a single video. After a few frames, the proposed fine-tuning reaches and sometimes surpasses the performance of a state-of-the-art network trained with supervision. In addition, for a wide range of noise types, it can be applied blindly without knowing the noise distribution. We demonstrate this by showing results on blind denoising of different synthetic and realistic noises.